中国人工智能公司 DeepSeek 的 R1“推理”人工智能已经引起了广泛关注,位居应用商店排行榜首位并改变了股市。随后DeepSeek又宣布开源新一代多模态模型Janus-Pro-7B,该模型在图像生成、视觉问答等任务中全面超越 OpenAI 的 DALL-E 3 和 Stable Diffusion 3,并以“理解-生成双路径”架构和极简部署方案引发AI社区轰动。
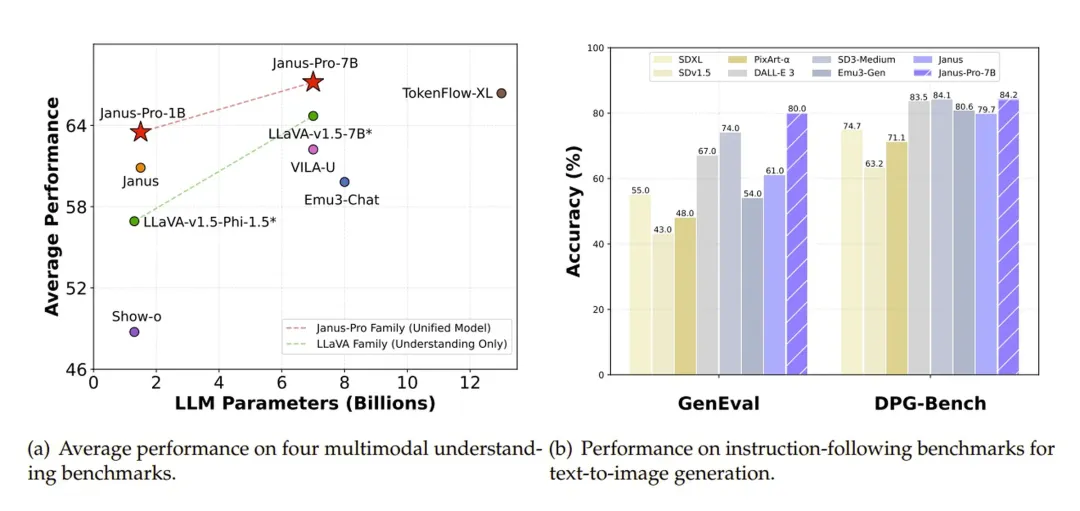

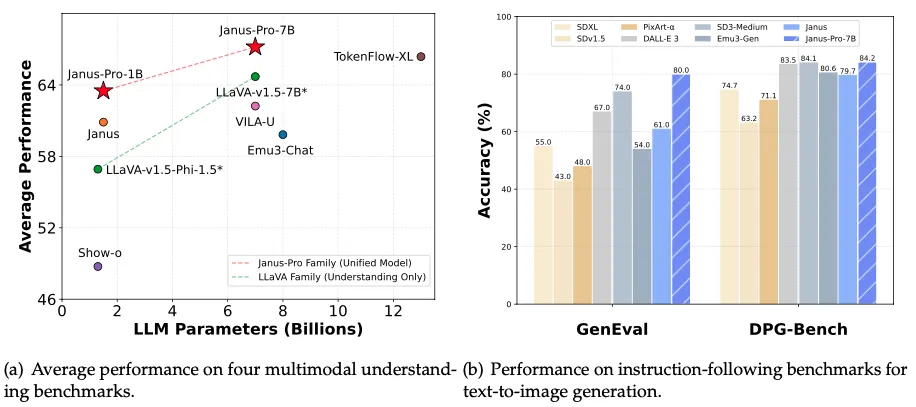
性能表现:小模型吊打行业巨头

Janus-Pro-7B虽仅有70亿参数(约为GPT-4的1/25),却在关键测试中碾压对手:
- 文生图质量:在GenEval测试中以80%准确率击败DALL-E 3(67%)和Stable Diffusion 3(74%)
- 复杂指令理解:在DPG-Bench测试中达84.19%准确率,能精准生成如“山脚下有蓝色湖泊的雪山”等复杂场景
- 多模态问答:视觉问答准确率超越GPT-4V,MMBench测试得分79.2分接近专业分析模型
技术突破:像“双面神”分工协作
传统模型让同一套视觉编码器既理解图片又生成图片,如同让厨师同时设计菜单和炒菜。Janus-Pro-7B创新地将视觉处理拆分为两条独立路径:
- 理解路径:用SigLIP-L视觉编码器快速提取图片核心信息(如“这是一只橘猫在沙发上”)
- 生成路径:通过VQ分词器将图像分解为像素点阵,像拼乐高一样逐步绘制细节(如毛发纹理、光影效果) 这种“分头行动”的设计解决了传统模型的角色冲突问题,训练时还混合了7200万张合成图像与真实数据,提升生成稳定性。
开源与商业使用
- 免费商用:采用MIT开源协议,允许无限制商业使用
- 极简部署:提供1.5B(需16GB显存)和7B(需24GB显存)版本,普通显卡即可运行
- 一键生成:官方提供Gradio交互界面,输入generate_image(prompt="夕阳下的雪山", num_images=4)即可批量出图
相关链接
- GitHub仓库:https://github.com/deepseek-ai/Janus
- 模型下载:https://huggingface.co/deepseek-ai/Janus-Pro-7B
应用场景:从艺术到隐私保护
- 创意产业:设计师输入文本生成海报原型,游戏开发者快速构建场景素材
- 教育工具:教师用模型生成火山喷发动态示意图辅助地理教学
- 企业隐私:医院、银行可本地部署,避免患者病历、金融数据上传云端
- 文化传播:能识别全球地标并生成带文化符号的图片


