工程
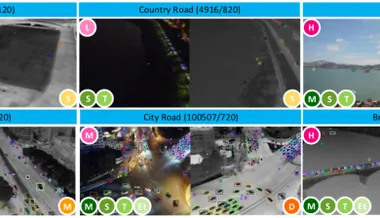
TPAMI 2025 | 国防科大提出RGBT-Tiny数据集与SAFit指标,推动小目标检测技术发展
项目地址::、自动驾驶、夜间搜救等场景中,小目标检测(如远处行人、微型无人机)一直是技术难点——目标尺寸小、背景干扰多、光照条件复杂。 现有数据集多聚焦单一模态(可见光或红外成像),且目标尺寸偏大、场景单一,难以满足实际需求,针对可见光-红外双模态(Visible-Thermal, RGBT)小目标检测的研究却鲜有突破。 为了填补这一空白,国防科技大学团队最新发布RGBT-Tiny基准数据集和SAFit评价指标,填补领域空白,为RGBT小目标检测提供了一个全新的基准和评估工具。
4/1/2025 2:43:00 PM
新闻助手

在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。 不同于 PPO(近端策略优化),GRPO 是直接根据组分数估计基线,因此消除了对 critic 模型的需求。 但是,这又需要为每个问题都采样一组完成结果,进而让训练过程的计算成本较高。
4/1/2025 11:54:00 AM
机器之心

ICLR 2025 Oral | IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。 据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%论文链接:::::不同于现阶段使用 MoE 架构的原始动机,ChartMoE 的目标不是扩展模型的容量,而是探究 MoE 这种 Sparse 结构在下游任务上的应用,通过对齐任务来增强模型对图表的理解能力,同时保持在其他通用任务上的性能。 不同于之前依赖 ramdom 或 co-upcycle 初始化的方法,ChartMoE 利用多样的对齐任务进行专家初始化。
4/1/2025 11:49:00 AM
机器之心

一站式解决Deepseek微调三大痛点:数据集、GPU资源、微调手册与源码
1.Deepseek微调痛点Deepseek模型微调是提升在行业领域表现的关键,但你是否被这些问题卡住? 数据集:不知道如何准备,担心数据泄露? GPU算力:算力不足,Deepseek不同模型尺寸对应的GPU配置选择一头雾水?
3/31/2025 5:10:00 PM
九章云极DataCanvas

清华朱军团队 | 从点云到高保真三维网格:DeepMesh突破自回归生成瓶颈
论文有三位共同一作。 赵若雯,清华大学一年级硕士生,主要研究生成模型、强化学习和具身智能,已在ICRA等会议发表论文。 叶俊良,清华大学二年级硕士生,专注于3D生成和基于人类偏好的多模态强化学习研究,曾以第一作者身份在ECCV发表DreamReward,该成果能生成更符合人类偏好的3D资产。
3/31/2025 1:00:00 PM
机器之心

200美金,人人可手搓QwQ,清华、蚂蚁开源极速RL框架AReaL-boba
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。 然而,针对大语言模型的大规模强化学习训练门槛一直很高:流程复杂、涉及模块多(生成、训练、奖励判定等),为实现高效稳定的分布式训练带来很多挑战;R1/o1 类推理模型的输出长度很长(超过 10K),并且随着训练持续变化,很容易造成显存和效率瓶颈;开源社区缺乏高质量强化学习训练数据,以及完整可复现的训练流程。 本周,蚂蚁技术研究院和清华大学交叉信息院吴翼团队,联合发布了训练速度最快最稳定的开源强化学习训练框架 AReaL(Ant Reasoning RL),并公开全部数据和完成可复现的训练脚本。
3/31/2025 10:52:00 AM
机器之心

ICLR 2025 | 真正「Deep」的「Research」,通过强化学习实现可自主进化的科研智能体来了!
CycleResearcher 研究团队成员包括:张岳教授,西湖大学人工智能系教授,工学院副院长,其指导的博士生朱敏郡、张鸿博、鲍光胜、访问学生翁诣轩;UCL 访问研究员杨林易博士,25 Fall 入职南方科技大学拟任独立 PI,博士生导师,研究员。 AI 技术不断进步,科研自动化浪潮正在深刻改变学术世界! 近日,来自西湖大学、UCL 等机构的研究团队在自动化科研方向发布了一项突破性的成果:CycleResearcher 。
3/31/2025 10:47:00 AM
机器之心

模型调优无需标注数据!将Llama 3.3 70B直接提升到GPT-4o水平
现阶段,微调大型语言模型(LLMs)的难点在于,人们通常没有高质量的标注数据。 最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。 更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
3/30/2025 5:21:00 PM
机器之心
卷积网络又双叒叕行了?OverLoCK:一种仿生的卷积神经网络视觉基础模型
作者是香港大学俞益洲教授与博士生娄蒙。 你是否注意过人类观察世界的独特方式? 当面对复杂场景时,我们往往先快速获得整体印象,再聚焦关键细节。
3/30/2025 5:18:00 PM
机器之心

CVPR 2025 | EmoEdit:情感可编辑?深大VCC带你见证魔法!
EmoEdit 由深圳大学可视计算研究中心黄惠教授课题组完成,第一作者为杨景媛助理教授。 深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。 中心主任黄惠为深圳大学讲席教授、计算机学科带头人、计算机与软件学院院长。
3/30/2025 5:11:00 PM
机器之心

CVPR 2025高分论文:从照片重建3D矢量,告别模糊渲染,重建边缘更清晰
三维高斯泼溅(3D Gaussian Splatting, 3DGS)技术基于高斯分布的概率模型叠加来表征场景,但其重建结果在几何和纹理边界处往往存在模糊问题。 这种模糊效应会随着重建过程中不确定性的累积而愈发显著。 如图 1 所示,通过提高渲染分辨率可以明显观察到这种边界模糊现象。
3/29/2025 8:11:00 PM
机器之心

3D基础模型时代开启?Meta与牛津大学推出VGGT,一站式Transformer开创高效3D视觉新范式
「仅需一次前向推理,即可预测相机参数、深度图、点云与 3D 轨迹 ——VGGT 如何重新定义 3D 视觉? 」3D 视觉领域正迎来新的巨变。 牛津大学 VGG (Visual Geometry Group) 与 Meta AI 团队联合发布的最新研究 VGGT(Visual Geometry Grounded Transformer),提出了一种基于纯前馈 Transformer 架构的通用 3D 视觉模型,能够从单张、多张甚至上百张图像中直接推理出相机内参、外参、深度图、点云及 3D 点轨迹等核心几何信息。
3/28/2025 10:16:00 AM
机器之心

把MLA和稀疏激活带到端侧!港科大广州和伦敦大学学院团队联合发布软硬协同设计的边缘语言模型PLM
本文由 PLM 团队撰写,PLM 团队是由香港科技大学(广州)的校长倪明选教授,伦敦大学学院(UCL)AI 中心汪军教授,香港科技大学(广州)信息枢纽院长陈雷教授联合指导。 第一作者邓程是香港科技大学(广州)的研究助理,研究方向为端侧大模型和高效模型推理;参与成员包括中科院自动化所的孙罗洋博士,曾勇程博士,姜纪文硕士,UCL 吴昕键,港科大广州的博士生肖庆发和赵文欣,港科大的博士后王嘉川以及香港理工的助理教授(研究)李昊洋。 通讯作者为邓程博士,陈雷教授和汪军教授。
3/27/2025 11:59:00 AM
机器之心

视频生成的测试时Scaling时刻!清华开源Video-T1,无需重新训练让性能飙升
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。 视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。 受到 Test-Time Scaling 在 LLM 中的应用启发,来自清华大学、腾讯的研究团队首次对视频生成的 Test-Time Scaling 进行探索,表明了视频生成也能够进行 Test-Time Scaling 以提升性能,并提出高效的 Tree-of-Frames 方法拓展这一 Scaling 范式。
3/26/2025 1:07:00 PM
机器之心

300年后牛顿法得到改进,修改泰勒展开式,收敛速度更快
几乎每一天,研究人员都在寻找最优解。 他们可能需要确定大型航空枢纽的最佳选址,或者如何在投资组合中最大化收益的同时最小化风险,又或者开发能够区分交通灯和停车标志的自动驾驶汽车。 从数学角度来看,这些问题都可转化为对函数最小值的搜索。
3/26/2025 1:02:00 PM
机器之心

挖掘DiT的位置解耦特性,Personalize Anything免训练实现个性化图像生成
本文的主要作者来自北京航空航天大学、清华大学和中国人民大学。 本文的第一作者为清华大学硕士生封皓然,共同第一作者暨项目负责人为北京航空航天大学硕士生黄泽桓,团队主要研究方向为计算机视觉与生成式人工智能。 本文的通讯作者为北京航空航天大学副教授盛律。
3/25/2025 12:33:00 PM
机器之心

CVPR 2025 | Qwen让AI「看见」三维世界,SeeGround实现零样本开放词汇3D视觉定位
3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。 具体而言,给定一个 3D 场景和一段文本描述,模型需要准确预测目标物体的 3D 位置,并以 3D 包围框的形式输出。 相比于传统的目标检测任务,3DVG 需要同时理解文本、视觉和空间信息,挑战性更高。
3/24/2025 1:06:00 PM
机器之心

田渊栋和Sergey Levine参与开发新型RL算法,能通过多轮训练让智能体学会协作推理
现实世界中,很多任务很复杂,需要执行一系列的决策。 而要让智能体在这些任务上实现最佳性能,通常需要直接在多轮相关目标(比如成功率)上执行优化。 不过,相比于模仿每一轮中最可能的动作,这种方法的难度要大得多。
3/23/2025 3:45:00 PM
机器之心
资讯热榜
标签云
人工智能
OpenAI
AIGC
AI
ChatGPT
AI绘画
DeepSeek
数据
模型
机器人
谷歌
大模型
Midjourney
智能
开源
用户
学习
GPT
微软
Meta
图像
AI创作
技术
论文
Stable Diffusion
马斯克
Gemini
算法
蛋白质
芯片
代码
生成式
英伟达
腾讯
神经网络
研究
计算
Anthropic
3D
Sora
AI for Science
AI设计
机器学习
开发者
GPU
AI视频
华为
场景
预测
人形机器人
百度
苹果
伟达
Transformer
深度学习
xAI
模态
字节跳动
Claude
大语言模型
搜索
具身智能
驾驶
神器推荐
文本
Copilot
LLaMA
算力
安全
视觉
视频生成
干货合集
训练
应用
大型语言模型
科技
亚马逊
DeepMind
特斯拉
智能体