
在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。
终于,近期由来自南京大学、中科院、清华大学、腾讯等机构的联合研究团队,提出一个名为 IDOL 的全新解决方案,高分拿下 2025 CVPR。项目主页目前访问次数已超 2500+ 次,且是可商用的 MIT 开源协议,备受业界瞩目。

图 1 IDOL 速览
为什么 IDOL 这么受欢迎?因为它为单图 3D 人体重建问题提供了一种全新的高效解决方案。该模型不仅能够在单 GPU 上以秒级速度生成高分辨率的逼真 3D 人体,还具备实时渲染、直接动画化与编辑的能力,为 VR/AR、虚拟数字人以及相关领域的应用提供了全新思路。

论文标题:IDOL: Instant Photorealistic 3D Human Creation from a Single Image
论文地址:https://arxiv.org/pdf/2412.14963
项目主页:https://yiyuzhuang.github.io/IDOL
该工作已开源:https://github.com/yiyuzhuang/IDOL(开源协议为 MIT,可商用)
 IDOL demo video
IDOL demo video
单图重建人体,为什么这么难?
从单幅图像重建高质量且可驱动的人体模型是一项极具挑战性的任务。这一挑战主要源于人体姿态和衣物拓扑外观的多样性,以及缺乏大规模高质量的训练数据。
当前解决这一问题的方案通常面临以下困难:
优化时间长:基于扩散模型的优化过程耗时较长,通常需要数分钟甚至数小时。
依赖准确的 SMPL 参数估计:采用参数化人体模型作为拓扑先验,依赖精确的 SMPL-X 参数估计,且迭代优化时间较长。
泛化性不足:处理大姿态、大侧面视角以及宽松衣物等挑战性样本时,泛化能力不足。
缺乏真实感:重建结果常常出现卡通化或过饱和的现象,且对不可见区域的补充往往不够自然。
动画化困难:许多重建方法未充分考虑后续的驱动需求,需额外的骨骼绑定(rigging)处理。且表达方式的限制使其难以泛化到新姿态。
编辑能力受限:生成的 3D 模型往往难以直接进行外观修改,需要额外的 UV 展开等处理。
IDOL 为什么有效?
作者提出了一种高效且可扩展的重建框架,通过训练一个简单的前馈模型(IDOL),实现了即时且可泛化的真实感 3D 人体重建。
大规模数据集 HuGe100K
作者通过微调构建了一个能够生成高视点一致性的多视点图像生成网络(MVChamp),并创建了 HuGe100K 数据集——一个以人为中心的大规模生成数据集。
该数据集包含超过 240 万张高分辨率(896×640)的人体多视图图像,共计 100K 个(10 万组)样本。每组图像通过一个可控姿势的图像到多视角生成模型生成,共包含 24 个视角帧。
数据集涵盖了多样化的个体特征(包括不同年龄、性别、体型、服饰和场景)为模型训练提供了充足的样本,从而显著提升了模型在各种复杂条件下的重建能力。

图 2 构建 HuGe100K 数据集的路线图
前馈式 Transformer 重建模型 IDOL
基于此数据集,我们训练了一个预训练的编码器和一个基于 Transformer 的骨干网络,能够在 1 秒内实现快速重建。
该模型能够直接从单张输入图像中预测出人体在统一空间下的 3D 高斯表示。通过将人体姿势、体型、服装几何结构与纹理进行解耦,模型不仅能生成高保真 3D 人体,还能实现无需后处理的直接动画化,为后续的形状与纹理编辑提供了便利。
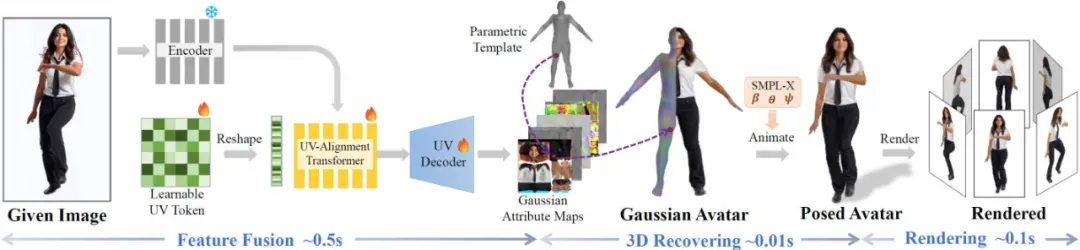
图 3 IDOL 的技术路线图
方法流程与技术细节,如图 3:
1. 数据集构建流程
文本提示与图像生成:利用先进的文本到图像生成模型(如 Flux),设计描述性提示语,确保在「区域、服饰、体型、年龄、性别」等维度上实现均衡采样,从而生成 10 万张高质量全身人体图像(经过人工筛选,保留 90K 张合成图像,并融合 10K 张真实图像)。
多视角图像生成:基于生成的全身图像,通过训练多视角视频生成模型(MVChamp),再结合 SMPL-X 人体模板进行姿态拟合,获得 24 个均匀分布的视角图像,确保数据在 3D 一致性上的准确性。
2. 模型架构
高分辨率编码器:采用预训练的人体基础模型 Sapiens,对 1024×1024 高分辨率图像进行特征提取,保留图像中的细粒度信息。
UV 对齐 Transformer:通过学习的 UV Token 与图像特征进行融合,将不规则的输入图像映射到规则的 2D UV 空间中,此空间由 SMPL-X 模型定义,能够提供丰富的几何和语义先验。
UV 解码器:将融合后的特征重构成 3D 高斯属性图(包括位置偏移、旋转、尺度、颜色及不透明度),从而得到用于重建人体的高斯表示。
动画与渲染:利用线性混合蒙皮(LBS)技术,根据预定义的关节运动,对高斯表示进行前向变换,实现人体在不同姿态下的动画化。
3. 训练目标与损失函数
模型采用多视角图像监督,利用均方误差(MSE)和基于 VGG 网络的感知损失共同优化。这样的组合既保证了重建图像在像素级别的准确性,又能提高整体的感知质量,使生成的人体纹理更为自然、细腻。
本方法的优势:高效与实时性
IDOL 模型经过优化后,在单个 GPU 上仅需不到 1 秒即可重建 1K 分辨率的逼真 3D 人体,极大地提升了实用性和应用场景的广泛性。该方法具有以下优势:
1 秒内完成高质量 3D 角色重建;
统一的 UV 表达与大规模数据集支撑,泛化性强;
可驱动性,无需额外绑骨;
支持形变与纹理编辑;
基于 3DGS 的表达,支持实时渲染。
定量看 IDOL 怎么样?
IDOL 与其他方法的对比
IDOL 相较传统 3D 建模方法实现多重突破:自研 10 万级多视角数据集 HuGe100K(传统方法仅依赖少量扫描数据),显著提升模型泛化能力;
创新性融合 SMPL-X 人体拓扑与 UV 展开的高斯溅射属性(替代传统体素/隐式场),实现解剖学精准建模;
1 秒级实时重建(传统需数小时)且支持线性蒙皮自动驱动动画(无需手动 RIGGING),更具备形变、换装等灵活编辑特性。
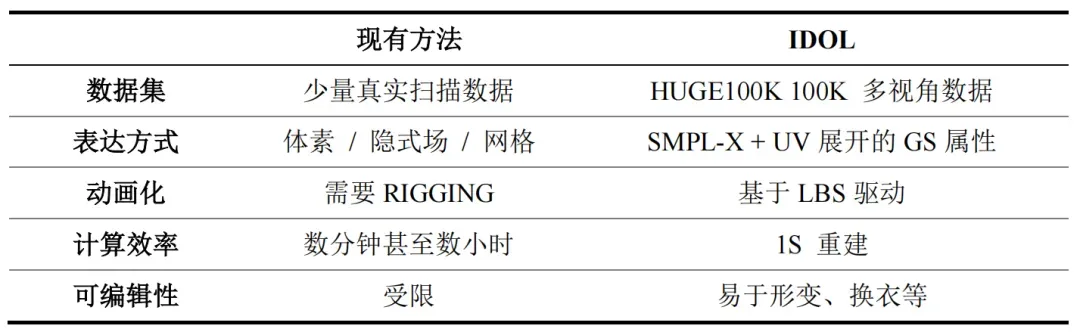
表 1 IDOL 与传统方法对比一览
HuGe100K 与其他数据集的对比
通过对模型中各关键组件(如 Sapiens 编码器、HuGe100K 数据集)的逐一剔除测试,验证了各模块对整体性能的重要贡献,证明了数据集规模与高分辨率特征提取对高质量重建不可或缺。
与现有数据集相比,HUGE100K 以 100K 个体数量(远超同类最高 4500 个 ID)和超 2.4M 帧数的规模,成为目前全球最大、多样性最丰富的 3D 人体数据集。
多样性突破:覆盖 10 万级体型与姿态,解决模型泛化瓶颈;
动态建模:百万级多视角帧包含多样化姿态;
准确动作标注:集成准确的 SMPL-X 参数,无缝适配主流 3D 工具链。为单图重建、数字人驱动提供工业化级数据引擎,填补了高多样性、大规模动态人体数据的空白。

表 2 HuGe 100K 数据集与其他数据集对比
重建质量对比
IDOL 在与现有方法(如基于迭代优化的 GTA、SIFU 等)对比中,IDOL 在 MSE、PSNR 和 LPIPS 等指标上均取得显著优势,证明了其在重建精度和细节保留上的优越性。

表 3 对比实验及消融实验指标
实验验证了 IDOL 在不同场景和姿态下均能生成细节丰富、纹理一致的 3D 人体。
无论是复杂服饰、特殊角度拍摄,还是不同体型的人体重建,IDOL 均表现出极好的泛化能力和鲁棒性。

图 4 IDOL 与其他方法效果对比
IDOL 未来能做什么?
IDOL 方法不仅在技术上取得了显著突破,其应用前景也十分广阔。其开源协议 MIT 自由可商用,欢迎大家随意搭建到自己的应用中。
利用 IDOL 生成的 3D 人体,用户可以直接进行形状和纹理编辑,例如调整服装图案或改变体型参数。同时,结合动画技术,该模型还可以实现视频中的身份替换等应用,展现出极高的实用价值。
虚拟现实与增强现实:
即时生成真实感 3D 人体模型为 VR/AR 应用提供了新的交互方式,可以实现实时虚拟形象替换、数字孪生等创新应用场景。
数字娱乐与游戏开发:
通过单图重建,游戏开发者可以快速生成高质量角色模型,大幅降低建模成本,加速内容创作流程,从而推动数字娱乐产业的发展。
虚拟试衣与时尚产业:
在电商和虚拟试衣领域,利用 IDOL 技术可以实现用户上传单张照片后即刻生成 3D 人体模型,为消费者提供个性化试衣、定制服务,提升用户体验。
这篇论文通过创新性的单图重建思路,实现了从单张 2D 图像瞬时生成高质量 3D 人体模型的目标。其核心在于将视频模型先验、人体先验、隐式表示与可微渲染技术紧密结合,构建了一个端到端可微分的优化框架。重构了传统单目人体重建的管线(图片→3D→绑骨→驱动),极大的提高了泛化性与实用性。
实验结果证明,IDOL 在重建精度、纹理细节和实时性方面均表现出色,展现了广泛的应用前景。
未来,随着技术的不断演进和数据规模的进一步扩大,该方法有望在 VR/AR、游戏、时尚等领域引领一场 3D 数字内容创作的革新,为实际应用提供更加高效、真实的解决方案。


