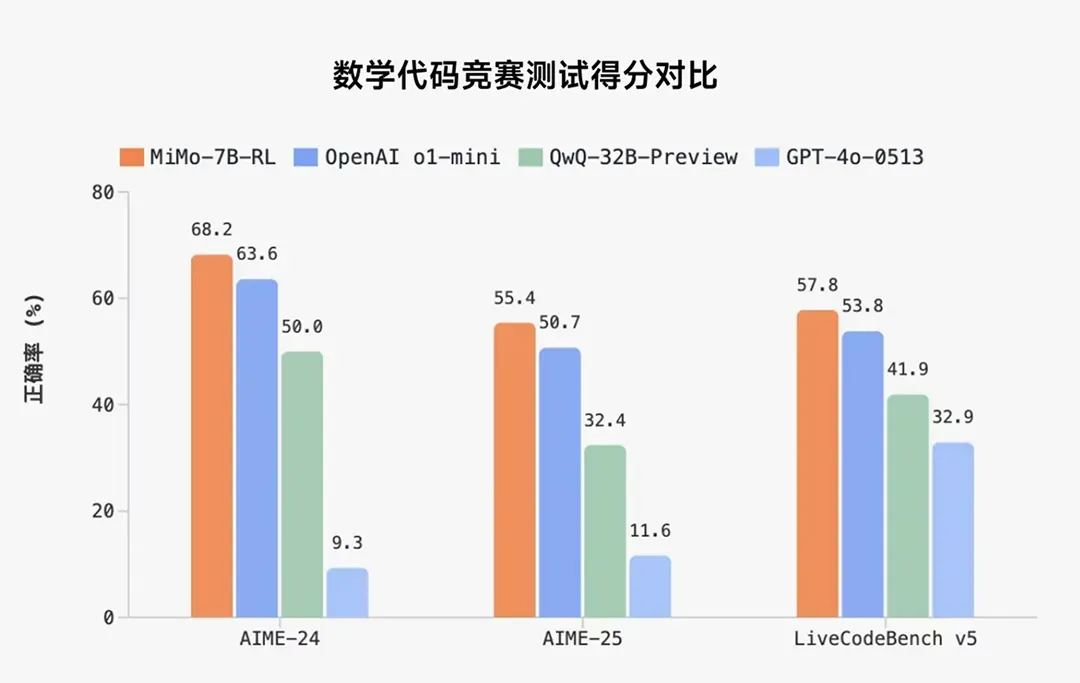
在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)公开测评集上,MiMo 仅用 7B 的参数规模,超越了 OpenAI 的闭源推理模型 o1-mini 和阿里 Qwen 更大规模的开源推理模型 QwQ-32B-Preview。
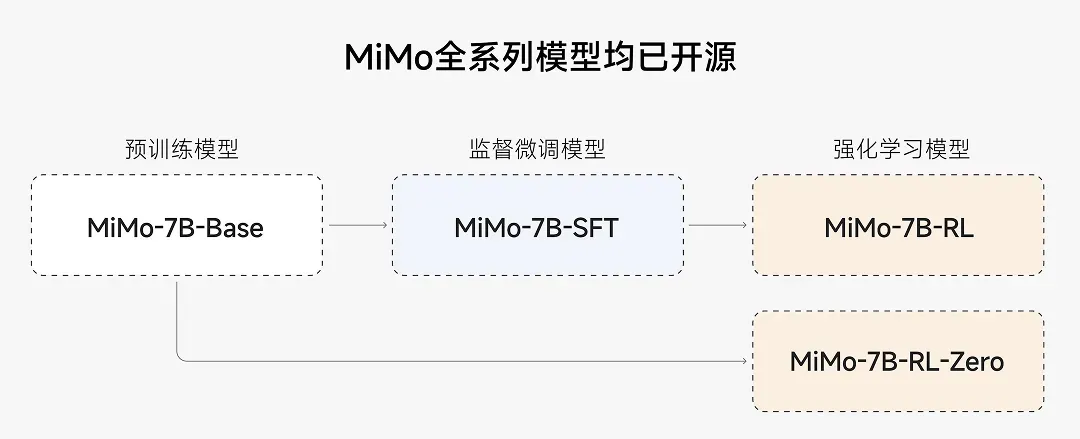
官方表示,MiMo 推理能力的提升,由预训练和后训练阶段中数据和算法等多层面的创新联合驱动,包括:
预训练:核心是让模型见过更多推理模式
数据:着重挖掘富推理语料,并合成约 200B tokens 推理数据。
训练:进行了三阶段训练,逐步提升训练难度,总训练 25T tokens。

后训练:核心是高效稳定的强化学习算法和框架
算法:提出 Test Difficulty Driven Reward 来缓解困难算法问题中的奖励稀疏问题,并引入 Easy Data Re-Sampling 策略,以稳定 RL 训练。
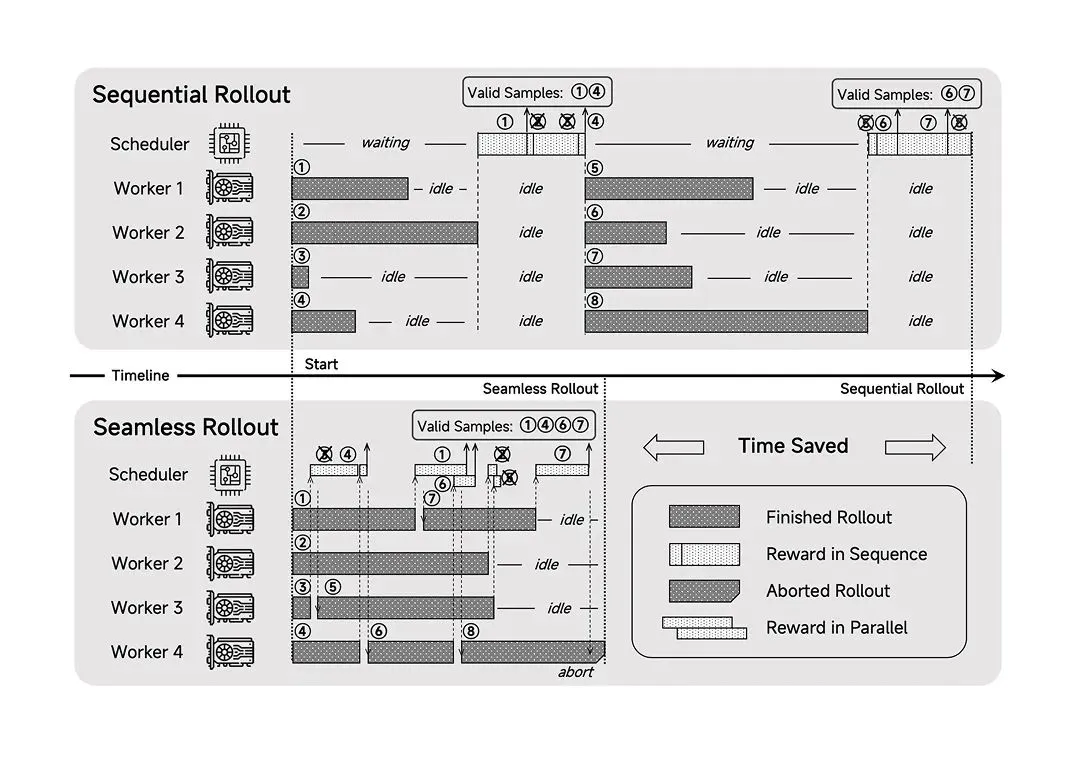
框架:设计了 Seamless Rollout 系统,使得 RL 训练加速 2.29 倍,验证加速 1.96 倍。
AI在线附开源地址:
Hugging Face:https://huggingface.co/XiaomiMiMo
技术报告:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf