Meta这次真的坐不住了,计划在AI上继续加码!
匿名员工爆料,黑马DeepSeek的出现,让Llama 4还未发布就已经落后,Meta慌了。

就在这一消息沸沸扬扬时,小扎放出消息,2025年继续扩大AI投资。
初步规划两方面:算力和人才。
- 投入100亿建设一个2GW规模的数据中心
- AI团队规模将继续扩张
整体支出将达到600-650亿美元(约4347-4709亿人民币)。
与此同时,Meta的内部也出现了人事调整,FAIR团队的大牛田渊栋博士转去了GenAI团队。
虽然还没有大张旗鼓的宣传,但目前田渊栋的X简介已经更新。
DeepSeek让Meta陷入恐慌
虽然小扎在推文中把今年的愿景描绘得一片前程大好,但却有匿名员工爆料,Meta内部已经陷入了恐慌。
在TeamBlind上,工程师爆料称这种恐慌由DeepSeek而起,并且在DeepSeek V3(24年12月末发布)的时候就已经产生。
爆料显示,当时DeepSeek V3就已经让还待字闺中的Llama 4在多个Benchmark当中落后。
这名工程师还补充说,DeepSeek此前名不见经传,训练资金也只有550万美元。
什么概念呢?Meta GenAI团队随便拉个高管,薪资都超过了DeepSeek的总训练成本。
V3上线后,Meta团队开始紧急拆解,试图“复制一切可以复制的东西”。
而这两天新上的推理模型R1进一步加剧了Meta的恐慌,但爆料者对此表示无法提供更多机密信息。

而在评论区,有人表示DeepSeek不仅让Meta感到恐慌,也正在点燃OpenAI、谷歌和Anthropic的战火。

小扎:今年是决定性的一年
在Facebook的推文中,小扎写到,对于人工智能来说,今年将是决定性的一年。
在恐慌的传闻之下,他期待今年META能打造出服务10亿人的领先级助手,还乐观地表示Llama 4有望成为SOTA模型。
同时还会构建一个会写代码的“AI工程师”。
而Meta今年计划的600-650亿美元资本投入,相当于比去年(预计380-400亿美元)增长了超过70%(以380→650计算)。
同时,这一数字也超过了伦敦证券交易所(LSEG)分析师的预测(约502.5亿美元)。
其中,数据中心的建设将占据很大一部分。
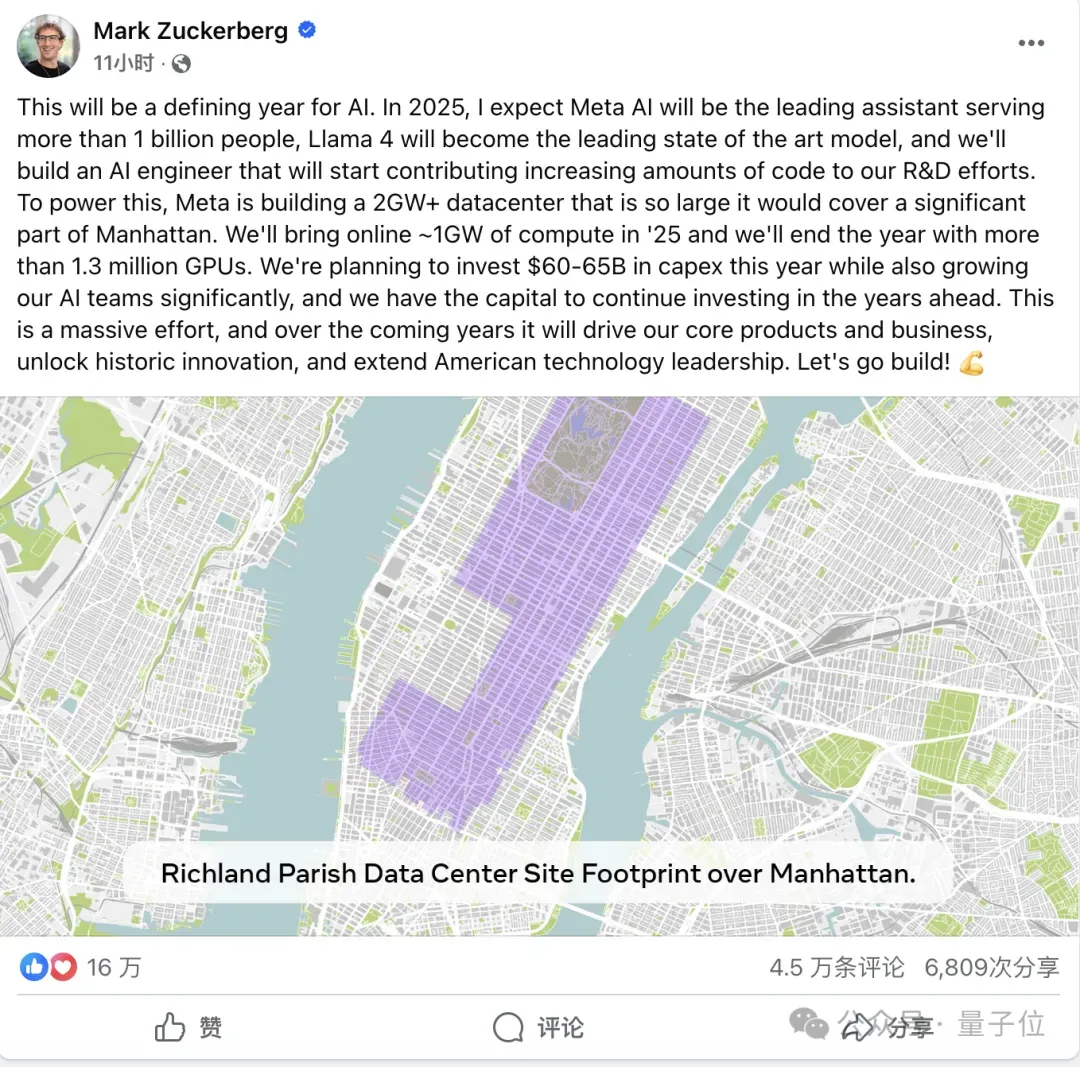
2024年,Meta一共建了6个数据中心,今年还计划在路易斯安那州花100亿美元建一个2GW规模、面积400万平方英尺(约合37万平方米/557亩)的新数据中心。
这个数据中心在上个月已经官宣,预计整个建设工程会持续到2030年,当时美国一家能源公司还提议,在Meta这个数据中心附近建立一座1.5GW的天然气发电厂。
按照小扎最新的说法,Meta今年的目标是拥有130万块GPU,实现1GW在线运算能力。
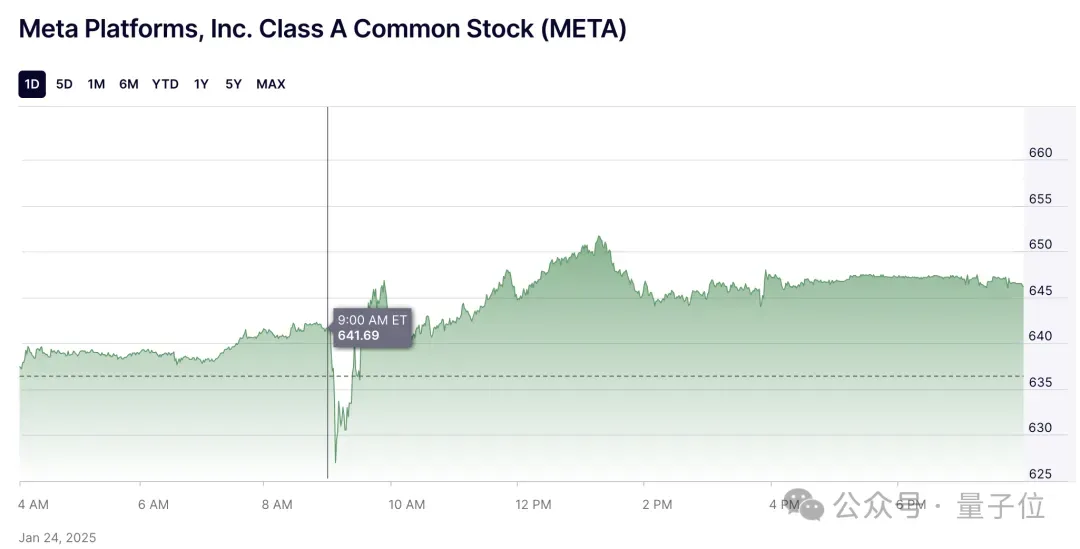
小扎的消息发布后,Meta的股价上涨了1%。
除了Meta,其他一些科技巨头今年也会在数据中心上投入大量资金。
微软总裁布拉德·史密斯(Brad Smith)本月就表示,该财政年度,微软计划在数据中心上花费800亿美元。
马斯克也在田纳西州建设了新的数据中心,并表示将把其规模提升到百万卡级别。
亚马逊也表示,2025年支出会高于2024年的750亿美元。


