
企业在落地 RAG 知识库时, Dify 和 RAGFlow 这两个开源框架应该选择哪个?
这也是我一直以来做RAG咨询时,经常被企业方问到的问题之一。一般来说,如果需要处理特别复杂的文档和非结构化数据,RAGFlow 是优选。而对于需要多模型协作和复杂业务流程的场景,Dify 更为适合。
但这并非是个,非此即彼的问题。
这篇试图说清:
如何将 Dify 作为主框架使用其 agent 和工作流组件,同时通过 API 调用 RAGFlow 的知识库组件。从而将 Dify 的用户友好界面和工作流能力与 RAGFlow 的深度文档处理能力结合起来。
注:除了 Dify+RAGFlow 的组合外,也可以结合具体业务场景选择添加更多开源框架,如 LlamaIndex、LigthtRAG 等。
以下,enjoy:
1、从优势互补说起
1.1 Dify 的主要优势:
易用性高,无需花费大量时间阅读文档就能快速上手
快速部署,可在 30 分钟内部署原型
模块化设计,便于开发者进行二次开发
支持丰富的外部拓展工具和任务流编排,类似 Coze,但拓展性更好
跨知识库检索支持,能自动选择合适的知识库,这点 RAGFlow 目前不支持
1.2 RAGFlow 主要的优势
文件精细解析能力强,在处理 PDF、扫描件、表格等复杂文档方面表现出色
拥有 DeepDoc 技术,可以处理非结构化文档
支持 OCR、内置多种文档切分模板
对延迟敏感的应用时表现出色,可以轻松应对繁重的工作负载
1.3 优势互补的好处
通过 Dify+RAGFlow 的混合架构,可以实现如下好处:
利用 Dify 强大的工作流编排和 Agent 能力构建复杂应用
同时获得 RAGFlow 优秀的文档处理和解析能力
通过 API 集成保持系统的灵活性和可扩展性
2、端口修改的准备工作
2.1 端口概念解析
在 Docker Compose 的端口映射中,格式为 A:B,其中 A 代表宿主机端口,B 代表容器内部端口。因此,80:80 表示宿主机的 80 端口映射到容器的 80 端口,443:443 则表示宿主机的 443 端口映射到容器的 443 端口。通常,容器中的 80 端口就是用来处理 HTTP 请求,而 443 端口处理 HTTPS 请求。

2.2 端口修改
RAGFlow 和 Dify 官方都推荐使用 Docker 部署,为了防止与 Dify 发生端口冲突,建议把 RAGFlow 的宿主机的端口修改为其他值,而保留容器端口不变。比如,可以将 80:80 改为 8080:80,即将原有的 80 端口映射改为 8080(宿主机)对 80(容器);同理,将 443:443 改为 8443:443。

注意修改的是左侧的数字(宿主机端口),但要确保新端口未被其他程序占用。此外,修改后需要保存 docker-compose.yml 文件,并重启容器,使新配置生效。通常可以使用 docker-compose down 和 docker-compose up -d 重新启动服务。
这种方法可以确保你同时部署 Ragflow 和 Dify 时,不会出现宿主机端口冲突,同时内部服务依然使用原有的 HTTP/HTTPS 端口设置。
注:有盆友可能会疑问 Ragflow 和 Dify 都有 Redis 服务,是否也需要对应修改 RAGFlow 的端口号。回答是不用的。Dify 的 Redis 仅仅在内部使用,即其 Redis 容器没有将服务端口映射到宿主机,因此仅供其它容器访问,不会与外部产生端口冲突。
2.3 Dify启动命令修改
因为Docker Compose 使用项目名称来隔离不同的项目环境。 默认情况下,项目名称是docker-compose.yml文件所在目录的名称。由于Ragflow和Dify的docker-compose.yml目录的docker目录下,导致两个服务的容器未能被有效隔离,从而引发冲突。

解决方案也很简单,RAGFlow基础docker服务启动方式不变。但是Dify启动时候要通过﹣p参数显式指定项目名称。参考图示中的docker compose -p dify_docker up -d。

2.4 修改验证
在浏览器中访问 http://localhost:8080 ,检査 RAGFlow 是否正常运行。如果服务正常启动,你应该能够看到 RAGFlow 的 Web 界面。 完成以上步骤后,RAGFlow 的默认端口将从 80 修改为 8080。

需要注意的是,在我上篇介绍的在 RAGFlow 中通过图片服务器容器化实现问答中渲染本地图片的脚本,因为上述修改的 RAGFlow 端口号,所以需要修改 ragflow_build.py中初始化 RAGFlow 客户端的代码,默认 base_url 参数是"http://localhost" , 没有指定端口号。由于已将原来的 80 端口映射修改为 8080:80,现在需要相应更新 base_url 参数。
RAGFlow如何实现图片问答:原理分析+详细步骤(附源码)

需要查看源代码的请移步知识星球,加入后请后台私信我进会员群。
3、详细操作步骤
3.1 URL 配置注意
在 Dify 中配置 RAGFlow 的知识库时,需要在 RAGFlow 的基础 Base url 后增加 “api/v1/dify”,这是 Dify 特定的 API 路径,它承担版本控制、模块划分等作用。当然这也很符合 RESTful 的设计思想。


3.2 创建知识库
完成 Dify 和 RAGFlow 的 API 连接之后,就可以紧接着创建知识库,需要注意的是,需要点击的是“连接外部知识库”这个按钮。下一步会提示需要输入外部知识库 ID,这个信息需要在大家 RAGFlow 对应的知识库页面,在浏览器的地址后缀上能看到完整的 ID 数字,直接复制过来填下。

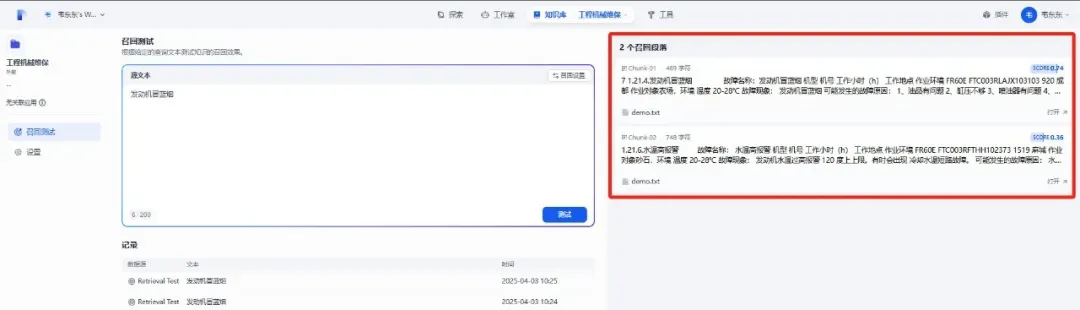
3.3 连通测试
在创建完知识库后,可以大家这个知识库进行召回测试,这个类似 RAGFlow 的检索测试功能,主要是为了检验下上述的两步配置是否成功。需要注意的是,在这一步还不需要配置 LLM 即可进行测试。
3.4 模型供应商配置
在创建具体的 ChatBot 之前,我们需要现在设置页面配置 LLM 的来源。这里既可以选择 Ollama 本地部署的模型,也可以直接选择商业 API。

这里需要提示的是,为了后续更好进行分块和检索策略的调优,如果你的电脑上没有部署DeepSeek-R1-Distill-Qwen-32B或同等水平的开源模型,建议这一步还是先用商业 API。
3.5 创建 ChatBot
这一步很简单,就是输入系统提示词,绑定上述的第二步创建的知识库,再在右上角选择使用的相关模型即可进行问答测试。我这里为了测试效果,输入的提示词和 RAGFlow 中的保持一致,大家可以做个参考。单就 ChatBot 功能,初步测试下来准确率没有明显差别,图片也能正常显示。

但有所不同的是,Dify 中的 ChatBot 提供了更丰富的配置选项。比如为了测试不同问答模型的回答效果,可以同时添加多个 LLM 进行同一个问题的对比回答。但是这个入口其实有点小深,各位参考图示操作。

我这里是测试了 DeepSeek-R1-Distill-Qwen-32B 和 Qwen2.5-32B-Instruct 两个模型,测试了几个问题后,回答速度和效果基本没有明显差别,都还够用。

这里也解释下为啥要用这两个开源模型,虽然我并不推荐中小企业在 POC 阶段刚过早的做 LLM 的本地化部署,但是实际真的要部署这两个尺寸的开源模型也基本够用了。所以我日常在给一些企业方做项目 Demo 的时候也会倾向于直接使用这两款来进行测试,从而保证实际本地部署后的效果一致性。

另外这个 ChatBot 还有个特性是,你可以根据业务需求增加更多的个性化功能,例如 Conversation Opener、Follow-up、Text to Speech、Speech to Text 等,具体大家可以自行测试。需要说明的是,Citations and Attributions 这个回答的出处引用是默认打开的。
4、创建工作流
Dify 中 Studio 模块提供了 Chatbot、Agent、Completion、Chatflow、Workflow 等多种选择,然后在工作流中又包含了很多 Blocks 和 tools 的选项,这些看起来似乎让人眼花缭乱。
4.1 应用类型比较

Chatbot:基础聊天助手,适合简单的问答交互
Chatflow:面向对话类情境,支持多步逻辑和对话历史记忆,包括客户服务、语义搜索等场景
Workflow:面向自动化和批处理场景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等
Agent:智能助手,能自主对复杂任务进行规划、拆解、工具调用和迭代
Chatflow 相比 Workflow 增加了对话特性支持,如对话历史记忆、标注回复和 Answer 节点等。Workflow 则专注于复杂业务逻辑处理,提供丰富逻辑节点和定时/事件触发能力。
4.2 功能块(Block)解析

LLM:核心处理节点,利用大语言模型处理各类任务
Knowledge Retrieval:从知识库检索与用户问题相关的内容
Answer:定义回复内容的格式和展示
Agent:智能助手节点,可自主规划和执行任务
Question Understand:理解用户意图
Question Classifier:对问题进行分类,引导不同处理逻辑
IF/ELSE:条件分支节点,基于条件将工作流分为两个分支
Iteration/Loop:循环处理节点
Code:执行自定义代码逻辑的节点
Template:使用 Jinja2 模板进行数据转换
Variable Aggregator:聚合多分支变量
Parameter Extractor:从自然语言提取结构化参数
4.3 工具(Tool)组件解析

第一方工具:Dify 生态提供的内置工具,如 Audio、Code Interpreter、CurrentTime、WebScraper 等
自定义工具:可导入符合 OpenAPI/Swagger 或 OpenAI Plugin 规范的自定义 API 工具
这些工具可以扩展 LLM 的能力,如联网搜索、科学计算、绘图等,使 AI 应用能连接外部世界。通过自定义工具,还可以实现内容审查、敏感词过滤等功能。有一说一,自定义工具这个很强,后续我考虑专门出一期内容介绍这个。
5、工作流应用示例
泵作为工厂常见通用设备,其突发故障往往会导致整条生产线停摆,造成重大经济损失。下面介绍一个我近期实施过的泵类设备预测性维护智能系统,其中充分利用了 Dify 的各种功能模块和工具节点,整合静态知识库、MCP 链接外部数据源、问答分类和维保报告生成功能。
5.1 系统架构图
复制+----------------------------------+
| 用户界面层 |
| Web界面 | 移动App | 企业微信集成 |
+----------------------------------+
|
+----------------------------------+
| Dify核心平台层 |
| 工作流编排 | Agent | RAG | 知识库 |
+----------------------------------+
| |
+----------------+ +------------------+
| MCP连接层 | | 外部系统集成 |
| 数据收集接口 | | ERP | MES | CMMS |
+----------------+ +------------------+
|
+----------------------------------+
| 设备物联网层 |
| 振动传感器 | 温度传感器 | 压力传感器 |
+----------------------------------+5.2 工作流程设计
A. 状态监控工作流
该工作流通过传感器持续监控泵的振动、温度、压力等参数,使用 IF/ELSE 节点对异常状态进行判断,发现异常时触发告警。
B. 故障预测工作流
将收集的数据与历史故障模式进行比对,使用 LLM 和 Knowledge Retrieval 节点分析数据趋势,预测可能的故障时间和类型。
C. 维保建议工作流
根据预测结果,生成具体的维护建议和计划,包括所需备件、维修时长和最佳维修时间窗口,通过 Template 节点生成标准化工单。
D. 闭环反馈工作流
收集实际维修结果与预测的对比,通过 Agent 节点分析差异并不断优化模型,形成闭环反馈,持续提升预测准确性。
5.3 关键节点配置示例
设备状态监控节点配置:
复制- HTTP Request节点:
接口URL: http://iot-platform/api/pump/status
参数: {"pumpId": "{{pumpId}}", "timeRange": "{{timeRange}}"}
- Code节点(数据处理):
处理振动、温度等数据,计算偏差值
- IF/ELSE节点:
条件: vibration > threshold || temperature > limit
是分支: 触发告警流程
否分支: 正常记录数据故障预测 LLM 节点提示词:
复制系统提示: 你是一位专业的泵类设备故障预测专家。根据以下设备参数和历史数据,分析可能存在的故障风险,预测故障类型和可能的发生时间。
用户输入:
设备ID: {{pumpId}}
当前振动值: {{vibration}}
当前温度: {{temperature}}
当前压力: {{pressure}}
历史故障模式: {{historyFailures}}维保报告生成节点:
复制- Template节点:
设备巡检报告
设备ID: {{pumpId}}
巡检时间: {{inspectionTime}}
设备状态: {{status}}
预测寿命: {{remainingLife}}
异常项:
{% for issue in issues %}
- {{issue.name}}: {{issue.description}}
{% endfor %}
维护建议:
{{maintenanceSuggestions}}
下次计划维护时间: {{nextMaintenanceDate}}6、写在最后
RAG 自从 2020 年由 Meta 提出,23 年春 Nvidia GTC 大会后火热之后,一直面临着来自“微调”和“长上下文 LLM”的对比争议。不过两年下来,共识已经基本形成:
一方面是从成本和实时性角度,RAG 具有压倒性优势,而效果上相差也并不大,即使需要微调介入的场景,RAG 通常也不可或缺。另一方面,长上下文 LLM 依然面临在上下文段落增加时准确率不断下降的事实。所以,在任何情况下,提供高精度的搜索系统(RAG)都是极有价值的,RAG 当前也已经是一种事实上的落地标准架构。


