应用
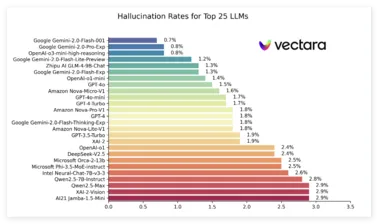
AI大语言模型幻觉排行榜:Gemini 2.0 Flash幻觉最低
近日,Vectara 发布了一份名为 “幻觉排行榜” 的报告,比较了不同大型语言模型(LLM)在总结短文档时产生幻觉的表现。 这份排行榜利用了 Vectara 的 Hughes 幻觉评估模型(HHEM-2.1),该模型定期更新,旨在评估这些模型在摘要中引入虚假信息的频率。 根据最新数据,报告指出了一系列流行模型的幻觉率、事实一致性率、应答率以及平均摘要长度等关键指标。
2/20/2025 9:14:00 AM
AI在线

谷歌将Gemini从iOS主应用撤出,押注独立应用战略
谷歌日前宣布一项重大战略调整:将其人工智能助手Gemini从iOS版谷歌主应用中完全移除,转而推广其独立应用。 这一决策意在加强与ChatGPT、Claude等竞争对手的直接较量,但同时也面临着用户流失的风险。 据悉,谷歌已通过电子邮件向用户发出通知,明确表示"Gemini不再在谷歌应用中可用"。
2/20/2025 9:13:00 AM
AI在线
谷歌圈选即搜登陆苹果 iPhone,让信息触手可及
谷歌为iPhone用户推出“Screen Search”功能,用户只需圈选内容即可启动谷歌搜索,无需切换屏幕。该功能位于屏幕左下角菜单,适用于Chrome和Google应用,本周推出。#谷歌新功能# #科技便捷#
2/20/2025 9:03:29 AM
故渊
昆仑万维旗下Opera接入DeepSeek R1模型 支持本地个性化部署
2月17日,昆仑万维旗下的Opera团队在Opera Developer中接入了DeepSeek R1系列模型,实现了本地个性化部署。 这一举措标志着Opera在AI技术应用方面的进一步拓展,为用户提供了更强大的本地AI功能。 Opera在2024年率先将内置本地大语言模型(LLM)引入Web浏览器,为用户提供了超过50种LLM的访问权限。
2/20/2025 8:58:00 AM
AI在线

智谱清影与AI角色创作平台“捏Ta”开展多模态合作 推动IP一致性落地
2月19日,北京智谱华章科技有限公司宣布,其旗下的多模态创作平台“清影”与AI角色创作平台“捏Ta”达成战略合作,共同探索AI角色设计到动画创作的完整路径,并推动IP一致性的技术落地。 此次合作旨在深入挖掘二次元用户需求与AI应用场景,为用户提供更高质量的生成效果和更快的推理速度。 “清影”基于智谱最新升级的视频生成大模型CogVideoX-2,在模型结构、训练方法和数据工程上进行了全面更新,图生视频基础模型能力大幅提升38%。
2/20/2025 8:55:00 AM
AI在线
腾讯深度思考模型「混元T1」面向所有用户开放
腾讯宣布其深度思考模型“混元T1”正式面向所有用户开放,用户可以通过腾讯元宝平台体验并测试该模型。 此前,混元T1开启灰度测试后,受到了用户的广泛关注和积极反馈。 为了满足用户需求,腾讯紧急部署,现已实现混元T1的全面开放,所有用户均可无限量使用。
2/20/2025 8:51:00 AM
AI在线

谷歌推出“AI 实验室助理”:能推理分析、提出假设、优化方案
谷歌表示,在一项关于肝纤维化的实验中,这个“助理”提出的所有方法都展现了抑制疾病原因的潜力,且活性表现十分积极。
2/20/2025 8:30:53 AM
清源

iPhone 16e配备8GB内存 苹果智能四月将增加中文支持
今日,苹果正式发布了新款手机iPhone16e,并确认了其内存配置。 据悉,iPhone16e搭载了8GB的运行内存,这一配置与市场预期相符,也满足了Apple Intelligence功能的最低要求。 这一升级不仅提升了iPhone16e的性能,也为用户带来了更加流畅的使用体验。
2/20/2025 8:29:00 AM
AI在线

谷歌推出全新工具“职业梦想家”:用 AI 帮你找到理想工作
谷歌发布实验性AI工具Career Dreamer,通过分析用户的经历、技能和兴趣,帮助求职者塑造职业故事、探索职业可能性,并推荐匹配的职业路径。该工具还能生成职业身份声明,助力简历和求职信撰写。#AI求职 #谷歌新工具
2/20/2025 8:23:34 AM
远洋

口袋 AI 设备 Rabbit R1 变身“智能体”:控制设备帮你搜索、整理食谱
该智能体能够完成查找YouTube视频,或自行在食谱App中找到威士忌鸡尾酒的做法并收集所需食材,再将其添加到Google Keep购物清单中。
2/20/2025 7:51:17 AM
清源

DeepSeek 被曝首次考虑进行外部融资,巨头阿里巴巴有意参投
外媒 The Information 报道提到,由于其 AI 模型大受欢迎,因而要增加资源投放以满足明显增加的需求,所以促成内部讨论引入更多投资者。
2/20/2025 1:26:23 AM
汪淼

开局一张图、后续游戏画面全靠 AI 编,微软首发生成式 AI 工具 Muse 登上《自然》
《自然》杂志今日发表了微软最新的研究,该研究介绍了第一个世界与人类行动模型(WHAM),微软将其命名为“Muse”,是一个能够生成游戏视觉、控制器动作的视频游戏生成式 AI 模型。
2/20/2025 12:53:38 AM
汪淼

DeepSeek服务器繁忙?实测30个接入平台,28个快速直达!
一、现象级表现. DeepSeek 自发布以来,热度直逼两年前 ChatGPT 横空出世的时候。 英伟达、亚马逊、微软等巨头率先接入,国内厂商也迅速跟进。
2/20/2025 12:35:33 AM
AI设计师Lena

威迈尔 VMR 机器人控制器 MC600 发布,支持 CAN、RS485、RS232 及千兆网口
威迈尔今日正式发布 VMR-MC600 机器人控制器,其面向轮式移动机器人开发,适配各类轮式底盘移动机器人,包括:搬运机器人、无人叉车、清洁机器人、服务机器人、巡检机器人和人形机器人。
2/19/2025 11:13:43 PM
归泷(实习)
昆仑万维旗下 Opera 接入 DeepSeek R1 模型,支持本地个性化部署
Opera 在 2024 年将内置本地大语言模型(LLM)引入 Web 浏览器,提供超 50 种 LLM 的访问权限。Opera Developer 利用 Ollama 框架(由 llama.cpp 实现)支持了 DeepSeek R1 系列模型部署。
2/19/2025 10:13:41 PM
归泷(实习)

联发科推出两款多模态轻量级 AI 模型:主打繁体中文处理能力、基于 Meta Llama 3.2 打造而成
联发科创新基地(MediaTek Research)现已发布两款支持繁体中文的轻量级多模态模型,分别是号称可在手机上运行的 Llama-Breeze2-3B 模型和适用于轻薄笔记本电脑的 Llama-Breeze2-8B 模型。
2/19/2025 8:10:43 PM
漾仔

DeepSeek 清华原版宝典:工作、学习、生活、科研中的难题,轻松搞定
这次给大家分享的 PDF 下载,是原汁原味的原版哦,网上有太多卖课者魔改的内置其广告版本。
2/19/2025 8:03:48 PM
泓澄
腾讯元宝:混元 T1 深度思考模型面向所有用户不限量开放使用
腾讯元宝本月(2 月 13 日)宣布 DeepSeek R1 模型联网、满血上线。其支持对用户的提问进行深度思考、逻辑推理和详细回答,同时也支持联网搜索信息,以提高推理和回答的时新性和权威性。
2/19/2025 7:12:15 PM
问舟
资讯热榜
标签云
人工智能
OpenAI
AIGC
AI
ChatGPT
AI绘画
DeepSeek
数据
模型
机器人
谷歌
大模型
Midjourney
智能
用户
开源
学习
GPT
微软
Meta
图像
AI创作
技术
论文
Stable Diffusion
马斯克
Gemini
算法
蛋白质
芯片
代码
生成式
英伟达
腾讯
神经网络
研究
计算
Anthropic
3D
Sora
AI for Science
AI设计
机器学习
开发者
GPU
AI视频
华为
场景
人形机器人
预测
百度
苹果
伟达
Transformer
深度学习
xAI
模态
字节跳动
Claude
大语言模型
搜索
驾驶
具身智能
神器推荐
文本
Copilot
LLaMA
算力
安全
视觉
视频生成
训练
干货合集
应用
大型语言模型
科技
亚马逊
智能体
DeepMind
特斯拉