JetBrains 现已更新旗下“AI Assistant”应用,改进 LM Studio 功能,新增支持调用本地大语言模型,降低开发者对 OpenAI、Anthropic 等云服务的依赖。
AI在线获悉,LM Studio 是 JetBrains 为其“AI Assistant 应用”提供的一项功能,允许开发者下载部署管理 Llama、Mistral 等开源模型,并通过 API 接口对接各类开发工具。而在本次更新后,LM Studio 可以允许开发者直接运行计算机本地的 DeepSeek 等离线模型。

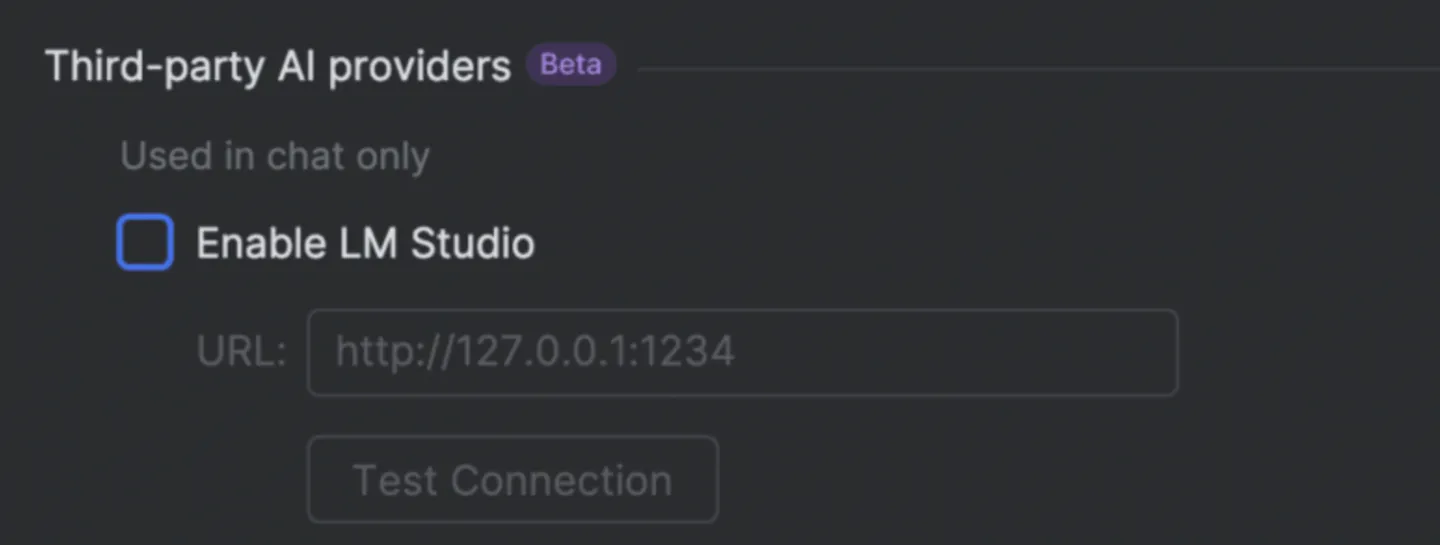
此外,JetBrains 此次更新还为 LM Studio 新增了最新的云端模型,开发者现在可以使用包括 Anthropic 的 Claude 3.5 Sonnet 和 Claude 3.5 Haiku,以及 OpenAI 的 o1、o1-mini 和 o3-mini 等模型。


