跑去隔壁Anthropic的OpenAI联创John Schulman,又又又跳槽了。
《财富》爆料,Schulman新的去向,是加入原OpenAI首席技术官Mira Murati的新创业公司。
此时距离他转投Anthropic,仅仅不到半年。
对此,Mira公司方面拒绝置评,Schulman也尚未给出回应。
但《财富》表示,两名透露此事的消息人士是通过与相关方面的第一手对话得知Schulman的动向的。
Schulman是谁?
即使跳槽去了隔壁的Anthropic,Schulman最为人熟知的身份,依然是OpenAI联合创始人。
离开OpenAI之前,Schulman已经在那里工作了9年,并且当时这是他除了实习之外做过的的唯一一份工作。
甚至加入OpenAI的时候,Schulman还是一名在读博士,师从强化学习大牛、曾经吴恩达的第一批博士生Pieter Abbeel。

他的代表作、也是最高引论文PPO发表于2017年,这是ChatGPT核心技术RLHF中选用的强化学习算法。
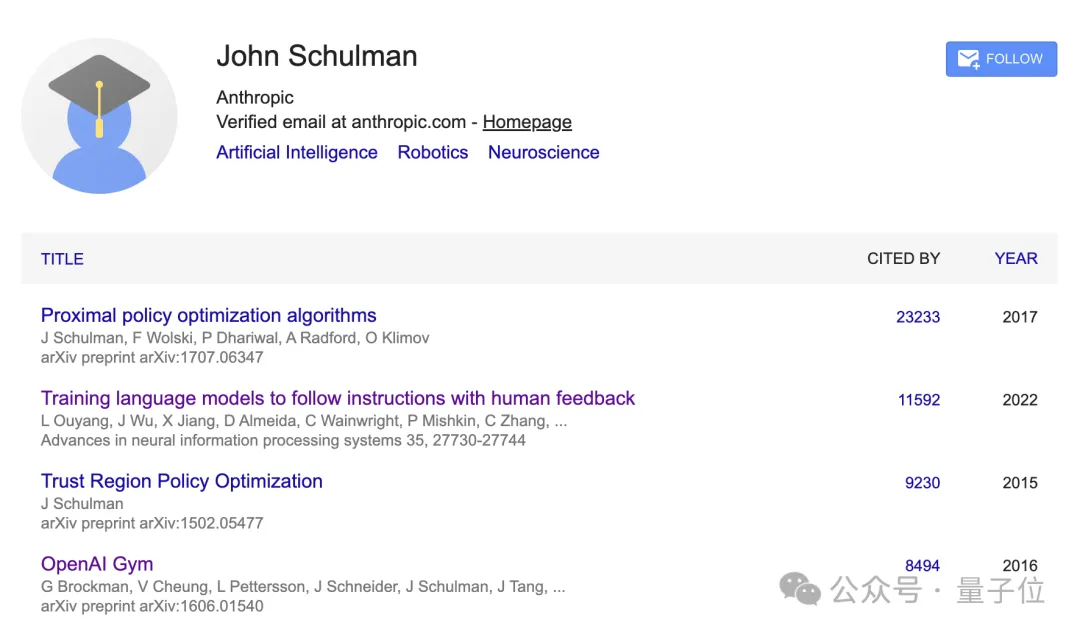
Schulman长年领导OpenAI强化学习团队,被誉为ChatGPT架构师。
后来在从GPT-3.5、GPT-4到GPT-4o的一系列工作中都领导了对齐/后训练团队。
OpenAI前首席科学家Ilya离职后,Schulman还接手了超级对齐团队。
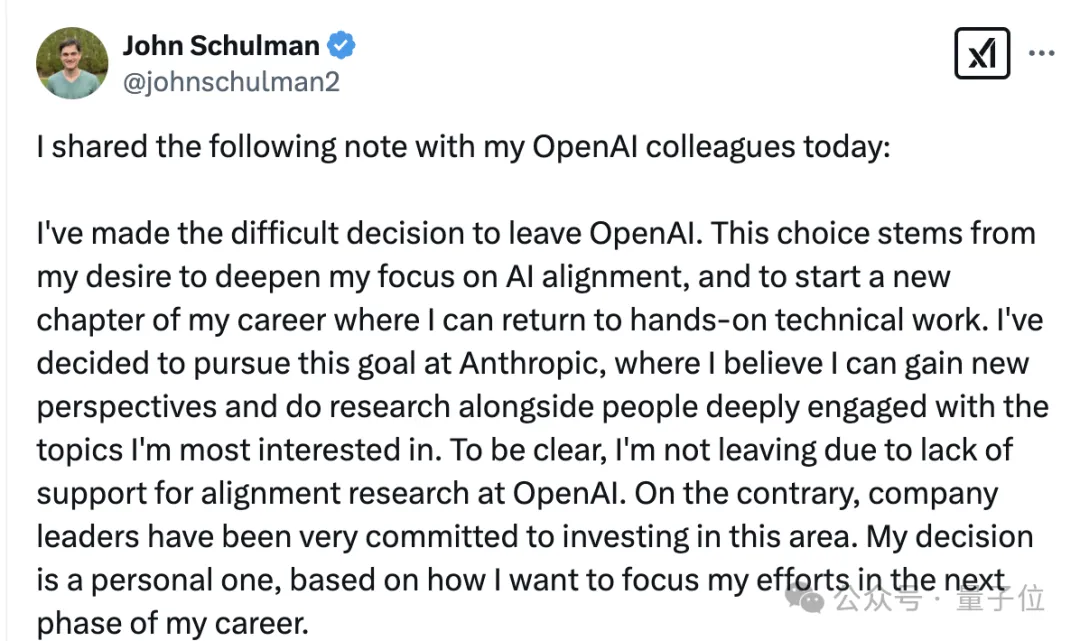
去年8月,Schulman宣布离职并加入隔壁Anthropic,原因是想更深入地关注AI对齐,并重返技术工作。
当时Schulman还专门解释,OpenAI对安全对齐工作并不是缺乏支持。
Schulman的这则消息发布后仅20分钟,奥特曼就在回复中感谢了他的贡献,顺带回忆了两人2015年一家咖啡馆里初次见面时的情景。
并且平时发推只用小写的奥特曼,特意用上了大写字母以表正式。
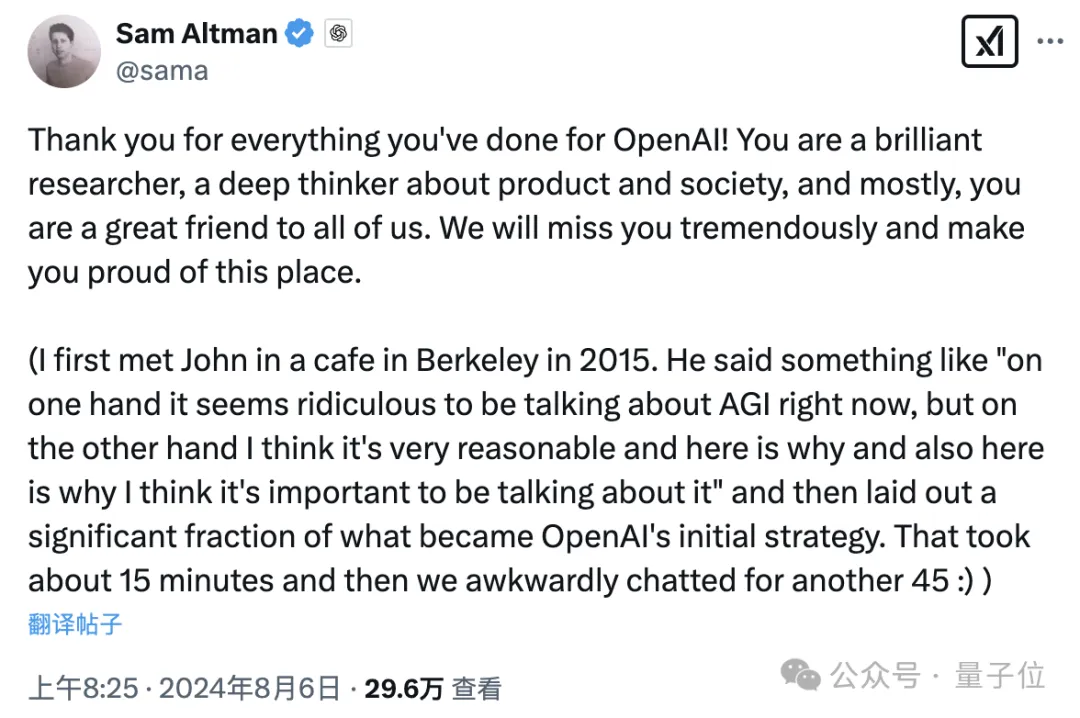
另外,Schulman离职信中除了提及奥特曼和总裁Brockman,还cue到了Mira。
当时Schulman说,Mira和Bob对他十分信任,给了他很多机会并且帮他找到了面对很多困难的办法。

Mira神秘创业公司众星云集
Mira离开OpenAI是在去年9月,给出的解释是“为了给自己创造时间和空间,进行一些个人探索”。
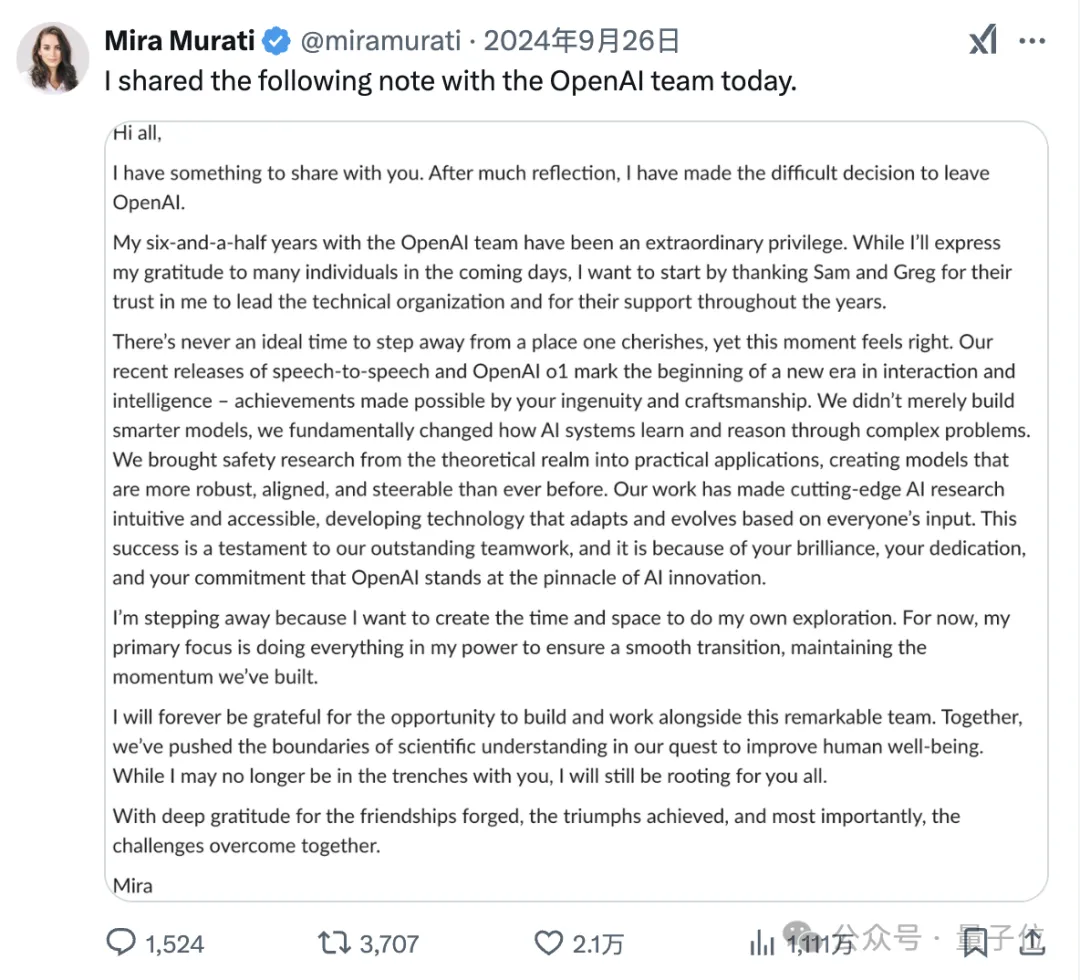
在此之前,Mira在OpenAI负责监督公司的技术战略和产品开发,包括DALL-E、Sora和ChatGPT平台的推出和改进,同时还领导研究和安全团队。
到了10月,Mira就被曝正在筹备新公司/AI实验室,吸金超过1亿美元(约7亿多人民币)。
时至今日,Mira新公司的名字和具体工作内容依然处于未公开状态,只知道是和AGI相关。
但这种神秘并不妨碍Mira的公司吸引大量人才,已经有10余位顶尖研究员和工程师投奔。
而且各个来头不小,分别来自OpenAI、谷歌、Anthropic等AI巨头。
比如OpenAI特别项目负责人Jonathan Lachman,工作内容包括支持各种全公司范围的计划、战略合作伙伴关系和特别项目,直接向奥特曼汇报。
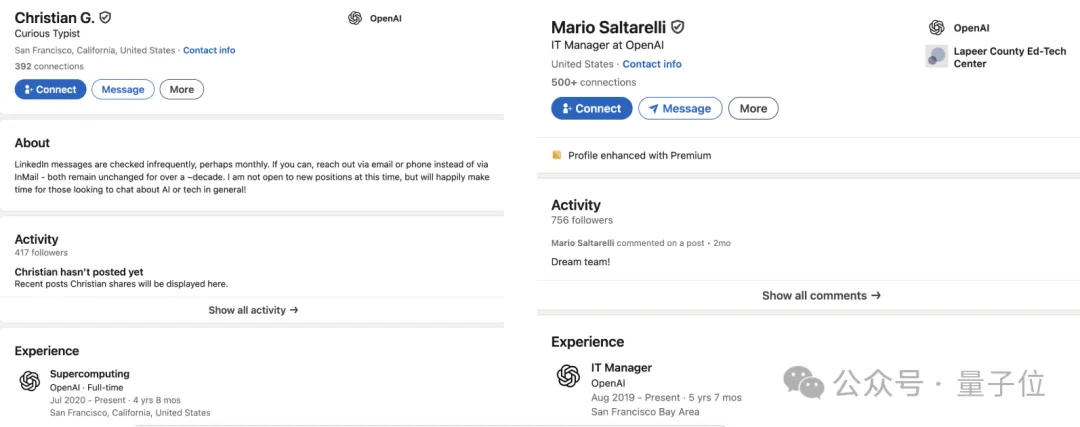
最新消息依然来自《财富》,消息人士透露,OpenAI超级计算团队的Christian Gibson,以及IT经理Mario Saltarelli,也被挖到了Mira的公司。
不过目前,两人的领英资料仍然显示为OpenAI。