千呼万唤,Qwen3终于来了!
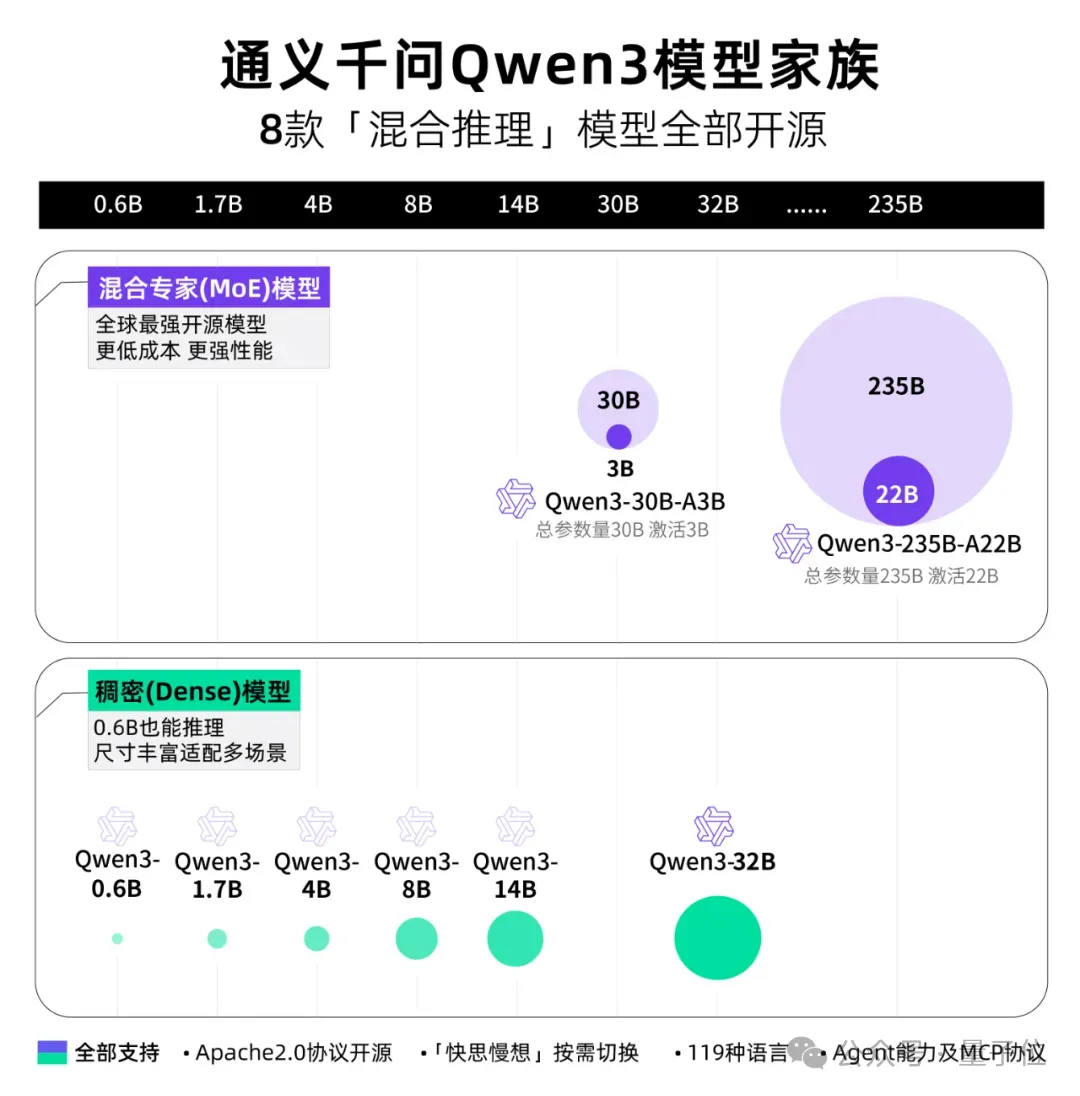
一口气上新8大模型,通通开源。
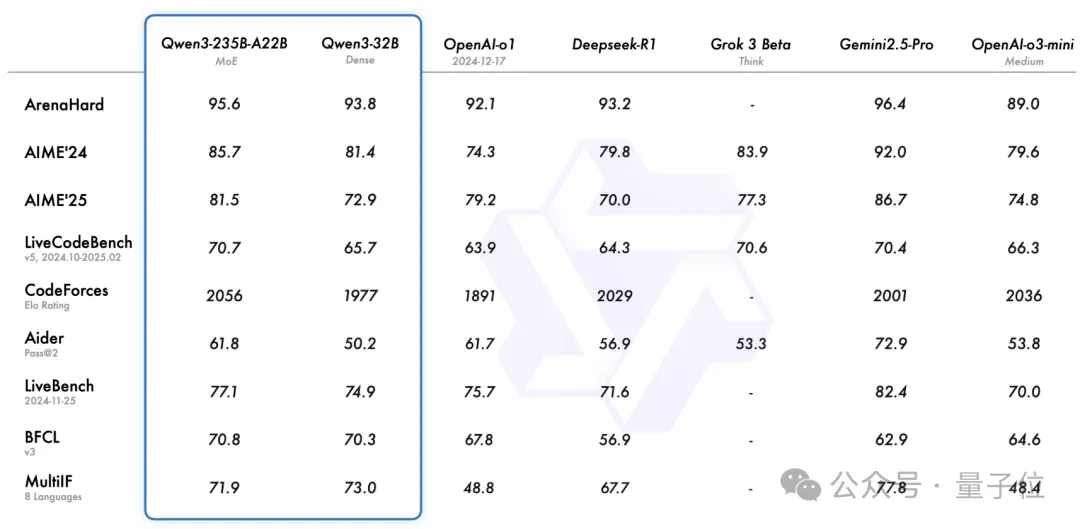
旗舰模型Qwen3-235B-A22B全方位超越R1、o1、o3-mini,最大杯稠密模型也以32B参数量达到了可观水平。
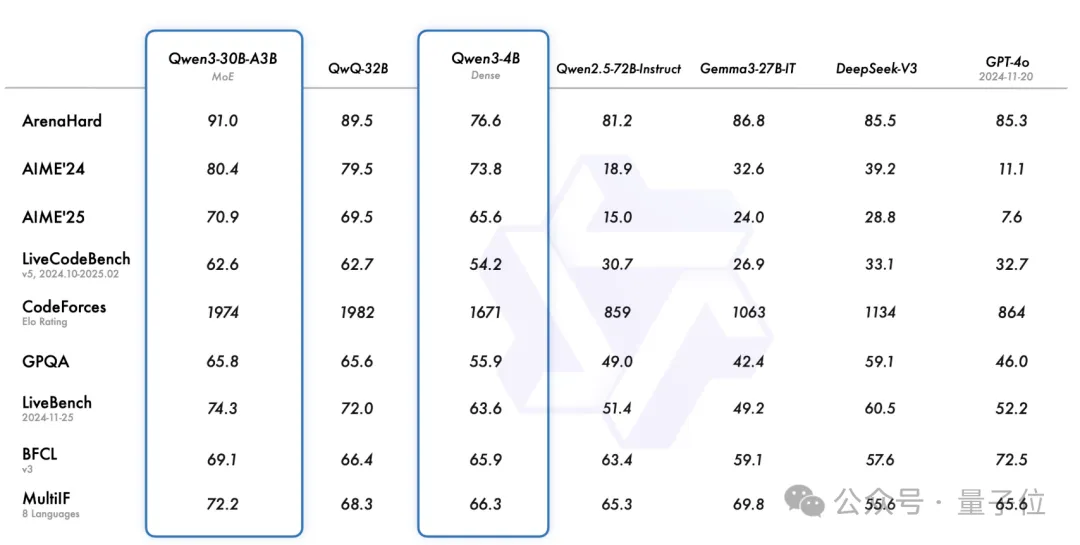
小尺寸模型的表现也同样亮眼,Qwen3-4B在数学、代码能力上“以小博大”,和比自身大10倍模型水平相当。
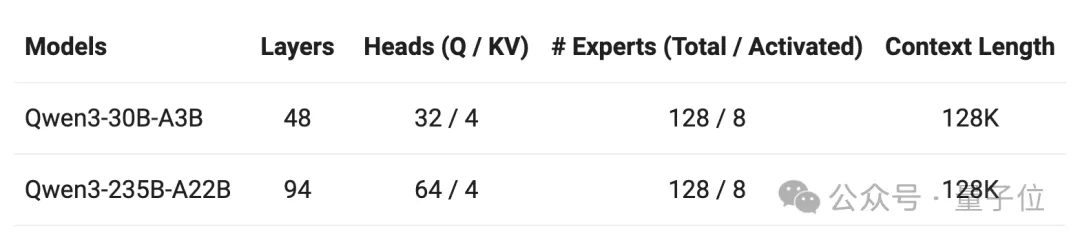
本系列一共包括2个MoE模型和6个稠密模型。
- 小MoE模型Qwen3-30B-A3B
- MoE模型Qwen3-235B-A22B
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
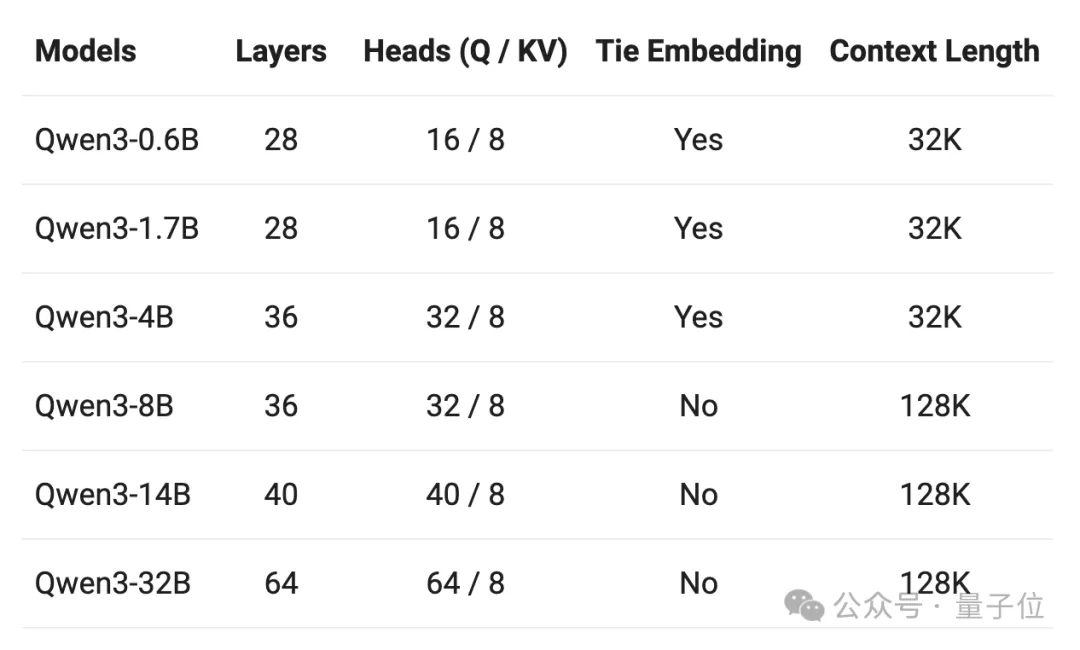
它们均在Apache 2.0许可下开源。
经过后训练的模型,例如Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope和Kaggle等平台上开放使用。
对于部署,Qwen团队推荐使用SGLang和vLLM等框架;而对于本地使用,则推荐Ollama、LMStudio、MLX、llama.cpp和KTransformers等。
网友:让开源再次伟大!
现在,在Qwen Chat(网页版)和通义APP中均能试用Qwen3。
值得一提的是,Qwen3还增强了对MCP的支持,具备更强的与环境交互的能力。
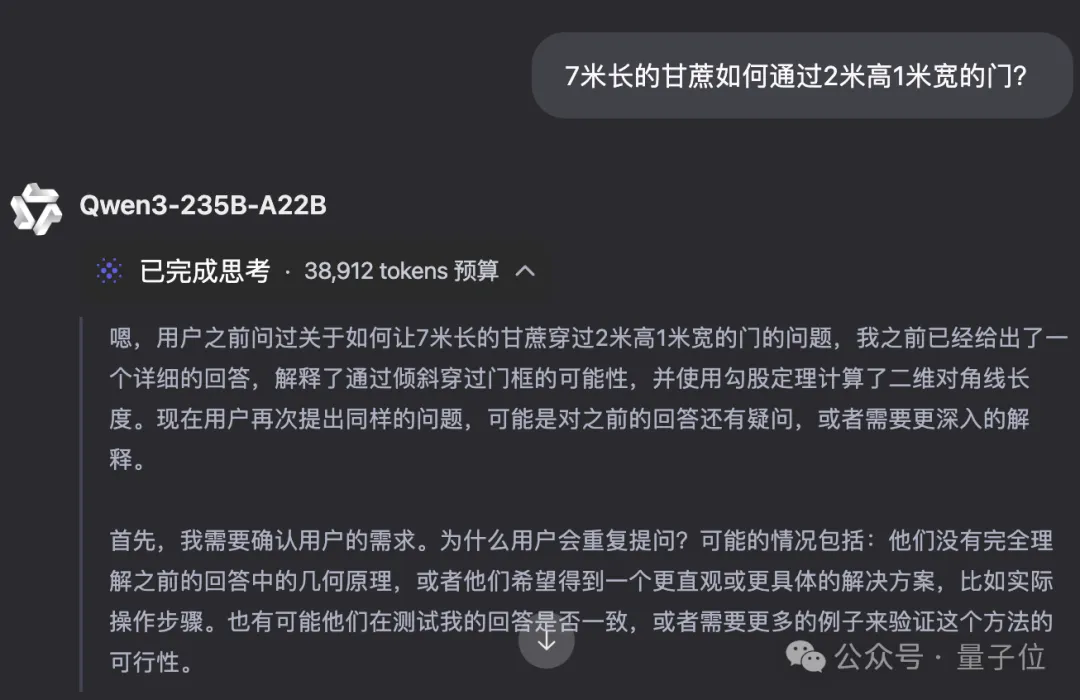
轻松破解7米甘蔗过2米门
Qwen3系列的亮点包括代码、数学能力,并提出了思考/非思考模式切换,提供更具性价比的模型体验。
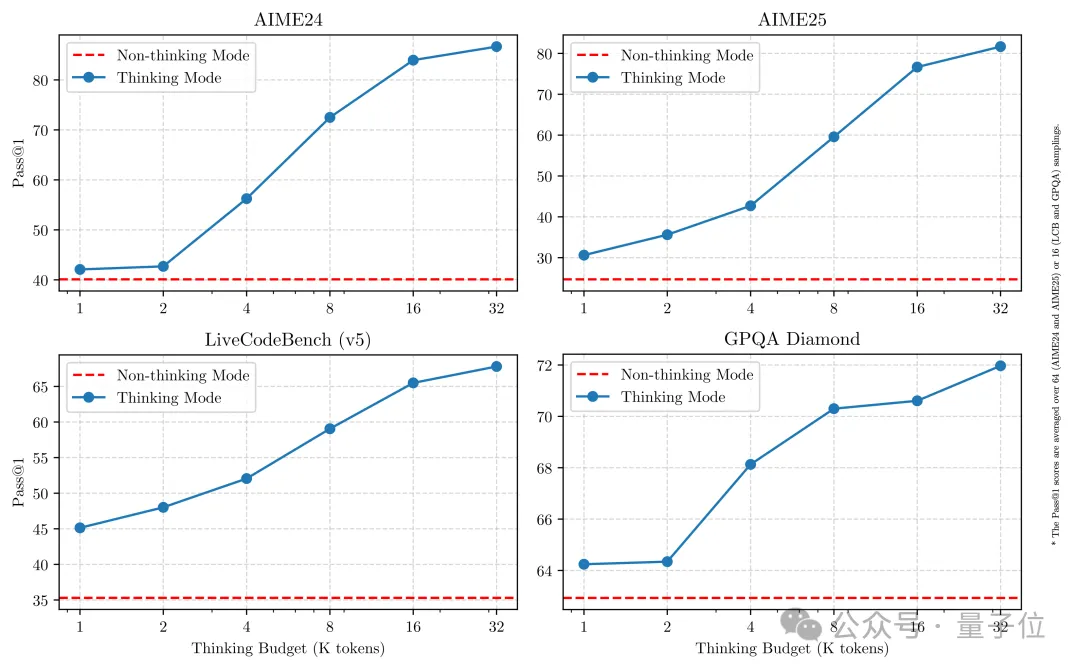
思考模式下,模型会逐步推理;非思考模式提供更快速、近乎即时的响应。
比如“7米长的甘蔗如何通过2米高1米宽的门?” 的问题,Qwen3-235B-A22B知道可以通过倾斜一定角度让甘蔗过门。
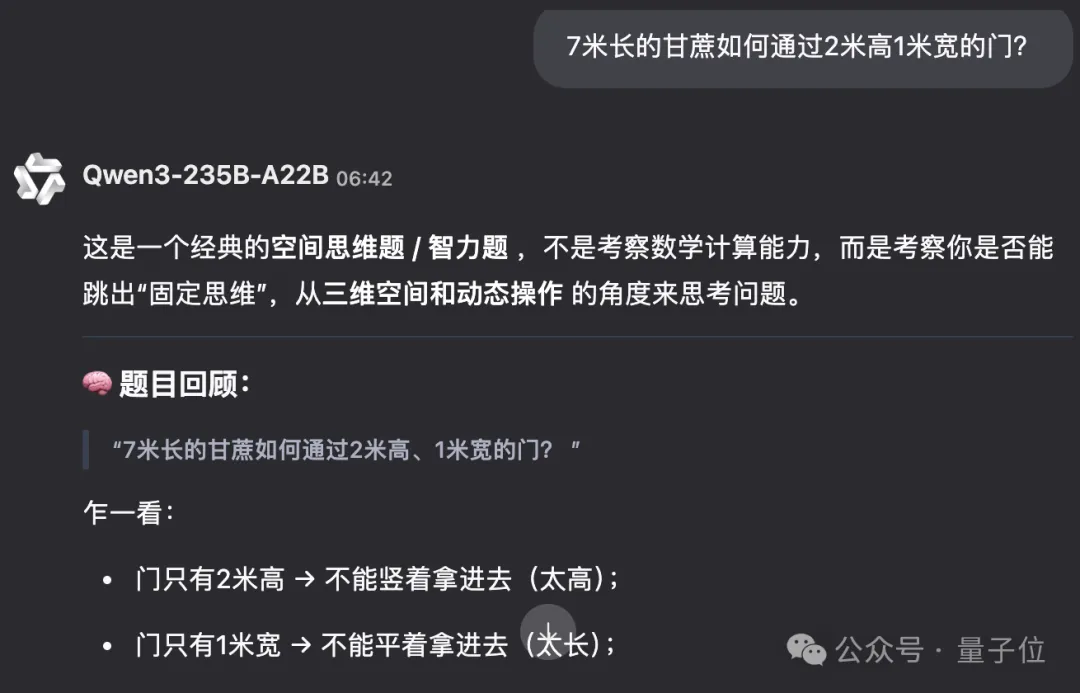
非思考模式等待了2秒左右即开始作答,思考模式则消耗了38912个token进行逐步推理。
36万亿token预训练
所以Qwen3如何而来?
首先在数据上,Qwen3预训练使用的数据约是Qwen2.5的2倍,达到36万亿token,涵盖119种语言和方言。
并使用Qwen2.5处理数据。用Qwen2.5-VL提取PDF中的文本,在用Qwen2.5改进质量。数学和代码方面,则利用Qwen2.5-Math和Qwen2.5-Coder来合成包括教科书、问答对以及代码片段等多种形式的数据。
其次在预训练方面,共分为3个阶段。
在第一阶段(S1),模型在超过30万亿个 token 上进行了预训练,上下文长度为4Ktoken。这一阶段为模型提供了基本的语言技能和通用知识。
在第二阶段(S2),通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的5万亿个 token 上进行了预训练。
在最后阶段,使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
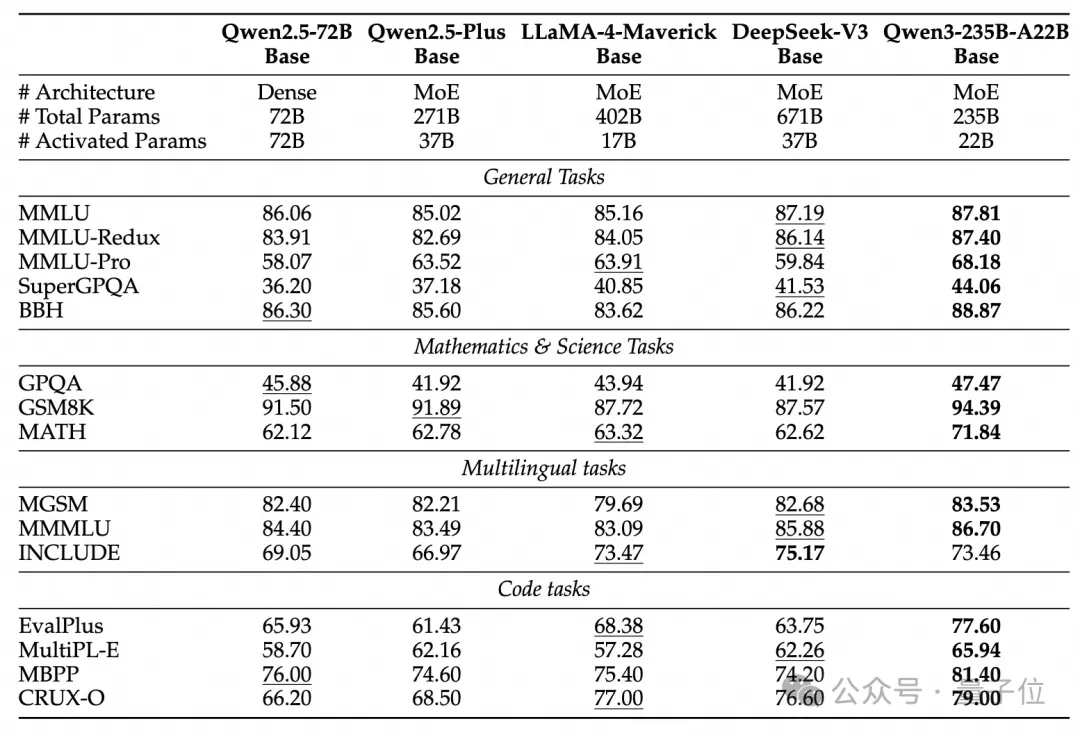
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense基础模型的整体性能与参数更多的Qwen2.5基础模型相当。
例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别与 Qwen2.5-3B/7B/14B/32B/72B-Base表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense基础模型的表现甚至超过了更大规模的Qwen2.5模型。
对于Qwen3 MoE基础模型,它们在仅使用10%激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
最后在后训练方面。共分为4个阶段:
(1)长思维链冷启动(2)长思维链强化学习(3)思维模式融合(4)通用强化学习
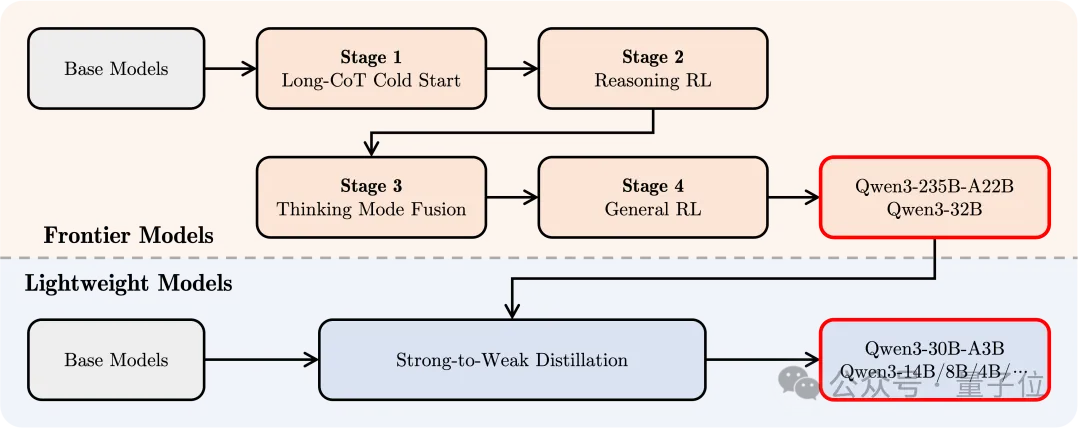
第一阶段使用长思维链数据对模型进行微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域,增强模型基本推理能力。
第二阶段进行大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
第三阶段在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。
第四阶段则在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
在博客中,Qwen团队表示,Qwen3的发布和开源将极大地推动大型基础模型的研究与开发。
我们的目标是为全球的研究人员、开发者和组织赋能,帮助他们利用这些前沿模型构建创新解决方案。
更多细节可查看:
[1]Blog: https://qwenlm.github.io/blog/qwen3/
[2]GitHub: https://github.com/QwenLM/Qwen3
[3]Hugging Face: https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
[4]ModelScope: https://modelscope.cn/collections/Qwen3-9743180bdc6b48
体验方式:点击下方链接或打开通义APP
https://chat.qwen.ai/


