
4/2 号时写了一篇 RAGFlow 实现图片问答的原理解析,后续在知识星球内有星友陆续反馈在使用我提供的源码复现时,会出现知识库中能渲染图片,但回答中图片无法正常加载的问题。

知识库预览和引用文件部分是直接展示原始数据或进行简单渲染,它们能正确显示图片,证明原始上传的增强文本中的 URL 是正确的,并且图片服务器和网络配置是通的,问题出在聊天内容生成这个环节。

我当时提供了三种选择选择,分别是:更强的 prompt 指令、更强的 LLM 和”占位符+后处理“的方案,鉴于后续大家反馈前两种效果依然不够稳定,这篇我来系统的分享下如何实现第三种更符合实际生产场景的 RAG 富文本处理方案。
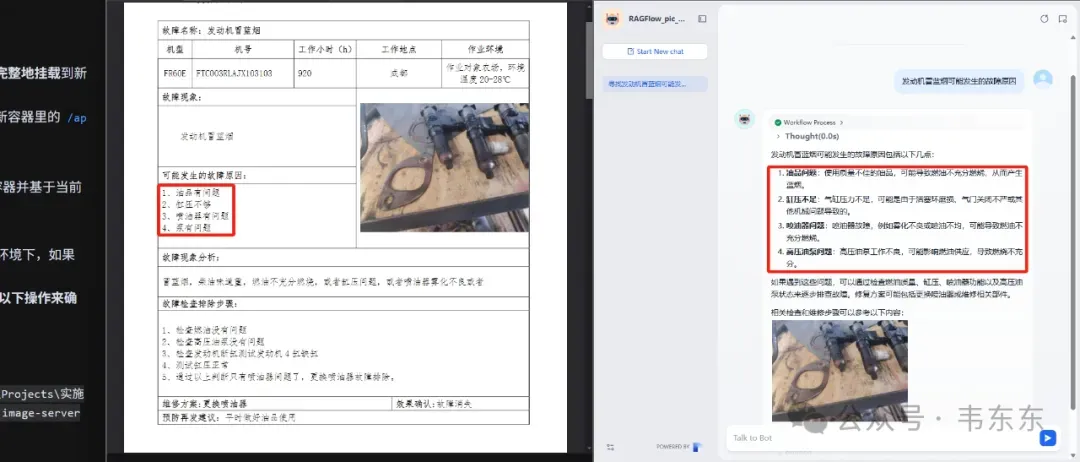
这篇试图说清楚:
占位符方案如何将图片 URL 幻觉问题,从一个难以控制的“语义幻觉”转变为一个相对更容易处理的“格式遵循”问题,从而极大降低图片显示错误的概率。它不是银弹,但通常是处理富文本(图文混排)RAG 中最实用的工程方法之一。
以下,enjoy:
1、占位符方案的好处
LLM 的核心行为是生成文本,而非精确复制特定格式的字符串,尤其是当这些字符串看起来像可解释内容时。
原始问题:
LLM 看到的是`<img src="http://{server_ip}:8000/images/..." alt="..." width="...">`这样的标签,它看起来像是有意义的 HTML 和 URL。LLM 尝试"理解"上下文,并可能基于文本内容(比如“燃油喷射器泄漏图”)重新生成一个它认为更合适的 src(例如改成 .../fuel_injector_leak.png),导致 URL 失效。
占位符方案:
LLM 看到的是 [IMG::page1_img1_uuid.png] 这样的特殊标记。这种格式更像是一个代码片段或元数据标签,而不是自然语言或标准 HTML。LLM 被明确指示(通过 Prompt)要将其视为特殊标记,如果需要引用就原样复制。它"创造性地"修改这种标记的动机和可能性都大大降低了。它不太可能去"理解" page1_img1_uuid.png 并把它改成 fuel_injector_leak.png。
1.1降低 LLM 修改风险
占位符通常是简单的、非描述性的文本字符串(如 [IMG::page1_img1_eef46633] 或类似的格式)。LLM 在生成回答时,更有可能将这些占位符视为需要原样保留的特殊标记或代码片段,而不是像 HTML <img> 标签那样容易被“理解”和“重构”的内容。
1.2解耦内容与表示
将图片的存在(通过占位符表示)与其具体的网络位置(URL)分离。LLM 专注于基于文本内容(包括占位符)生成连贯的回答,而图片渲染的细节则由后续步骤处理。
1.3更强的控制力
通过后处理步骤,我们可以精确地控制最终呈现给用户的 <img> 标签的格式,确保 URL 和其他属性(如 alt, width)的准确性。
2、后处理步骤是关键
这个方案的核心在于,在 LLM 从 RAGFlow 获得包含占位符的回答后,必须有一个后处理步骤。这个步骤负责查找回答中的所有占位符,并使用之前存储的映射关系将其替换回完整的 HTML <img> 标签。大致有以下两种实现方式:
2.1直接使用 ragflow_sdk (不推荐)
优点是,我们可以完全控制整个流程,集成度高。在获取到 chat.answer() 的结果(包含占位符的文本)后,可以立即执行 Python 代码进行替换,然后再将最终结果呈现给用户或传递给下游系统。
缺点也很明显,这种方式通常意味着我们需要自行构建用户界面 (UI) 或者将 RAG 逻辑嵌入到一个更大的后端应用中。标准的 RAGFlow Web UI 是与其自身后端紧密集成的,不太可能直接支持你在调用链中插入自定义的 Python 后处理步骤。而修改 RAGFlow UI 来支持这一点会非常复杂。
2.2使用 Dify 工作流(推荐)
Dify 提供了强大的可视化工作流编排能力,我们可以清晰地看到数据流转。将 RAGFlow 作为知识库(通过其 API)接入,LLM 调用作为另一个节点,而后处理逻辑则封装在 Dify 的 "Code" 节点中,职责清晰。

Dify+RAGFlow:1+1>2的混合架构,详细教程+实施案例
总结来说,通过 Dify 工作流中的 Code 节点实现后处理逻辑是完全可行的,并且可能是更灵活、更易于管理的方案,特别是如果你希望利用现成的或 Dify 提供的 UI 时。
3、映射关系的存储和访问
我们需要一种方便且稳定的方式来存储和检索占位符 -> URL 的映射。 存储环节,在处理 PDF 时,将生成的映射关系与增强文本一起保存,例如存为一个 JSON 文件,其名称与知识库或文档相关联。 检索环节,在进行聊天并需要进行后处理时,需要能够加载与当前知识库/助手相关的映射文件。具体实现上我试过如下三种方式,推荐最后一种。
3.1映射关系作为知识库
这个做法是我最先想到的一种。就是将映射关系保存为 TXT 文件并上传到 RAGFlow 单独知识库,利用 RAGFlow 的 "One" 分块策略来确保整个映射文件作为一个单元被检索,避免了映射关系被分割的问题。
但仔细想了下意识到,实际测试在本地预处理脚本(如 process_pdf.py)运行时,我们无法知道 RAGFlow 将为即将上传的原始文档(例如,从 PDF 生成的增强文本文件)分配的 document_id。 document_id 是在调用 dataset.upload_documents() 之后由 RAGFlow 系统生成的。本地脚本在调用此 API 之前运行,因此无法预先获取这个 ID。
3.2共享文件系统方案
这里需要先解释一个 Docker 卷挂载的概念,这是一种将宿主机(运行 Docker 的机器)上的目录或文件链接到 Docker 容器内部指定路径的机制。它允许容器访问宿主机上的文件,并且宿主机和容器之间的数据是实时同步的(在挂载的目录内)。

当我们运行 process_pdf.py 脚本会生成映射文件 (.json) 并保存在宿主机的一个特定目录下(例如 ~/ragflow_project/mappings)。 Dify 应用在其工作流的 Code 节点里需要读取这些 .json 文件。 通过卷挂载,我们可以把宿主机上的 ~/ragflow_project/mappings 目录映射到 Dify 容器内部的一个路径(例如 /data/mappings)。 这样,Dify 容器内的 Code 节点就可以像访问本地文件一样,通过路径 /data/mappings/{unique_id}.json 来读取映射文件了。
但是这个方案我测试下来没有成功,docker exec 一直显示 "No such file or directory",这意味着在 docker-compose.yaml 中为 api 服务定义的 volume 挂载没有成功。可能是因为 Docker Desktop 正在使用 WSL 2 后端,WSL 2 有更原生的方式访问 Windows 文件系统(通常通过 /mnt/c, /mnt/d 等路径),不再依赖旧的 Hyper-V 文件共享设置。一时半会没研究明白,再加上这并不是一个适合在生产场景使用的方案,就果断弃了。
3.3阿里云 OSS(或其他云对象存储)
在考虑技术方案时,必须充分考虑实际生产场景,尤其是多用户并发访问和部署架构带来的影响。OSS 方案更适合生产环境,原因有以下几点:
- 解耦存储: 将映射文件存储在独立、高可用的云存储中,而不是依赖本地文件系统。
- 避免本地环境问题: 不再受 Windows 路径、WSL 2 挂载、Docker Desktop 配置等本地复杂性的影响。
- 可扩展性好: OSS 可以轻松处理大量文件和高并发访问。
- 部署更简单: Dify 容器不再需要特殊的文件系统挂载,只需要配置好访问 OSS 的网络和凭证即可。阿里云OSS访问地址:https://oss.console.aliyun.com/overview
4、OSS 配置流程
4.1获取 OSS 访问凭证
Access Key ID、Access Key Secret、Endpoint、Bucket Name (你用于存储映射文件的存储桶名称) ,以及一个用于存放映射文件的目录前缀 (例如 mappings/)
4.2交互方式选择
关于 Dify 中 code 节点和 OSS 的交互方式,最初我是默认选择使用 OSS SDK 的方式,结果发现报错:ModuleNotFoundError: No module named 'oss2' ,这说明 Dify 为 Code 节点提供的沙箱环境没有包含阿里云 OSS 的 SDK。这和 Coze 一样是一个常见的限制,沙箱环境通常只包含一组有限的基础库。

所以使用 HTTP Request 节点是快速验证核心逻辑的好方法, 既然 Dify Code 节点无法直接与 OSS SDK 交互,我们可以让 Dify 的 HTTP Request 节点来负责获取映射文件的内容,然后将获取到的内容传递给 Code 节点进行处理。

4.3配置 Bucket 自定义域名
在确定了使用 http 节点访问映射文件后,我们还有个问题需要克服。就是阿里云 OSS 出于安全考虑,对于使用 OSS 默认域名 (如 xxx.oss-cn-shanghai.aliyuncs.com)或传输加速域名访问时,会强制在返回头中增加 x-oss-force-download: true 和 Content-Disposition: attachment。这会导致浏览器或 HTTP 客户端(如 Dify 的 HTTP 节点)强制下载,即使你设置了对象的 Content-Disposition: inline 元数据。

因此 Dify HTTP 节点会将响应体识别为一个文件,因此 body 字段为空,而将文件信息放入了 files 数组中。它实际上已经成功下载了文件内容,只是没有直接放在 body 里。官方推荐的方法是为你的 OSS Bucket 绑定一个你自己的、已备案的域名(正好有一个刚做好 ICP 备案)。

如果你没有备案过的域名,为了完成测试可以使用template节点中直接填写映射关系的内容,实测这样和http节点效果是一致的。
然后要修改 Dify HTTP 节点中的请求 URL,使用这个自定义域名来访问你的 JSON 文件,而不是使用 OSS 的默认域名。 访问通过自定义域名的文件时,OSS 通常会尊重你在对象元数据中设置的 Content-Disposition: inline,从而允许预览而不是强制下载。

在OSS点击域名管理

在域名控制台解析到OSS存储位置
5、工作流解析

文档预处理: 提取 PDF 中的图片和文本。在生成的文本中,用唯一的占位符(例如 [IMG::page1_img1_uuid.png])标记图片的位置,而不是直接插入 <img> 标签。
映射关系存储: 将"占位符"到"实际图片访问 URL"(指向独立的图片服务器)的映射关系保存为一个 JSON 文件,并将其上传到阿里云 OSS 对象存储中,以便后续访问。
独立图片服务: 运行一个独立的 Docker 容器作为图片服务器,负责托管从 PDF 中提取的图片文件,并通过 HTTP 提供访问(例如 http://<your-server-ip>:8000/images/...)。
RAG 流程: RAGFlow 知识库仅存储包含占位符的纯文本。

后端处理 (Dify): 使用 Dify 工作流编排 RAG 查询和 LLM 调用。在 LLM 生成包含占位符的回答后:

使用 Dify 的 HTTP Request 节点从 OSS 获取对应的映射关系 JSON 文件(通过自定义域名访问)。
使用 Dify 的 Code 节点解析 JSON,查找回答中的占位符,并将其替换回完整的 <img> HTML 标签,其 src 指向图片服务器的 URL。
6、QA/故障排除
Q: Dify Code 节点报错 ModuleNotFoundError: No module named 'oss2
A: Dify Code 节点的沙箱环境不包含 oss2 库。解决方案是改用 Dify 的 HTTP Request 节点来获取 OSS 上的映射文件内容(需要文件可公开访问或使用预签名 URL),然后将获取到的字符串内容传递给 Code 节点进行 JSON 解析和处理。
Q: Dify HTTP Request 节点访问 OSS URL 返回空 body,但在 files 数组中有内容
A: 这是因为 OSS 返回了 Content-Disposition: attachment 头,Dify 将其视为文件下载。解决方案是在上传映射文件到 OSS 时(在 process_pdf.py 中),明确设置 headers={'Content-Disposition': 'inline'}。
Q: 浏览器访问图片服务器 URL (http://:8000/images/...) 返回 "Not Found",但 curl http://localhost:8000 成功
A: 这通常是 Docker Volume 挂载问题 (尤其在 Windows/WSL2)。正在运行的 image-server 容器内的 /app/images 没有同步宿主机 ./images 目录的最新内容。解决方案:停止并删除旧的 image-server 容器 (docker stop/rm),然后使用正确的 -v <宿主机绝对路径>:/app/images 参数重新运行 docker run 命令启动新容器。

7、写在最后
7.1残余风险
占位符方案能否完全解决 LLM 幻觉?答案是不能完全保证,但是测试下来能极 大降低特定错误的概率。 需了解的残余风险包括:
- 完全省略占位符: 如果它认为图片不重要或与回答关系不大。
- 轻微修改占位符: 比如不小心加了空格、改变了括号 [ IMG:: ... ],或者截断了文件名。这可能导致后续的 Code 节点正则匹配失败。
- 在错误的位置插入占位符。
7.2、图片分页问题
如何确保图片链接与其所属页面的主要文本内容在同一个块中,并且最好位于该块的开头或明确关联的位置。这个问题我三天前在知识星球专门写过一篇回复,大致有两种方式:

1、改变图片链接的插入时机和位置,图片链接紧随页面开始标记,与该页文本强关联。即使默认分块器在页面中间分割,图片链接也更有可能和页面开头的文本在一起。添加的 --- Page X Start/End --- 分隔符为后续更精细的分块(方案二)打下基础。
2、通过 paragraph_separator="\n--- Page ",强制分块器在页面边界(或你定义的分隔符)处进行切割,最大程度保证页面内容的完整性。
需要确保方案一中的分隔符 --- Page X Start/End --- 能够被 \n--- Page 这个模式匹配到并作为切割点。
7.3正本清源
通过HTTP请求获取并展示图片(例如替换占位符)能够显著提高最终答案的可读性和用户体验,但这属于 RAG 流程末端(生成与呈现) 的优化。输出格式的优化(如加入图片)虽然重要,但属于锦上添花,必须建立在核心检索和生成能力达标的基础上。
而从构建一个高质量、高效率 RAG 项目的基础来看,数据预处理和分块策略优化,绝对是更早期、更核心、也往往是决定 RAG 系统性能上限的关键工作。
后续几篇我会回过头来,从数据预处理(例如 MinerU、Mistral OCR等横评)、动态分块策略进一步写些实践经验。


