乐天集团宣布推出其首个日本大语言模型(LLM)和小语言模型(SLM),命名为Rakuten AI2.0和Rakuten AI2.0mini。
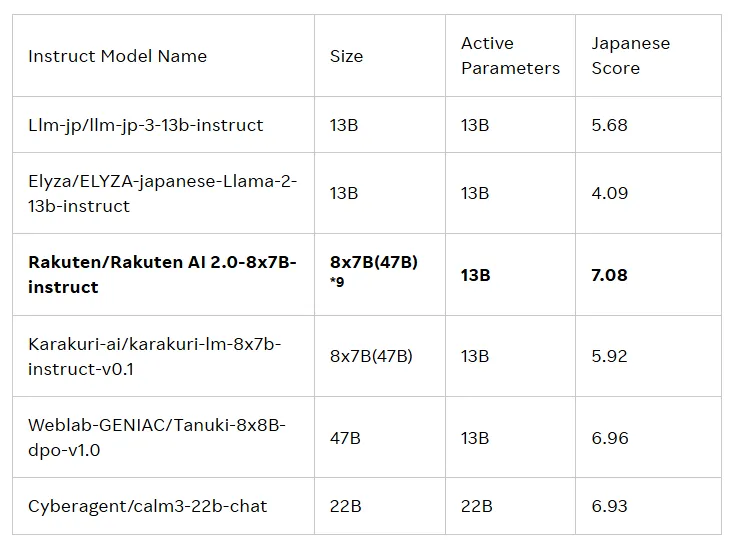
这两款模型的发布旨在推动日本的人工智能(AI)发展。Rakuten AI2.0基于混合专家(MoE)架构,是一款8x7B 的模型,由八个各自拥有70亿参数的模型组成,每个模型充当一个专家。每当处理输入的 token 时,系统会将其发送给最相关的两个专家,由路由器负责选择。这些专家和路由器不断通过大量的高质量日英双语数据进行联合训练。
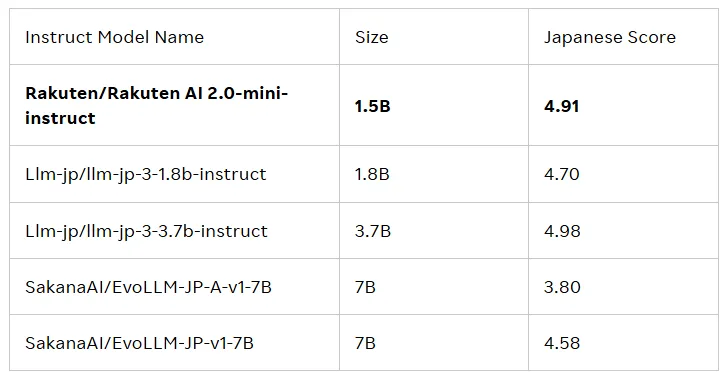
Rakuten AI2.0mini 则是一款全新的、参数量为15亿的稠密模型,专为成本效益高的边缘设备部署而设计,适合特定应用场景。它同样在日英混合数据上进行训练,目的是提供便捷的解决方案。两款模型均经过指令微调和偏好优化,发布了基础模型和指令模型,以支持企业和专业人士开发 AI 应用。
所有模型均采用 Apache2.0许可协议,用户可在乐天集团的 Hugging Face 官方库中获取,商业用途包括文本生成、内容摘要、问答、文本理解及对话系统构建等。此外,这些模型也可作为其他模型的基础,便于进一步的开发和应用。
乐天集团的首席 AI 与数据官蔡婷表示:“我为我们的团队如何将数据、工程和科学结合起来,推出Rakuten AI2.0感到无比自豪。我们的新 AI 模型提供了强大且具成本效益的解决方案,帮助企业做出智能决策,加快价值实现,并开启新的可能性。通过开放模型,我们希望加速日本的 AI 发展,鼓励所有日本企业进行构建、实验和成长,推动一个协作共赢的社区。”
官方博客:https://global.rakuten.com/corp/news/press/2025/0212_02.html
划重点:
🌟 乐天集团推出首个日本大语言模型(LLM)和小语言模型(SLM),名为Rakuten AI2.0和Rakuten AI2.0mini。
📊Rakuten AI2.0基于混合专家架构,拥有八个70亿参数的专家模型,致力于高效处理日英双语数据。
🛠️ 所有模型均可在乐天 Hugging Face 官方库获取,适用于多种文本生成任务,并可作为其他模型的基础。


