最近几周自学deepseek原理+应用+实践,一些成果,和大家分享。
对于deepseek的流弊:
- 小部分人会关心,deepseek为什么这么流弊;
- 大部分人会关心,提示词要怎么写;
今天和大家聊聊,deepseek的核心机制之一的多跳推理,以及如何优化我们的提示词,使得deepseek能够最大化发挥其多跳推理的潜力。

什么是多跳推理?

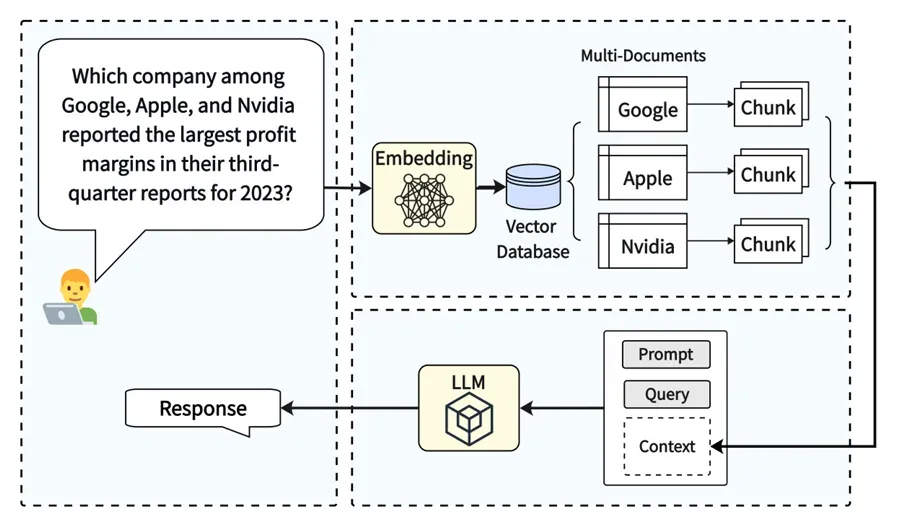
多跳推理,multi-hop reasoning,是模型将不同源中的信息关联,整合与推理的能力。
比较抽象,举个例子。
- 源1:项目A是张三开发的(信息)
- 源2:项目A是李四测试的(信息)
- 源3:项目A是本季度上线的(信息)
- 源4:项目A上线时出现了故障(信息)
提问:本季度绩效谁该背325?(知识)
我们会发现:比拼参数量的大模型,是无法从已有知识中得到提问的答案的,但通过简单推理,将已有的多源信息关联,就能极大提升回答的质量。这就是多跳推理。
人们是怎么想到多跳推理的?
多跳推理最符合人的真实思维。
谁该背325?你是经理你怎么想?
- 第一步,我先看看本季度有没有线上故障;
- 第二步,线上故障是哪个项目;
- 第三步,项目的开发与测试负责人分别是谁;
- 最后,相关负责人背325。
是不是这样?当我们面临一个新的问题时,如果我们脑中的信息没有直接答案,我们就是通过多跳推理,通过信息的关联,一步步找到答案。
这听上去不是很简单吗?
这对我们人来说简单,但对大模型来说就要了命了,信息量十分巨大,两个信息的关联,三个信息的关联,多个信息的关联,即使能够预处理,其计算量也是巨大的。
既然deepseek用了这个技术,我们如何能够最大化发挥deepseek多跳推理的优势呢?
通过提示词显性的告诉deepseek关联关系与关联步骤,而不要让大模型在有限的深度思考里,浪费注意力去探索海量的关联关系。
这也是《让deepseek达到最佳效果的3大原则(第1讲)》里提到的,为什么“系统性”的提示词能极大提升回答的质量,原因就在于此。
再举个例子。
bad case:请帮我定位与修复异常代码。
good case:请帮忙通过以下步骤定位与修复异常代码:
- 查看调用链中的异常信息,定位出错模块
- 查看出错模块的日志信息,定位异常代码的源文件名,函数名
- 分析源文件相关函数
- 修复相关函数
说到底,我们是如何思考与解题的,就显性的用提示词告诉deepseek如何思考与解题,这样能够:
- 极大提升deepseek效率,提升答案深度;
- 增强答案追溯性与逻辑性;
- 提升知识的准确性,而不是让deepseek在有限的深度思考时间里自行探索;
总结
- 多跳推理能极大提升deepseek的回复质量;
- 多跳推理最接近人的真实思维;
- 提示词通过显性告之deepseek关联关系与关联步骤,能够最大化发挥多跳推理的潜力;
一切的一切,提示词只有适配了AI的认知模式,才能最高效的发挥最大的作用。
知其然,知其所以然。
思路比结论更重要。
补充阅读材料:
《Multi-hop RAG》:https://arxiv.org/pdf/2401.15391
PDF,可下载。


