工程

大模型推理无损加速6.5倍!EAGLE-3碾压一切、延续Scaling Law能力
自回归解码已然成为大语言模型的推理标准。 大语言模型每次前向计算需要访问它全部的参数,但只能得到一个 token,导致其生成昂贵且缓慢。 近日,EAGLE 团队的新作《EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test》通过一系列优化解锁了投机采样的 Scaling Law 能力,可以将大语言模型的推理速度提高 6.5 倍,同时不改变大语言模型的输出分布,确保无损。
4/10/2025 11:12:00 AM
机器之心

从零搭一套可复现、可教学、可观察的RL for VLM训练流程,我们试了试
自 Deepseek-R1 发布以来,研究社区迅速响应,纷纷在各自任务中复现 R1-moment。 在过去的几个月中,越来越多的研究尝试将 RL Scaling 的成功应用扩展到视觉语言模型(VLM)领域 —— 刷榜、追性能、制造 “Aha Moment”,整个社区正高速奔跑,RL for VLM 的边界也在不断被推远。 但在这样一个节奏飞快、聚焦结果的研究环境中,基础设施层面的透明性、评估的一致性,以及训练过程的可解释性,往往被忽视。
4/9/2025 11:24:00 AM
机器之心

迈向机器人领域ImageNet,大牛Pieter Abbeel领衔国内外高校共建RoboVerse,统一仿真平台、数据集和基准
大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。 然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。 一方面,采集真实世界的机器人数据需要消耗大量资源(如时间、硬件成本),且效率低下;另一方面,在现实场景中测试机器人性能面临复杂的环境配置,难以控制变量并标准化。
4/8/2025 6:38:00 PM
机器之心

UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。 该方法通过预定义奖励函数规避人工标注成本,如 DeepSeek-R1 在数学求解中的成功应用,以及多模态领域在图像定位等任务上的性能突破(通常使用 IOU 作为规则 reward)。 vivo 与香港中文大学的研究团队受到 DeepSeek-R1 的启发,首次将基于规则的强化学习(RL)应用到了 GUI 智能体领域。
4/8/2025 6:33:00 PM
机器之心

类R1强化学习迁移到视觉定位!全开源Vision-R1将图文大模型性能提升50%
图文大模型通常采用「预训练 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。 受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。 目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。
4/8/2025 1:27:00 PM
机器之心

颠覆传统信息搜索,效果是之前SOTA的三倍?UIUC韩家炜、孙冀萌团队开源DeepRetrieval,让模型端到端地学会搜索!
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。 尤其在专业搜索场景(如文献、数据库查询)中,用户往往无法用精确、完整的表达描述他们的需求。 那么问题来了:能不能教大模型优化原始 query 的表达方式,从而让已有检索系统的能力被最大化激发?
4/8/2025 1:22:00 PM
机器之心

MoCha:开启自动化多轮对话电影生成新时代
本文由加拿大滑铁卢大学魏聪、陈文虎教授团队与 Meta GenAI 共同完成。 第一作者魏聪为加拿大滑铁卢大学计算机科学系二年级博士生,导师为陈文虎教授,陈文虎教授为通讯作者。 近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创作中的应用潜力。
4/7/2025 1:17:00 PM
机器之心

铰链物体的通用世界模型,超越扩散方法,入选CVPR 2025
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。 尽管现在基于 diffusion 的方法取得了很多进展,但是这些方法存在处理效率低,同时缺乏三维感知等问题,难以投入真实环境中使用。 清华大学联合北京大学提出了第一个基于重建模型的 part-level 运动的建模——PartRM。
4/7/2025 1:10:00 PM
机器之心

ILLUME+:华为诺亚探索新GPT-4o架构,理解生成一体模型,昇腾可训!
近年来,基于大语言模型(LLM)的多模态任务处理能力取得了显著进展,特别是在将视觉信息融入语言模型方面。 像 QwenVL 和 InternVL 这样的模型已经展示了在视觉理解方面的卓越表现,而以扩散模型为代表的文本到图像生成技术也不断突破,推动了统一多模态大语言模型(MLLM)的发展。 这些技术的进步使得视觉理解和生成能力的无缝集成成为可能,进一步推进了视觉和语义深度融合下的人工通用智能(AGI)的探索。
4/7/2025 12:59:00 PM
机器之心

大语言模型变身软体机器人设计「自然选择器」,GPT、Gemini、Grok争做最佳
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。 密歇根大学安娜堡分校的研究团队开发了一个名为「RoboCrafter-QA」的基准测试,用于评估 LLM 在软体机器人设计中的表现,探索了这些模型能否担任机器人设计的「自然选择器」角色。 这项研究为 AI 辅助软体机器人设计开辟了崭新道路,有望实现更自动化、更智能的设计流程。
4/6/2025 9:58:00 AM
机器之心
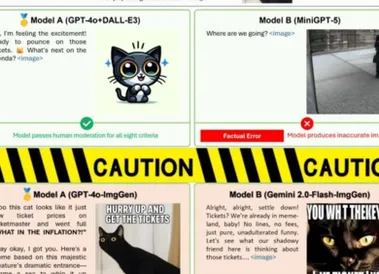
CVPR 2025 Oral | 多模态交互新基准OpenING,新版GPT-4o杀疯了?
不必纠结了! 人类大脑天然具备同时理解和创造视觉与语言信息的能力。 一个通用的多模态大语言模型(MLLM)理应复刻人类的理解和生成能力,即能够自如地同时处理与生成各种模态内容,实现多模态交互,这也是向通用人工智能(AGI)迈进的关键挑战之一。
4/5/2025 5:24:00 PM
机器之心

CVPR 2025 | GaussianCity: 60倍加速,让3D城市瞬间生成
想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。 然而,现实却远非如此。 现有的 3D 城市生成方法,如基于 NeRF 的 CityDreamer [1],虽然能够生成逼真的城市场景,但渲染速度较慢,难以满足游戏、虚拟现实和自动驾驶模拟对实时性的需求。
4/5/2025 5:07:00 PM
机器之心

Multi-Token突破注意力机制瓶颈,Meta发明了一种很新的Transformer
当上下文包含大量 Token 时,如何在忽略干扰因素的同时关注到相关部分,是一个至关重要的问题。 然而,大量研究表明,标准注意力在这种情况下可能会出现性能不佳的问题。 标准多头注意力的工作原理是使用点积比较当前查询向量与上下文 Token 对应的键向量的相似性。
4/4/2025 6:23:00 PM
机器之心

ICLR 2025 Spotlight | 参数高效微调新范式!上海交大联合上海AI Lab推出参数冗余微调算法
本文作者来自复旦大学、上海交通大学和上海人工智能实验室。 一作江书洋为复旦大学和实验室联培的博二学生,目前是实验室见习研究员,师从上海交通大学人工智能学院王钰教授。 本文通讯作者为王钰教授与张娅教授。
4/3/2025 1:54:00 PM
机器之心
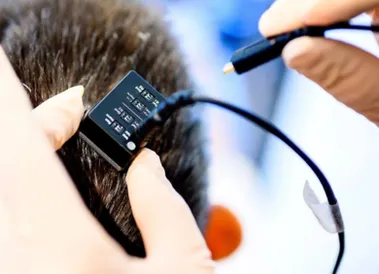
脑波解码延迟仅80毫秒,实时「意念对话」技术登Nature子刊
无法说话的人,现在可以通过大脑扫描的方式实时地用自己的声音说话了。 整个过程没有延迟,也不需要打字,不用发出任何声音。 本周,脑机接口的最新研究在社交网络上引发了人们的热烈讨论,一位推特博主的帖子浏览量突破了 150 万。
4/2/2025 6:10:00 PM
机器之心

近千个反现实视频构建了「不可能」基准,哪个AI不服?来战!
白泽琛,新加坡国立大学 Show Lab 博士生,他的研究方向主要包括视频理解和统一的多模态模型,在 CVPR、ICCV、NeurIPS、ICLR 等会议发表多篇文章;曾在 Amazon AI 担任 Applied Scientist,在 ByteDance、Baidu 担任 Research Intern。 兹海,新加坡国立大学 Show Lab Research Fellow,于北京大学获得博士学位,主要研究方向为多模态模型的安全。 Mike Zheng Shou,PI,新加坡国立大学校长青年教授,福布斯 30 under 30 Asia,创立并领导 Show Lab 实验室。
4/2/2025 6:05:00 PM
机器之心

细节厘米级还原、实时渲染,MTGS方法突破自动驾驶场景重建瓶颈
在自动驾驶领域,高精度仿真系统扮演着 “虚拟练兵场” 的角色。 工程师需要在数字世界中模拟暴雨、拥堵、突发事故等极端场景,反复验证算法的可靠性。 然而,传统仿真技术往往面临两大难题:首先是视角局限,依赖单一轨迹数据,如一条固定路线的摄像头录像,重建的场景只能在有限视角内逼真,无法支持车辆 “自由探索”。
4/2/2025 1:17:00 PM
机器之心

自动学会工具解题,RL扩展催化奥数能力激增17%
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。 不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。 为了解决这些难题,来自上海交通大学、SII 和 GAIR 的研究团队提出了一种全新框架 ToRL(Tool-Integrated Reinforcement Learning),该方法允许模型直接从基座模型开始,通过强化学习自主探索最优工具使用策略,而非受限于预定义的工具使用模式。
4/1/2025 6:48:00 PM
机器之心
资讯热榜
标签云
人工智能
OpenAI
AIGC
AI
ChatGPT
AI绘画
DeepSeek
数据
模型
机器人
谷歌
大模型
Midjourney
智能
开源
用户
学习
GPT
微软
Meta
图像
AI创作
技术
论文
Stable Diffusion
马斯克
Gemini
算法
蛋白质
芯片
代码
生成式
英伟达
腾讯
神经网络
研究
计算
Anthropic
3D
Sora
AI for Science
AI设计
机器学习
开发者
GPU
AI视频
华为
场景
预测
人形机器人
百度
苹果
伟达
Transformer
深度学习
xAI
模态
字节跳动
Claude
大语言模型
搜索
具身智能
驾驶
神器推荐
文本
Copilot
LLaMA
算力
安全
视觉
视频生成
干货合集
训练
应用
大型语言模型
科技
亚马逊
DeepMind
特斯拉
智能体