工程

扩散LLM推理用上类GRPO强化学习!优于单独SFT,UCLA、Meta新框架d1开源
当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能。 不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。 与此同时,离散扩散大语言模型(dLLM)成为有潜力的语言建模的非自回归替代。
4/20/2025 2:34:00 PM
机器之心
语音合成突破:F5R-TTS首次实现非自回归模型的GRPO优化,零样本克隆性能显著提升
在人工智能技术日新月异的今天,语音合成(TTS)领域正经历着一场前所未有的技术革命。 最新一代文本转语音系统不仅能够生成媲美真人音质的高保真语音,更实现了「只听一次」就能完美复刻目标音色的零样本克隆能力。 这一突破性进展的背后,是大规模语音数据的积累和大模型技术的快速发展。
4/20/2025 10:13:00 AM
机器之心

RSS 2025|ConRFT: 真实环境下基于强化学习的VLA模型微调方法
本文第一作者为陈宇辉,中科院自动化所直博三年级;通讯作者为李浩然,中科院自动化所副研;研究方向为强化学习、机器人学习、具身智能。 视觉-语言-动作模型在真实世界的机器人操作任务中显示出巨大的潜力,但是其性能依赖于大量的高质量人类演示数据。 由于人类演示十分稀缺且展现出行为的不一致性,通过监督学习的方式对 VLA 模型在下游任务上进行微调难以实现较高的性能,尤其是面向要求精细控制的任务。
4/18/2025 12:05:00 PM
机器之心
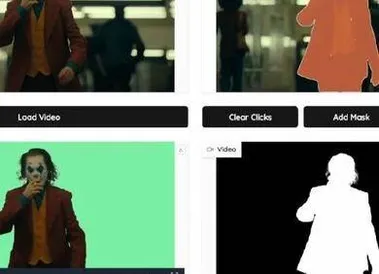
CVPR 2025|视频抠图MatAnyone来了,一次指定全程追踪,发丝级还原
本文由南洋理工大学和商汤科技联合完成。 第一作者杨沛青为南洋理工大学 MMLab@NTU 在读博士生,在 CVPR、NeurIPS、IJCV 等国际顶级会议与期刊上发表多篇研究成果。 项目负责作者为该校研究助理教授周尚辰和校长讲席教授吕建勤。
4/17/2025 8:37:00 PM
机器之心

4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。 对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。 然而,当前视觉模型预训练很难提升到更高的分辨率,核心原因在于计算代价过于高昂。
4/17/2025 12:12:00 PM
机器之心

从思考到行动:大模型自主工具调用能力的深度实现
本项目由复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员领导,博士生韩槿一,硕士生李廷云、熊程元、姜子上、王昕奕等同学共同参与完成。 GPT - 4o、Deepseek - R1 等高级模型已展现出令人惊叹的「深度思考」能力:理解上下文关联、拆解多步骤问题、甚至通过思维链(Chain - of - Thought)进行自我验证、自我反思等推理过程。 但是,多数主流模型仍在基础问题上犯错,复杂四则运算计算失误,简单「两个小数比大小」出错、甚至连数清楚 strawberry 里有几个「r」都能翻车……即使提示像 R1 这样具备深度思考能力的大模型也要消耗大量的 token 才能勉强答对。
4/17/2025 10:43:00 AM
机器之心

JHU提出最强ToM方法,AutoToM横扫五大基准
本文有三位共同第一作者,分别为 Zhining Zhang(张芷宁)、Chuanyang Jin(金川杨)、Mung Yao Jia。 他们在约翰霍普金斯大学 Social Cognitive AI Lab 共同完成这篇论文。 本文的指导老师为 Tianmin Shu(舒天民),是 JHU Social Cognitive AI Lab 的主任。
4/16/2025 5:31:00 PM
机器之心

ICLR 2025 | 一行代码!FreDF频域损失稳定提升时间序列预测精度
本文由浙江大学、中南大学、上海交通大学、Tiktok、北京大学、南洋理工大学联合完成。 第一作者王浩为浙江大学硕博连读生,发表NeurIPS、ICLR、KDD、WWW、TOIS等顶级会议和期刊十余篇。 通讯作者为北京大学李昊轩助理研究员和南洋理工大学陶大程教授。
4/15/2025 8:59:00 PM
机器之心
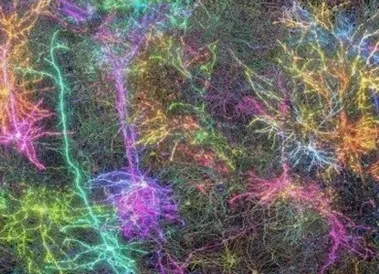
迄今为止最大、最详细的哺乳动物脑连接图,详细展现海量神经元活动
编辑 | 菠菜研究人员通过绘制小鼠脑组织中一立方毫米内的细胞图谱,绘制出了迄今为止最大、最详细的哺乳动物脑连接图。 这项里程碑式的成就还首次在神经科学领域展现了单个神经元的大规模活动。 这张高分辨率 3D 地图包含超过 20 万个脑细胞,其中包含约 8.2 万个神经元。
4/15/2025 2:51:00 PM
ScienceAI

合成数据助力视频生成提速8.5倍,上海AI Lab开源AccVideo
虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。 这个过程既耗时又耗计算资源。 例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
4/14/2025 6:08:00 PM
机器之心

中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理
本文第一作者为邓慧琳,中国科学技术大学硕博连读四年级,研究方向为多模态模型视觉理解、推理增强(R1强化学习)、异常检测。 在TAI、TASE、ICCV等期刊和顶会发表论文。 近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。
4/14/2025 1:37:00 PM
机器之心

3710亿数学tokens,全面开放!史上最大高质量开源数学预训练数据集MegaMath发布
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。 近日,LLM360 推出了 MegaMath:全球目前最大的开源数学推理预训练数据集,共计 3710 亿(371B)tokens,覆盖网页、代码和高质量合成数据三大领域。 报告标题:MegaMath: Pushing the Limits of Open Math Corpora技术报告:: 代码: DeepSeek-Math Corpus(120B)的开源数据集,更代表从「只靠网页」到「面向推理」的重大跨越。
4/13/2025 3:05:00 PM
机器之心

扩散模型奖励微调新突破:Nabla-GFlowNet让多样性与效率兼得
本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。 此论文已收录于 ICLR 2025。 在视觉生成领域,扩散模型(Diffusion Models)已经成为生成高质量图像、视频甚至文本的利器。
4/13/2025 2:55:00 PM
机器之心

面对杂乱场景,灵巧手也能从容应对!NUS邵林团队发布DexSinGrasp基于强化学习实现物体分离与抓取统一策略
本文的作者均来自新加坡国立大学 LinS Lab。 本文的共同第一作者为新加坡国立大学实习生许立昕和博士生刘子轩,主要研究方向为机器人学习和灵巧操纵,其余作者分别为硕士生桂哲玮、实习生郭京翔、江泽宇以及博士生徐志轩、高崇凯。 本文的通讯作者为新加坡国立大学助理教授邵林。
4/12/2025 3:47:00 PM
机器之心

传统预训练正走向终结,推理优化与后训练提升有限,大模型今后如何突破发展瓶颈?
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈? 当前(多模态)大模型正深陷「数据饥渴」困境:其性能高度依赖预训练阶段大量高质量(图文对齐)数据的支撑。 然而,现实世界中这类高价值数据资源正在迅速耗尽,传统依赖真实数据驱动模型能力增长的路径已难以为继。
4/11/2025 10:49:00 PM
机器之心

IC-Light的视频版本来了,RelightVid:强光动态环境下的视频光照编辑神器
大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗? 今天,来自复旦大学、上海交通大学、浙江大学、斯坦福大学等机构的学者们正式宣布:IC-Light 的视频版本来了——RelightVid! 论文标题:RelightVid: Temporal-Consistent Diffusion Model for Video Relighting论文链接::: 、光影真实、支持强光动态场景的高质量视频光照编辑,彻底打开下一代视频重光照的新篇章!
4/11/2025 11:15:00 AM
机器之心

CVPR 2025 | 2D 大模型赋能3D Affordance 预测,GEAL助力可泛化的3D场景可交互区域识别
GEAL 由新加坡国立大学的研究团队开展,第一作者为博士生鲁东岳,通讯作者为该校副教授 Gim Hee Lee,团队其他成员还包括孔令东与黄田鑫博士。 主页:::,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。 所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。
4/10/2025 4:20:00 PM
机器之心

闭环端到端精度暴涨19.61%!华科&小米汽车联手打造自动驾驶框架ORION,代码将开源
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。 虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。 除此之外,现有的方法常常通过叠加多帧的图像信息完成时序建模,这会受到 VLM 的 Token 长度限制,并且会增加额外的计算开销。
4/10/2025 4:08:00 PM
机器之心
资讯热榜
标签云
人工智能
OpenAI
AIGC
AI
ChatGPT
AI绘画
DeepSeek
数据
机器人
模型
谷歌
大模型
Midjourney
智能
开源
用户
学习
GPT
微软
Meta
图像
AI创作
技术
论文
Stable Diffusion
Gemini
马斯克
算法
蛋白质
芯片
生成式
代码
英伟达
腾讯
神经网络
研究
计算
Anthropic
Sora
3D
AI for Science
AI设计
机器学习
GPU
开发者
AI视频
场景
华为
预测
人形机器人
百度
苹果
伟达
Transformer
深度学习
xAI
模态
字节跳动
Claude
大语言模型
搜索
具身智能
驾驶
神器推荐
文本
Copilot
LLaMA
算力
安全
视觉
视频生成
干货合集
应用
训练
大型语言模型
科技
亚马逊
特斯拉
2024
AGI