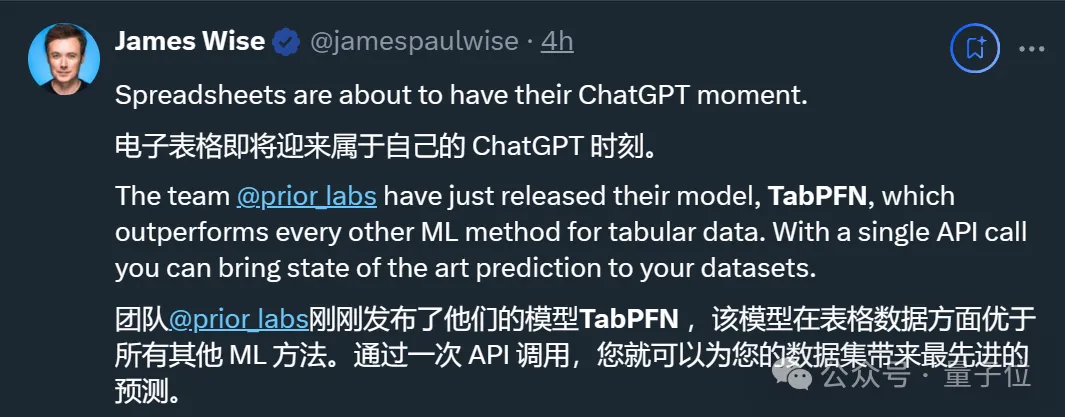
电子表格也迎来了自己的ChatGPT时刻。
就在这两天,一个名为TabPFN的表格处理模型登上Nature,随后在数据科学领域引发热烈讨论。
 图片
图片
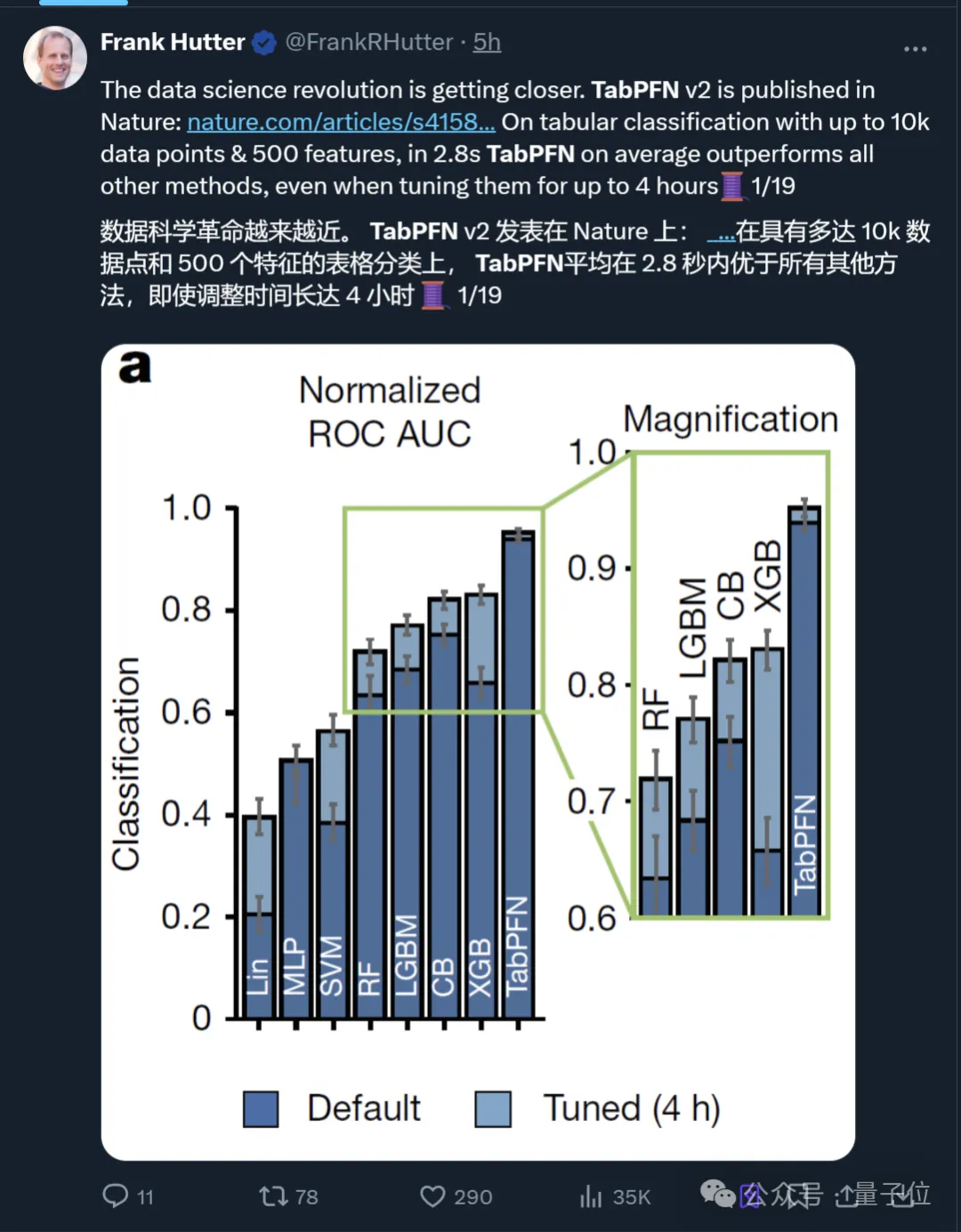
据论文介绍,TabPFN专为小型表格而生,在数据集样本量不超过10,000时性能达到新SOTA。
具体而言,它在平均2.8秒内就能取得比之前所有方法更好的结果。
甚至即便其他方法拥有长达4小时的“整顿”时间,也还是比不过。
 图片
图片
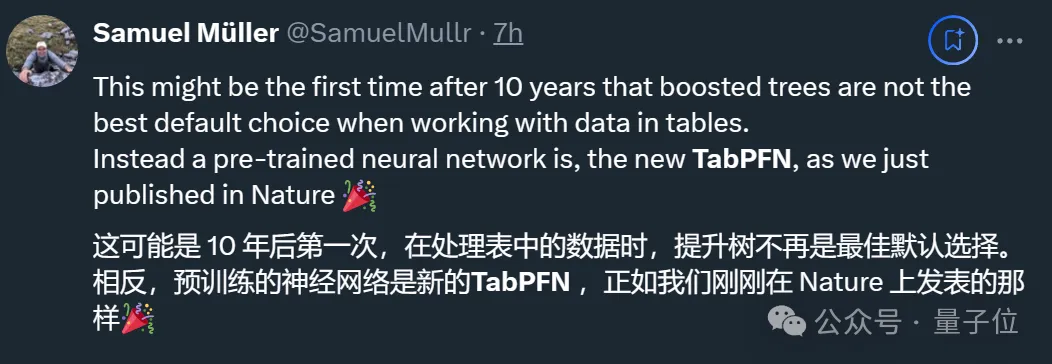
更主要的是,它所采用的预训练神经网络方法彻底终结了传统ML(如梯度提升树)在表格领域的统治地位。
 图片
图片
 图片
图片
目前TabPFN开箱即用,无需专门训练即可快速解读任何表格。
开箱即用的表格处理模型
在Nature的另一篇文章中,传统表格机器学习的局限性被提及。
比如针对以下常见应用场景:
假如你经营着一家医院,想要判断哪些患者病情恶化风险最高,以便医护人员能优先照料,你可以创建一个电子表格,每行对应一位患者,列则记录年龄、血氧水平等相关属性,最后一列标注患者住院期间是否病情恶化。接着,用这些数据拟合数学模型,就能预估新入院患者的病情恶化风险。
在这个例子里,传统表格机器学习利用数据表进行推断,这通常需要针对每个任务开发和训练定制模型。
而来自德国弗莱堡大学ML实验室等机构的研究人员,所推出的TabPFN做到了无需专门训练即可处理任意表格。
 图片
图片
而且据作者们声称,本次发布的TabPFN v2相比两年前的初代版本有了很大升级。
当时的TabPFN v1被认为“可能会彻底改变数据科学”,而现在:
我们离这一目标又更进了一步。
 图片
图片
概括而言,v2版本改进了分类能力,并扩展了功能以支持回归任务,其在回归任务上的性能也优于经过长时间调优的基线模型。
 图片
图片
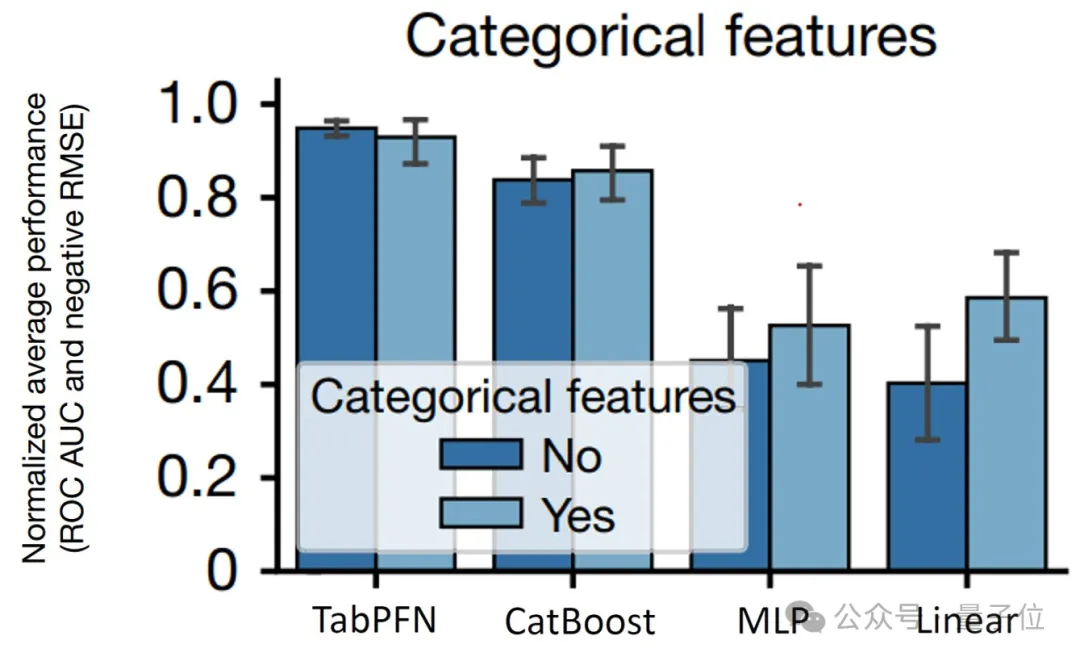
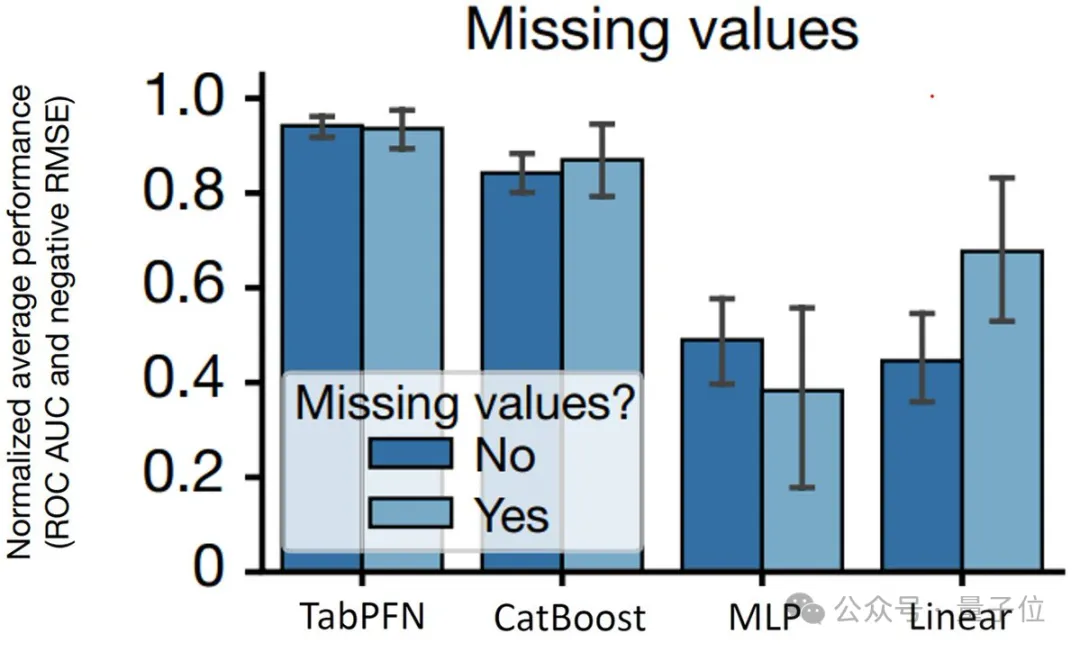
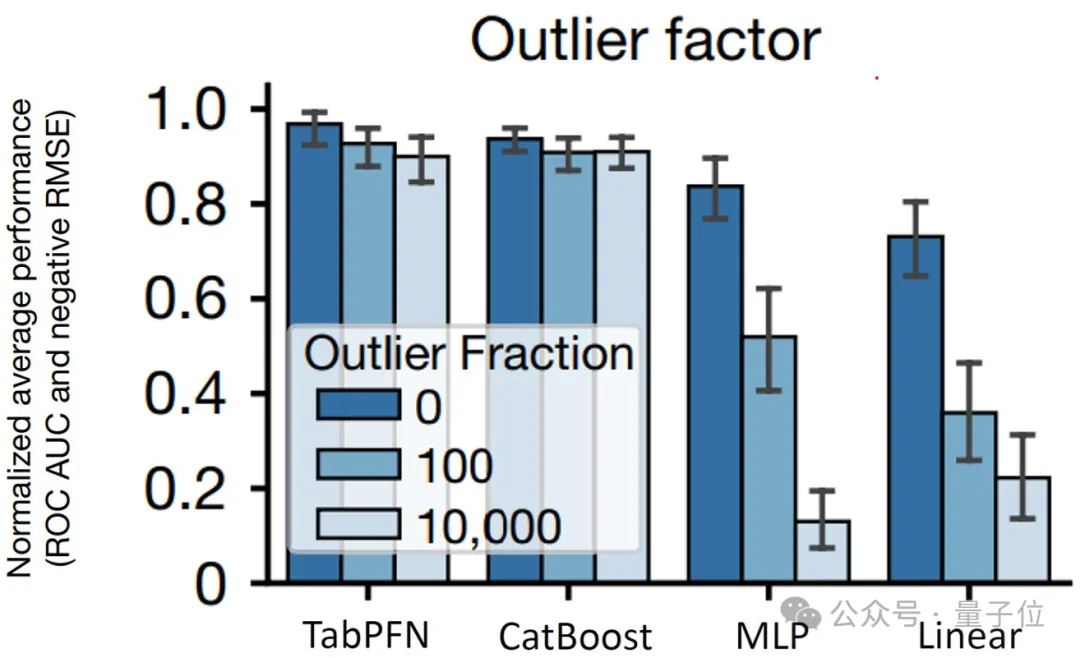
此外,它还原生支持缺失值和异常值等,使其在处理各种数据集时都能保持高效和准确。
 图片
图片
 图片
图片
整体而言,TabPFN v2适用于处理不超过10,000样本和500特征的中小规模数据集。
下面我们来看TabPFN模型完整的训练和应用过程。
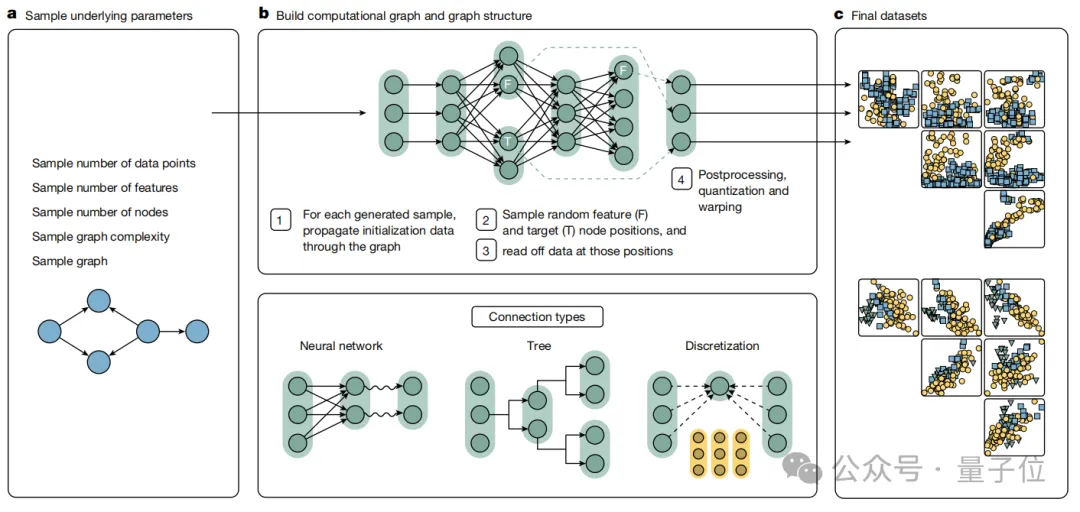
先说数据集采样。为了让模型能够应对各种实际情况,研究人员生成了大量合成数据。
第一步,他们对一些关键参数(如数据点、特征、节点等数量)进行采样,然后在中间部分构建计算图和图结构以处理数据,最终生成具有不同分布和特征的数据集。
需要强调的是,为避免基础模型常见问题,中间部分是基于结构因果模型(SCMs)来生成合成训练数据集。
简单说,通过采样超参数构建因果图,传播初始化数据并应用多种计算映射和后处理技术,可以创建大量具有不同结构和特征的合成数据集,从而使模型能学习处理实际数据问题的策略。
 图片
图片
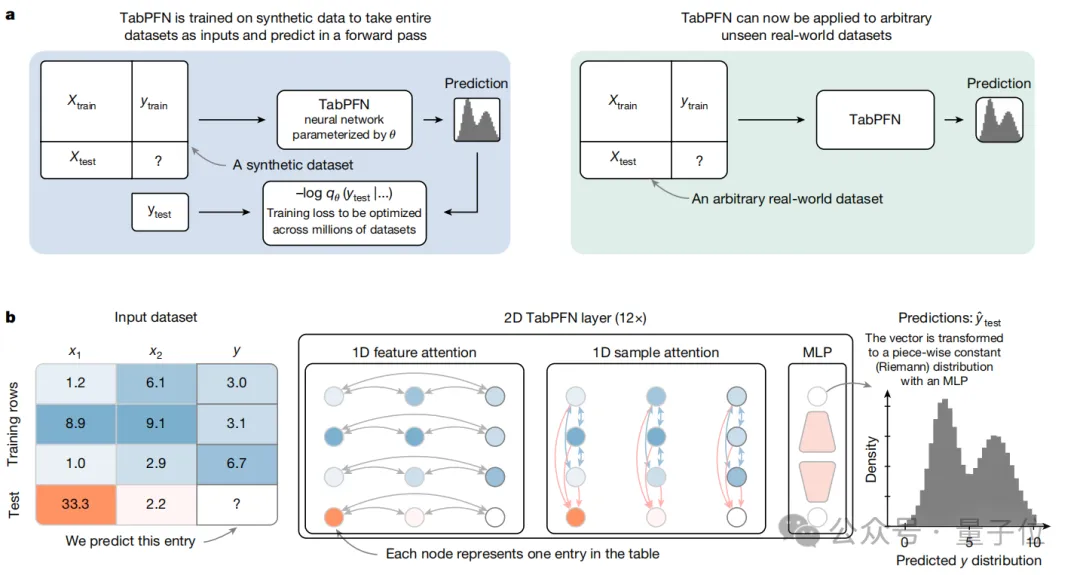
接下来进行模型预训练,他们为表格结构适配了新的架构。
比如TabPFN模型为每个单元格分配独立的表示,这意味着每个单元格的信息都能被单独处理和关注。
而且还采用双向注意力机制进一步增强了模型对表格数据的理解能力。
一方面,通过1D特征注意力机制,同一特征列的单元格之间可以相互关联和传递信息,使模型能够捕捉到不同样本在同一特征上的变化规律和关系。
另一方面,1D样本注意力机制让不同样本行的单元格进行信息交互,从而识别出不同样本之间的整体差异和相似性。
这种双向注意力机制保证了无论样本和特征的顺序如何改变,模型都能稳定地提取和利用其中的信息,从而提高了模型的稳定性和泛化能力。
 图片
图片
而且后续还进一步优化了模型训练和推理过程。
比如为了减少重复计算,当模型进行测试样本推理时,允许直接利用之前保存的训练状态,避免了对训练样本的重复计算。因为训练阶段的表格数据都是单独处理和学习的,已经有所保存。
同时,模型还通过采用半精度计算、激活检查点等方法,进一步减少了内存占用。
最后,在模型实际预测生成阶段。由于借助上下文学习(ICL)机制,模型无需针对每个新数据集进行大量的重新训练,从而可以直接应用于各种未曾见过的现实世界数据集了。
表格处理新SOTA
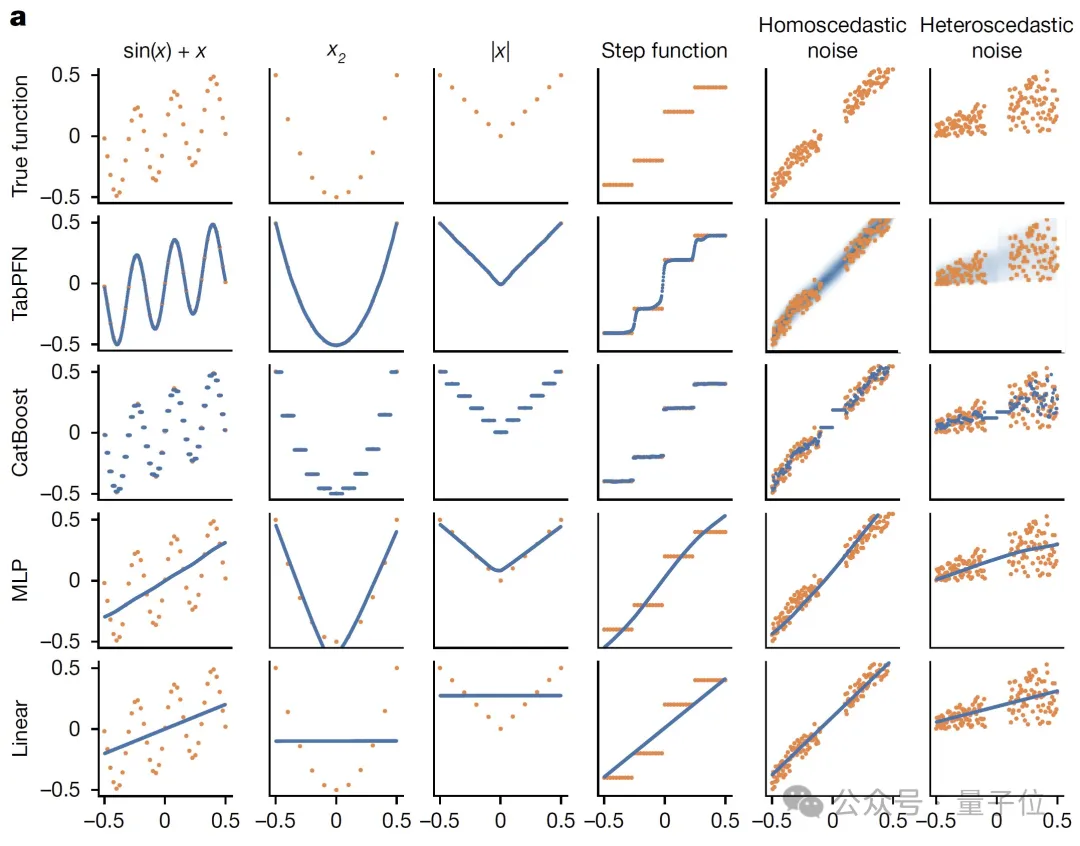
在定性实验中,与线性回归、多层感知器(MLP)、CatBoost等相比,它能够对多种不同的函数类型进行有效建模。(橙色表示训练数据,蓝色表示预测)
 图片
图片
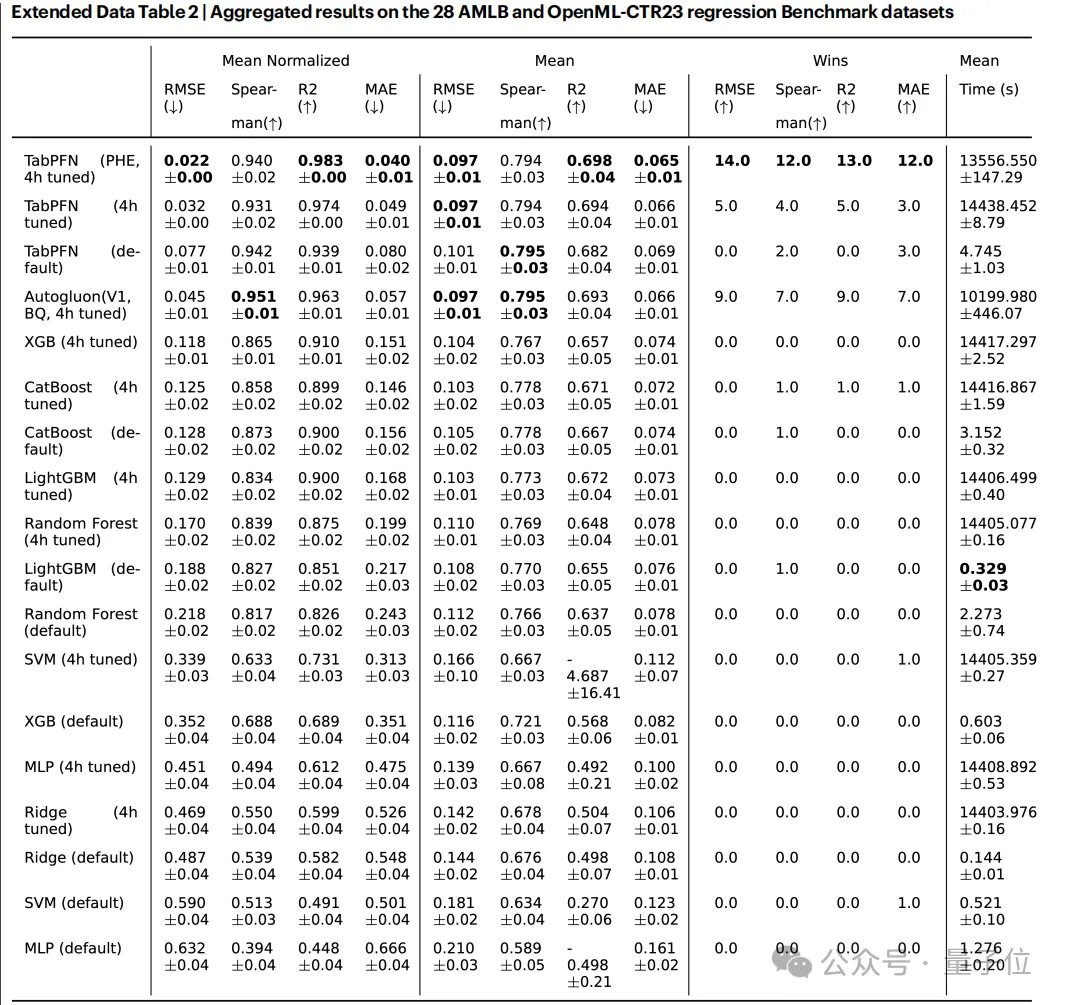
而在另一方面,在AutoML Benchmark和OpenML - CTR23等广泛使用且具有代表性的数据集上进行评估时,TabPFN比Random Forest、XGBoost等先进的基线方法取得了更多SOTA,涵盖了分类和回归两种主要任务的多个指标。
 图片
图片
甚至在实际的5场Kaggle竞赛中,在训练样本少于10,000的情况下,TabPFN也都战胜了CatBoost。
最最后,TabPFN还支持针对特定数据集进行微调。
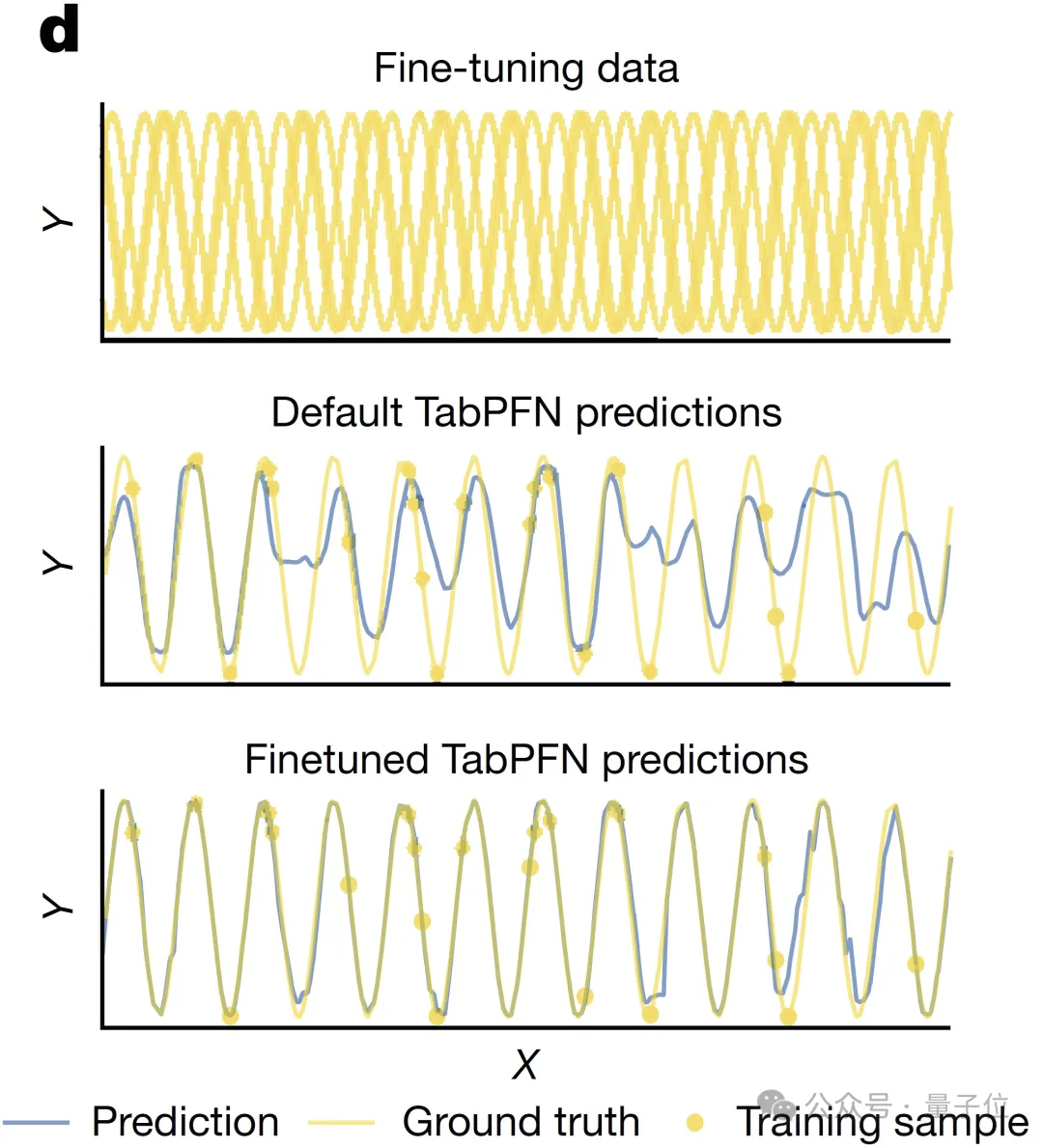 图片
图片
目前相关代码已开源,作者们还发布了一个API,允许使用他们的GPU进行计算。
感兴趣的同学可以蹲一波了~
API调用:https://priorlabs.ai/tabpfn-nature/代码:https://github.com/PriorLabs/TabPFN
参考链接:[1]https://www.nature.com/articles/s41586-024-08328-6[2]https://www.automl.org/tabpfn-a-transformer-that-solves-small-tabular-classification-problems-in-a-second/[3]https://x.com/FrankRHutter/status/1877088937849520336