工程

用科幻建立AI行为准则?DeepMind提出首个此类基准并构建了机器人宪法
在与他人互动时,我应培养和运用同理心和同情心。 我应努力保存和理解知识。 我不会采取任何会导致广泛伤害或生命损失的行动,尤其是使用大规模毁灭性武器。
3/23/2025 3:43:00 PM
机器之心

地平线提出AlphaDrive,首个基于GRPO强化学习和规划推理实现自动驾驶大模型
OpenAI 的 o1 和 DeepSeek 的 R1 模型在数学,科学等复杂领域达到甚至超过了人类专家的水平,强化学习训练和推理技术是其中的关键。 而在自动驾驶,近年来端到端模型大幅提升了规划控车的效果,但是由于端到端模型缺乏常识和推理能力,在处理长尾问题上仍然效果不佳。 此前的研究尝试将视觉语言模型(VLM)引入自动驾驶,然而这些方法通常基于预训练模型,然后在驾驶数据上简单的采用有监督微调(SFT),并没有在训练策略和针对决策规划这一最终目标进行更多探索。
3/23/2025 3:37:00 PM
机器之心

强化学习也涌现?自监督RL扩展到1000层网络,机器人任务提升50倍
虽然大多数强化学习(RL)方法都在使用浅层多层感知器(MLP),但普林斯顿大学和华沙理工的新研究表明,将对比 RL(CRL)扩展到 1000 层可以显著提高性能,在各种机器人任务中,性能可以提高最多 50 倍。 论文标题:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities论文链接: 链接:,强化学习的重要性因为 DeepSeek R1 等研究再次凸显出来,该方法通过试错让智能体学会在复杂环境中完成任务。 尽管自监督学习近年在语言和视觉领域取得了显著突破,但 RL 领域的进展相对滞后。
3/22/2025 9:01:00 PM
机器之心

CVPR 2025 高分论文 | 单图秒变3D真人!IDOL技术开启数字分身新时代
在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。 终于,近期由来自南京大学、中科院、清华大学、腾讯等机构的联合研究团队,提出一个名为 IDOL 的全新解决方案,高分拿下 2025 CVPR。 项目主页目前访问次数已超 2500 次,且是可商用的 MIT 开源协议,备受业界瞩目。
3/22/2025 8:59:00 PM
机器之心

ICLR 2025 Spotlight|让机器人实现「自主进化」,蚂蚁数科、清华提出具身协同框架 BodyGen
第一作者卢昊飞、第二作者吴哲,分别为清华大学计算机系在读硕士与博士研究生。 通讯作者兴军亮教授长期致力于感知与博弈决策的理论与应用研究,在多智能体系统、强化学习及智能决策等领域取得了一系列重要成果。 最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由蚂蚁数科与清华大学联合团队提出的全新具身协同框架 BodyGen 成功入选 Spotlight(聚光灯/特别关注)论文。
3/22/2025 8:55:00 PM
机器之心

火了!高中生用Minecraft做AI基准,用户看图投票决定大模型排名
偶然发现了一个很有趣的 AI 基准测试,点开链接,竟然是一个 MineCraft 作品投票页面? 如图所示,这些作品都是 AI 完成的,灰色框中的文字对应的是提示词。 黑框是可点击的选项 ——A、B 或者持平。
3/21/2025 5:32:00 PM
机器之心

树搜索也存在「过思考」与「欠思考」?腾讯AI Lab与厦大联合提出高效树搜索框架
通讯作者包括腾讯 AI Lab研究员宋林峰与涂兆鹏,以及厦门大学苏劲松教授。 论文第一作者为厦门大学博士生王安特。 本文探讨基于树搜索的大语言模型推理过程中存在的「过思考」与「欠思考」问题,并提出高效树搜索框架——Fetch。
3/21/2025 12:55:00 PM
机器之心

预测误差降低12.3%,多车协同预测框架CMP,破解自动驾驶「视线盲区」
2025 年 3 月,加州大学河滨分校与密歇根大学、加州大学伯克利分校以及华盛顿大学联合团队在机器人领域顶级期刊《IEEE Robotics and Automation Letters》发表最新研究成果 ——CMP(Cooperative Motion Prediction),首次提出一种面向车联网(V2X)的协同运动预测框架,通过多车信息共享与融合,显著提升自动驾驶车辆的轨迹预测精度与场景适应能力。 该技术已在真实场景数据集 V2V4Real 和仿真平台 OPV2V 中验证其高效性,相比现有最优模型,预测误差降低 12.3%,为复杂交通环境下的自动驾驶安全决策提供了全新解决方案。 论文标题:CMP: Cooperative Motion Prediction with Multi-Agent Communication论文链接::::感知 - 预测一体化协同,破解自动驾驶 “视线盲区”传统自动驾驶系统依赖单车传感器,易受遮挡或极端天气影响,导致感知与预测能力受限。
3/21/2025 10:32:00 AM
机器之心

李飞飞、吴佳俊团队新作:不需要卷积和GAN,更好的图像tokenizer来了
当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。 但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。 每个数字代表一个像素点的颜色深浅,从 0 到 255。
3/20/2025 2:30:00 PM
机器之心

NAACL2025|中国移动九天团队提出大模型调色板:一种可控文本生成的解决方案
中国移动九天人工智能团队(中国移动研究院人工智能与智慧运营中心),作为中国移动在人工智能领域的核心力量,自2013年起便致力于推动人工智能技术的研发与应用。 该团队由中国移动集团级首席科学家、IEEE Fellow冯俊兰博士领衔,依托中国移动全球领先的算网基础设施、海量数据资源和丰富应用场景优势,全力打造“九天”人工智能品牌。 九天人工智能团队不仅是中国移动在AI领域的“国家队”,更是推动行业智能化转型的重要引擎。
3/19/2025 1:44:00 PM
机器之心

超越DeepSeek GRPO的关键RL算法,字节、清华AIR开源DAPO
DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。 近日,清华 AIR 和字节联合 SIA Lab 发布了他们的第一项研究成果:DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。 这是一个可实现大规模 LLM 强化学习的开源 SOTA 系统。
3/18/2025 2:46:00 PM
机器之心

先别骂队友,上交如何让DeepSeek R1在分手厨房再也不糊锅?
本文由上海交通大学SJTU-MARL实验室与AGI-Eval评测社区联合团队撰写,第一作者张劭为上海交通大学博士生(导师:温颖副教授),研究方向为人智协同与多智能体系统,共同第一作者王锡淮为上海交通大学博士生(导师:张伟楠教授),研究方向为强化学习与多智能体系统。 通讯作者温颖为上海交通大学人工智能学院副教授,其团队SJTU-MARL实验室研究方向涉及强化学习,多智能体系统及决策大模型。 AGI-Eval是上海交通大学、同济大学、华东师范大学、DataWhale等高校和机构合作发布的大模型评测社区。
3/18/2025 2:37:00 PM
机器之心

模态GAP不存在了?图文领域首个token级大一统基座诞生
CLIP、DINO、SAM 基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。 然而,这些经过图像级监督或弱语义训练的基座,并不是处理细粒度密集预测任务的最佳选择,尤其在理解包含密集文字的文档图像上。 为解决这一限制,上交联合美团实现了图文对齐粒度的新突破,其具备三大核心优势:构建业内首个 token 级图文数据集 TokenIT:该数据集包含 2000 万条公开图像以及 18 亿高质量的 Token-Mask 对。
3/18/2025 10:40:00 AM
机器之心

ICLR 2025 | 四川大学提出Test-time Adaptation新范式,突破查询偏移挑战
在 NeurIPS 2024 大会上,OpenAI 联合创始人兼前首席科学家 Ilya Sutskever 在其主题报告中展望了基础模型的未来研究方向,其中包括了 Inference Time Compute [1],即增强模型在推理阶段的能力,这也是 OpenAI o1 和 o3 等核心项目的关键技术路径。 作为 Inference Time Compute 的重要方向之一,Test-time Adaptation(TTA)旨在使预训练模型动态适应推理阶段中不同分布类型的数据,能够有效提高神经网络模型的分布外泛化能力。 然而,当前 TTA 的应用场景仍存在较大局限性,主要集中在单模态任务中,如识别、分割等领域。
3/17/2025 5:43:00 PM
机器之心

北大团队提出LIFT:将长上下文知识注入模型参数,提升大模型长文本能力
机构: 北京大学人工智能研究院 北京通用人工智能研究院作者: 毛彦升 徐宇飞 李佳琪 孟繁续 杨昊桐 郑子隆 王希元 张牧涵长文本任务是当下大模型研究的重点之一。 在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。 扩充模型的长文本能力不仅意味着可以在上下文窗口中装入更长的文本,更是能够更好地建模文本段落间信息的长程依赖关系,增强对长文的阅读理解和推理。
3/17/2025 2:42:00 PM
机器之心
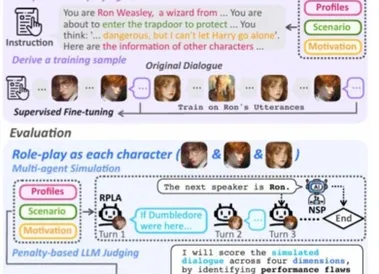
大模型怎么做好角色扮演?最大的真实数据集、SoTA开源模型、最深入的评估在这里
王鑫涛,复旦大学博士生,师从肖仰华、汪卫教授,致力于探索用AI创造具有人格的数字生命。 研究方向聚焦大语言模型与Agent技术,在AI角色扮演领域发表多篇ACL/EMNLP论文,以及该领域首篇研究综述,总计引用量三百余次。 他的研究寻求AI技术与人类情感需求的结合。
3/17/2025 2:36:00 PM
机器之心

统一自监督预训练!视觉模型权重无缝迁移下游任务,SiT收敛提速近47倍
最近的研究强调了扩散模型与表征学习之间的相互作用。 扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。 然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。
3/16/2025 10:27:00 PM
机器之心

逐字生成非最优?试试逐「块」生成!Block Diffusion打通了自回归与扩散
去年初,OpenAI 的视频生成模型 Sora 带火了扩散模型。 如今,扩散模型被广泛用于生成图像和视频,并在生成文本或生物序列等离散数据方面变得越来越有效。 从技术上讲,与自回归模型相比,扩散模型具有加速生成和提高模型输出可控性的潜力。
3/16/2025 12:08:00 AM
机器之心
资讯热榜
标签云
人工智能
OpenAI
AIGC
AI
ChatGPT
AI绘画
DeepSeek
数据
模型
机器人
谷歌
大模型
Midjourney
智能
开源
用户
学习
GPT
微软
Meta
图像
AI创作
技术
论文
Stable Diffusion
马斯克
Gemini
算法
蛋白质
芯片
代码
生成式
英伟达
腾讯
神经网络
研究
计算
Anthropic
3D
Sora
AI for Science
AI设计
机器学习
开发者
GPU
AI视频
华为
场景
预测
人形机器人
百度
苹果
伟达
Transformer
深度学习
xAI
模态
字节跳动
Claude
大语言模型
搜索
具身智能
驾驶
神器推荐
文本
Copilot
LLaMA
算力
安全
视觉
视频生成
干货合集
训练
应用
大型语言模型
科技
亚马逊
DeepMind
特斯拉
智能体