DeepSeek啥都开源了,就是没有开源训练代码和数据。
现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。
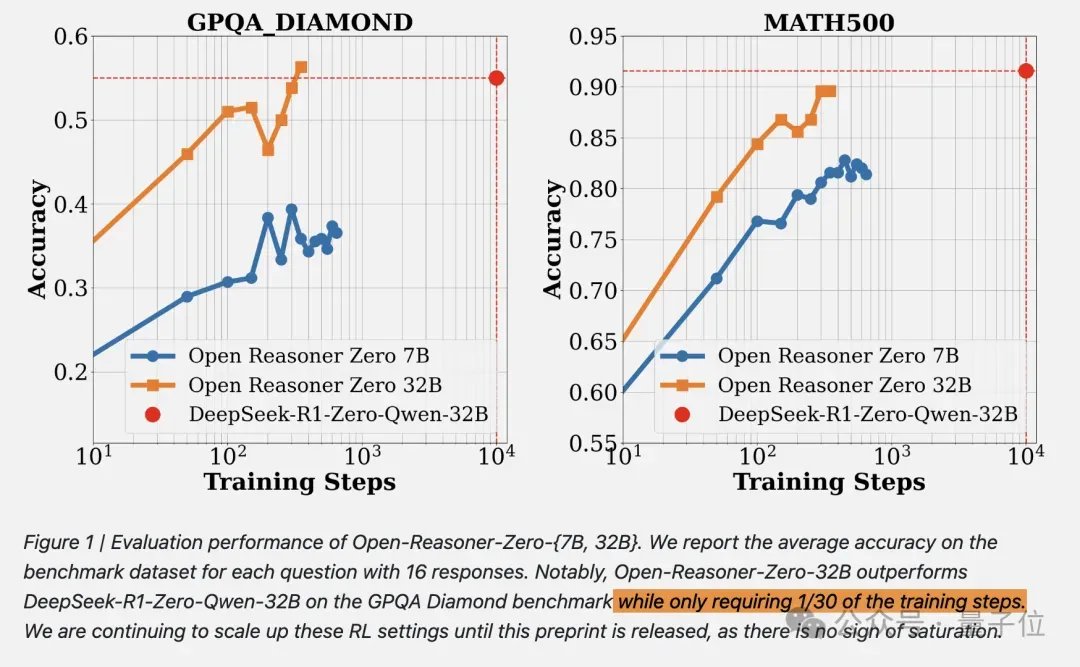
国内大模型六小强之一的阶跃星辰联与清华联合发布Open Reasoner Zero(ORZ),由AI大拿沈向洋、阶跃星辰创始人/CEO姜大昕、ResNet作者张祥雨等一众大佬亲自署名。

在响应长度上,用约17%的训练步骤就能赶上DeepSeek-R1-Zero 671B。
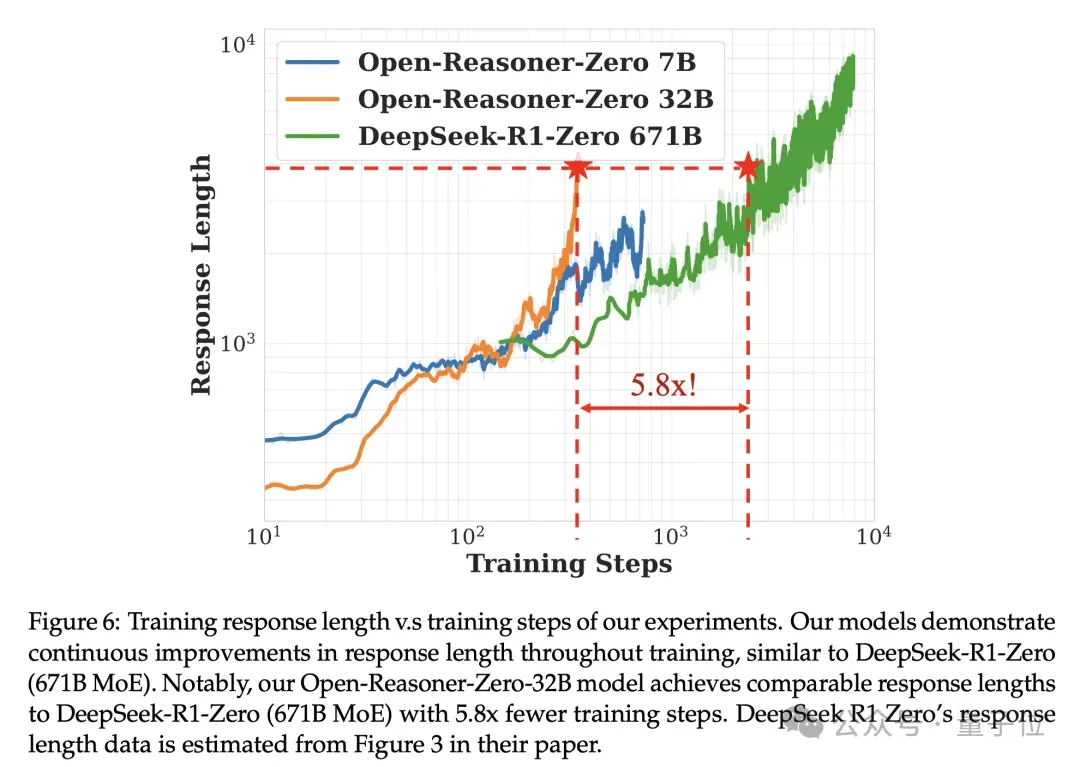
值得关注的是,团队还发现了一个重要的转折点——
在训练步骤约680步时,模型的训练奖励值、反思能力和回答长度同时出现显著提升,疑似出现了DeepSeek-R1-Zero论文中类似的“顿悟时刻”(aha moment)。
目前,研究训练数据、训练代码、论文、模型全都100%开源,开源许可证用的也是宽松的MIT Lisence。
开源48小时,就已速揽700+星星。
以下是更多细节。
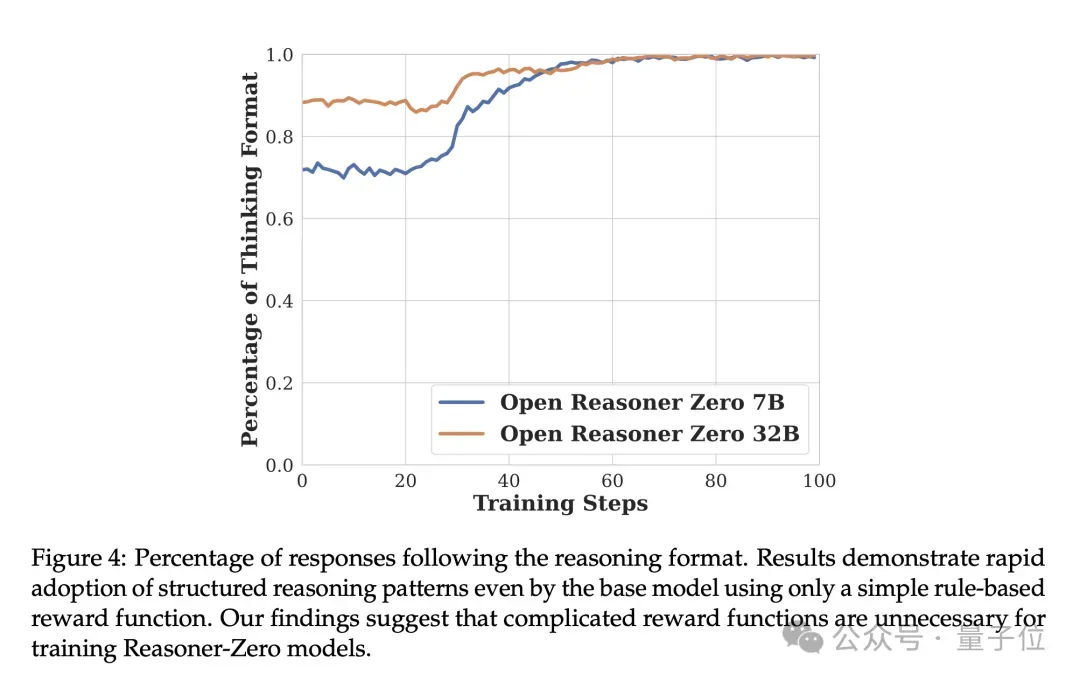
复杂的奖励函数不必要?!
通过广泛的实验,团队证明了一种极简主义的方法,带有GAE的原版PPO就可以有效地扩展RL训练(关键的参数设置是GAE λ= 1,折扣因子γ=1)。
再加上基于规则的奖励函数,足以在推理任务上同时扩大响应长度和基准性能,类似于DeepSeek-R1-Zero中观察到的现象。
这一结果表明复杂的奖励函数是不必要的。
另外,团队在不依赖任何基于KL的正则化技术的情况下实现了稳定的训练,这与RLHF和推理模型领域目前的认知不同,这也为进一步扩大强化学习规模提供了希望。
同时扩大数据数量和多样性对于Open Reasoner Zero的训练至关重要。虽然在像MATH这样有限的学术数据集上训练会导致性能快速达到平台期,但精心策划的大规模多样化数据集能够实现持续扩展,在训练集和测试集上都没有饱和的迹象。
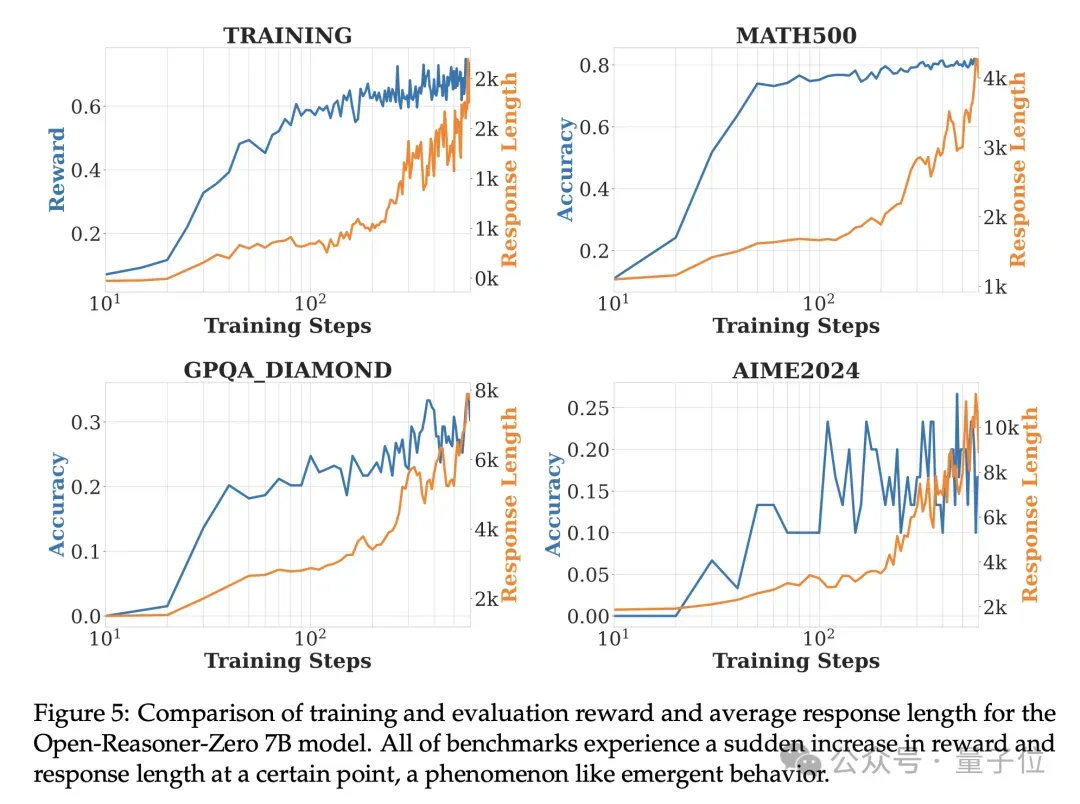
在以Qwen2.5-Base-7B为基础模型的实验中,所有基准测试在某个时间点都会经历奖励和响应长度的突然增加,这种现象类似于涌现行为。
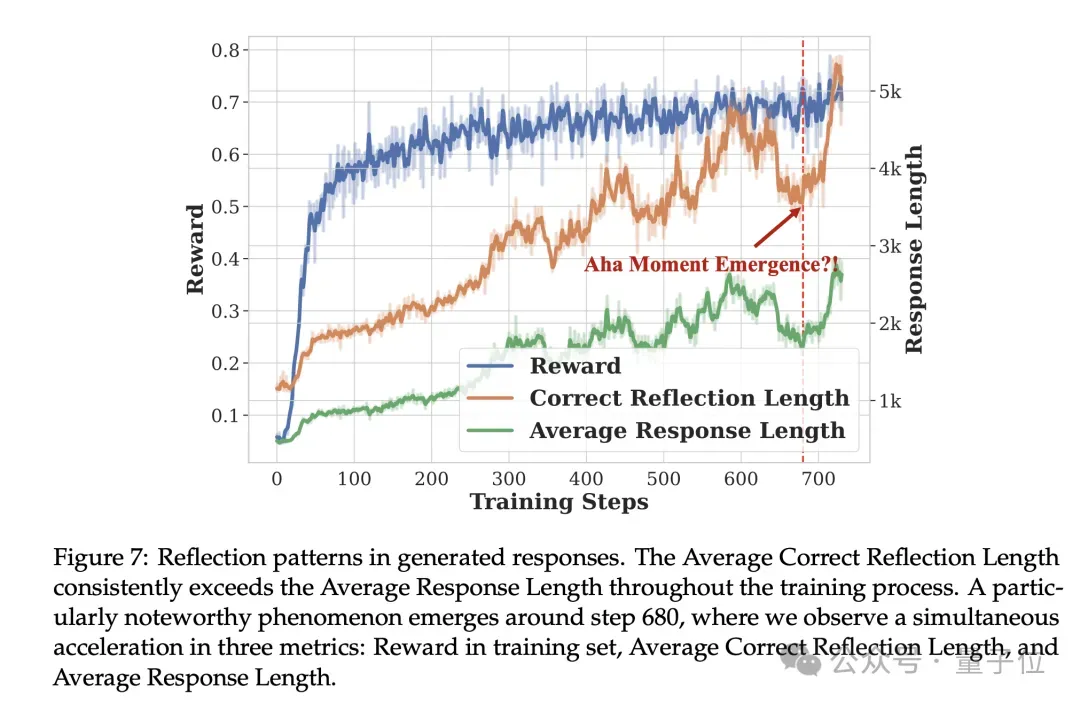
在整个训练过程中,Average Correct Reflection Length始终高于 Average Response Length。一个特别值得注意的现象出现在第 680步附近,可以观察到三个指标同时加速。
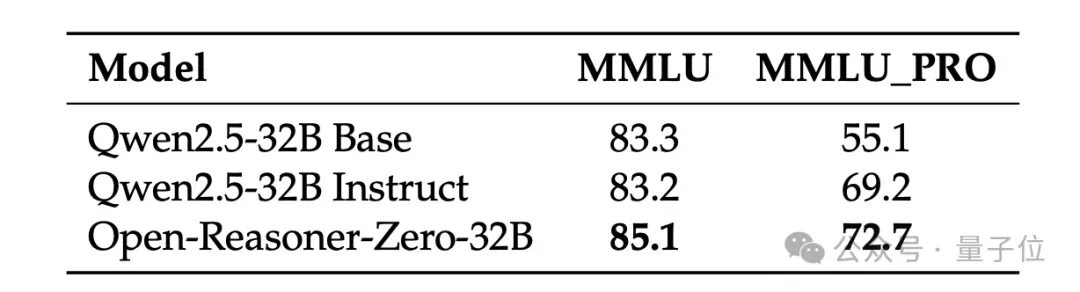
最终,Open-Reasoner-Zero模型在MMLU和MMLU_PRO基准测试中,无需任何额外的指令调整即可超越 Qwen2.5 Instruct。
One More Thing
昨天,在阶跃星辰生态开放日上,阶跃星辰创始人兼CEO姜大昕就有简单提及这项研究。
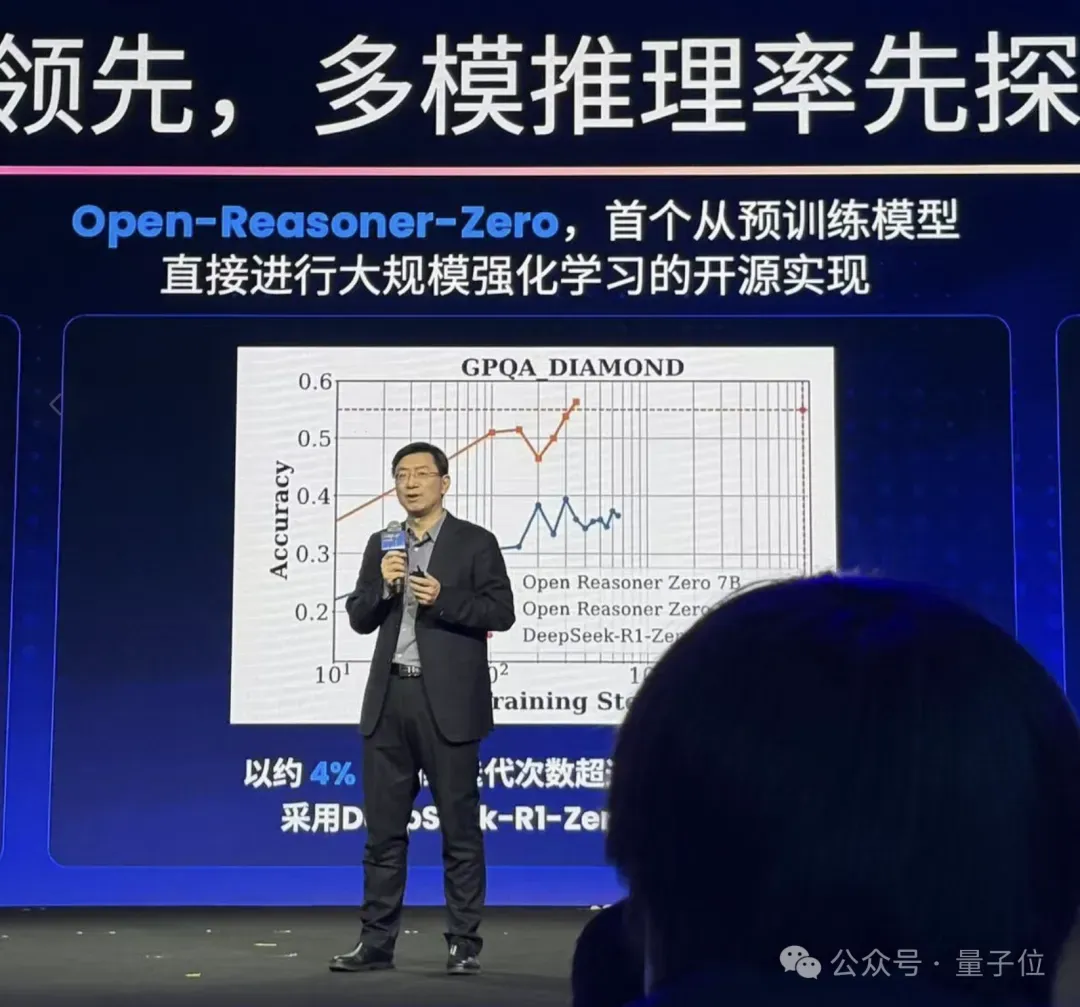
只提了一嘴,是因为研究还未完全完成(Working in Progress),随时可能有新进展,感兴趣的盆友可以关注一哈。
项目地址:
https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/


