本文经AIGC Studio公众号授权转载,转载请联系出处。
今天给大家介绍一种无需训练的基于扩散模型的高质量设计绘图外观迁移方法LineArt,该方法可以将复杂外观转移到详细设计图上的框架,可促进设计和艺术创作。现有的图像生成技术在细节保留和风格样式一致性方面存在局限,尤其是在处理专业设计图时。LineArt的提出很好的解决了这个问题,因此特别适用于设计图纸的生成。

LineArt工作利用设计图和参考照片来生成相应的结果。
相关链接
- 论文:http://arxiv.org/abs/2412.11519v1
- 项目:https://meaoxixi.github.io/LineArt/
- 代码:https://github.com/YOUR%20REPO%20HERE
论文介绍
 LineArt:一种基于扩散模型、知识引导、无需训练的高质量设计绘图外观转换方法
LineArt:一种基于扩散模型、知识引导、无需训练的高质量设计绘图外观转换方法
线条图的图像渲染在设计中至关重要,图像生成技术可以降低成本,但专业的线条图需要保留复杂的细节。文本提示难以保证准确性,而图像转换则难以保证一致性和细粒度控制。
LineArt是一个将复杂外观转移到详细设计图上的框架,可促进设计和艺术创作。它通过模拟分层视觉认知并整合人类艺术经验来指导传播过程,在保留结构准确性的同时生成高保真外观。LineArt 克服了当前方法在细粒度控制困难和设计图中风格退化的局限性。它不需要精确的 3D 建模、物理属性规范或网络训练,使其更方便完成设计任务。
LineArt 由两个阶段组成:一个多频线融合模块,用于为输入的设计图补充详细的结构信息,以及一个用于基础层成型和表面层着色的两部分绘画过程。我们还提出了一个新的设计图数据集 ProLines 供评估。实验表明,与 SOTA 相比,LineArt 在准确性、真实感和材料精度方面表现更好。
方法
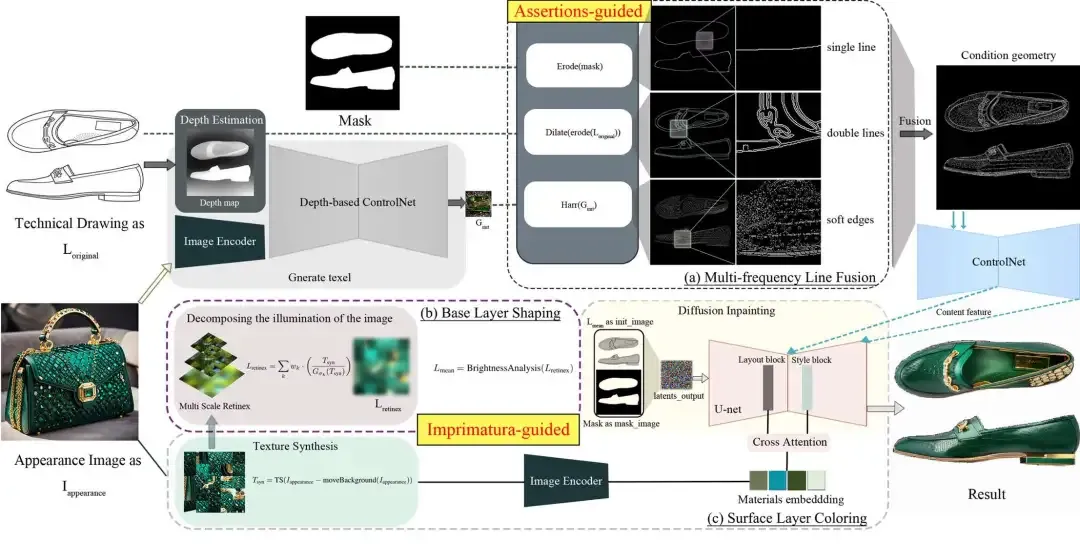
工作流程: 该过程从设计图 L original和外观图像 I appearance开始。基于深度的 ControlNet 估计深度并生成软边缘以指导合成。
- (a)多频线融合模块采用断言引导技术来增强结构细节控制。
- (b)基础层塑造使用多尺度视网膜方法分解外观图像的照明,生成视网膜照明层 L retinex以平衡亮度。
- (c)表面层着色利用 U 网络中的布局和样式块和交叉注意来细化输出,以实现准确的材料嵌入。
ProLine 数据集
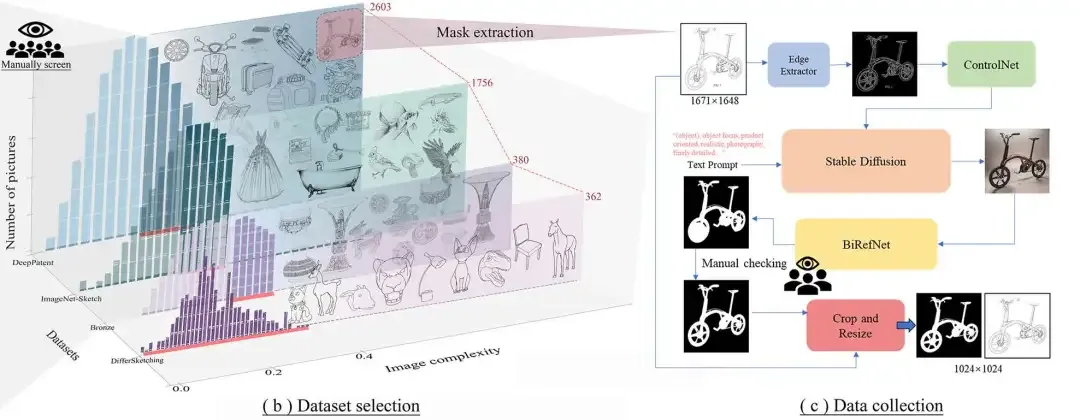 ProLine数据集的构建:
ProLine数据集的构建:
- (b)显示了根据图像复杂度进行初步筛选以及人工去除噪声数据后的数据概览。
- (c)显示了选定数据的数据预处理,包括mask的自动处理过程和三轮人工验证。

经过(b)(c)两个过程得到了5101幅珍贵的线图。
结果


该工作与其他 SOTA 在处理具有精细结构的技术图纸和指定材料的图像的定性结果中进行了比较。从图中可以看出,论文提出的方法可以在保持更精细结构的同时生成更准确的纹理,并且对材料图像具有更合适的颜色表示。

该方法在辅助设计中的应用示例。该方法可以将各种材质纹理与技术图融合,生成丰富的材质效果预览,辅助设计师选择最合适的材质组合进行产品线稿设计。
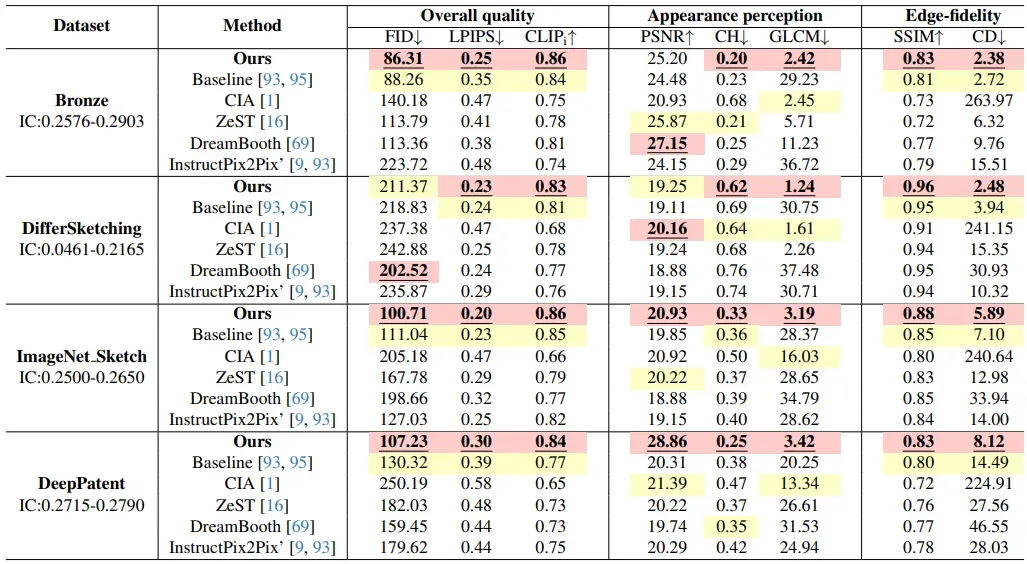
对 ProLines 数据集上不同方法的定量评估。论文使用八个指标从三个维度评估结果的质量。结果表明,该方法在感知质量和准确性之间取得了良好的平衡,特别是在保留图像细节和纹理方面。最佳值以红色突出显示,次佳值以黄色突出显示。


