近期,来自字节跳动的视频生成模型 Loopy,一经发布就在 X 上引起了广泛的讨论。Loopy 可以仅仅通过一张图片和一段音频生成逼真的肖像视频,对声音中呼吸,叹气,挑眉等细节都能生成的非常自然,让网友直呼哈利波特的魔法也不过如此。

Loopy 模型采用了 Diffusion 视频生成框架。输入一张图片和一段音频,就可以生成相应的视频。不但可以实现准确的音频和口型同步,还可以生成细微自然的表情动作,例如人物跟随情绪节奏做出抬眉、吸气、憋嘴停顿、叹气、肩膀运动等非语言类动作也能很好地被捕捉到;在唱歌时也能表现得活灵活现,驾驭不同风格。 柔和
柔和 高昂
高昂 
rap
更多丰富风格的展示,可移步项目主页:https://Loopyavatar.github.io/, https://arxiv.org/pdf/2409.02634
在不同的图片风格上,Loopy 也都表现得不错,像古风画像、粘土风格、油画风格、3D 素材以及侧脸的情况等等。




Loopy 技术方案
具体来说,Loopy 是如何仅需音频,就能实现这样生动的效果呢?
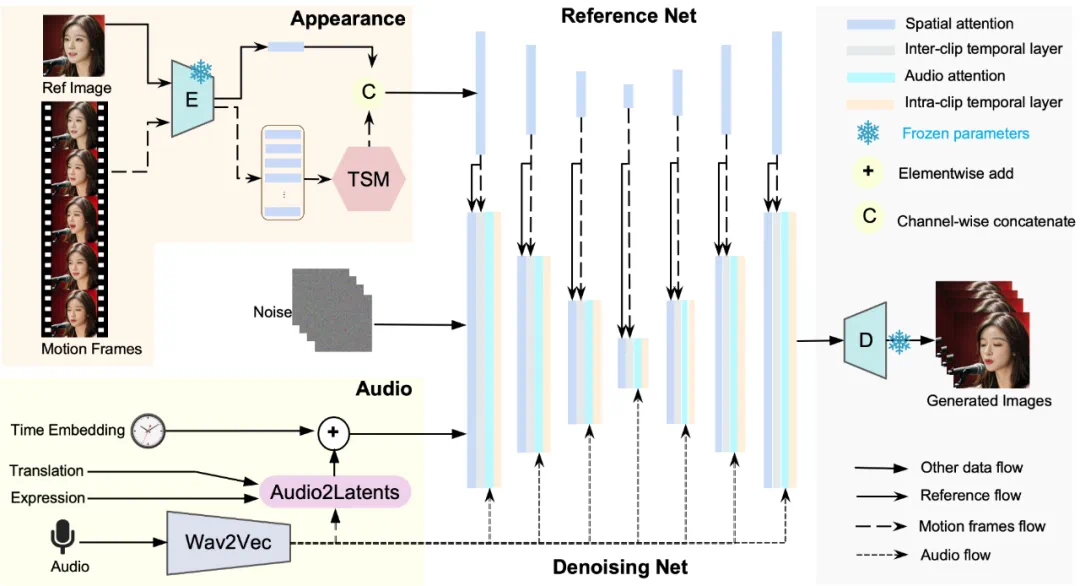
Loopy 框架中分别对外观信息(对应图中左上角)和音频信息(图中左下角)做了相应的方法设计,在外观上团队引入了 inter/intra- clip temporal layers 模块,通过 inter-clip temporal layer 来捕捉跨时间片段的时序信息,通过 intra-clip temporal layer 来捕捉单个片段内的时序信息,通过分而治之的方式更好建模人物的运动信息。
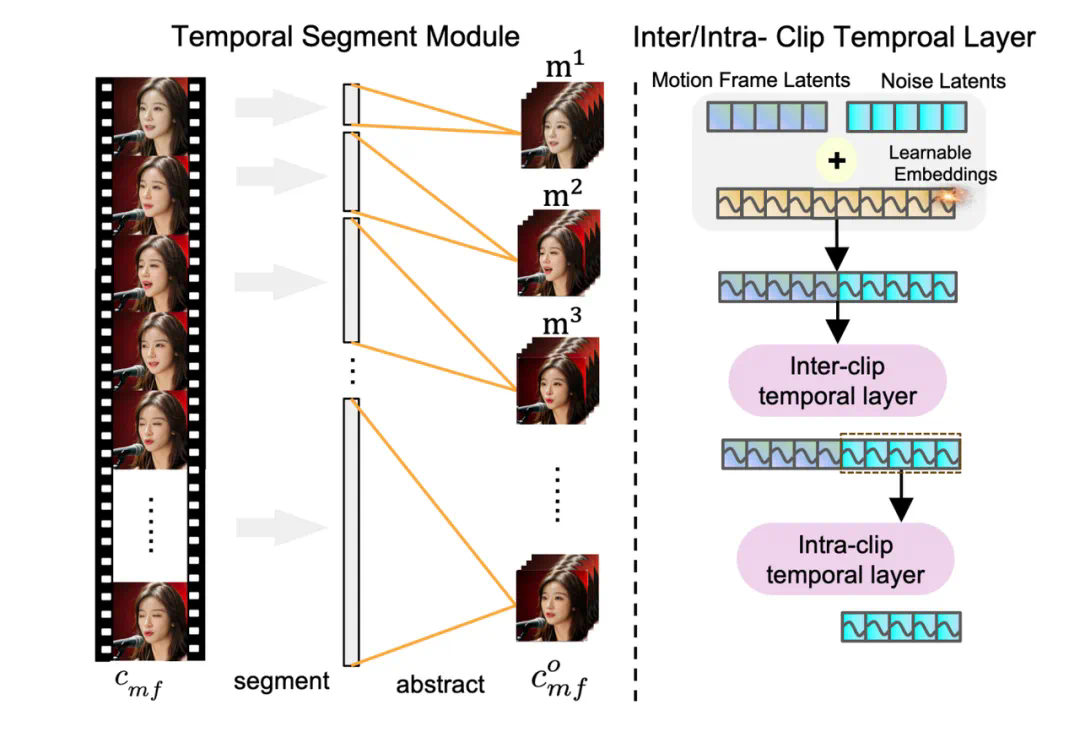
同时为了进一步的提升效果,团队设计了 Temporal Segment Module 使得 inter-clip temporal layer 可以捕捉长达 100 帧以上的时序信息,从而可以更好的基于数据学习长时运动信息依赖,抛弃了空间模版的限制,最终生成更好的人像运动。这就不难理解为什么 Loopy 可以仅仅依靠音频,不需要任何空间辅助信号就可以生成自然逼真的人像视频了。
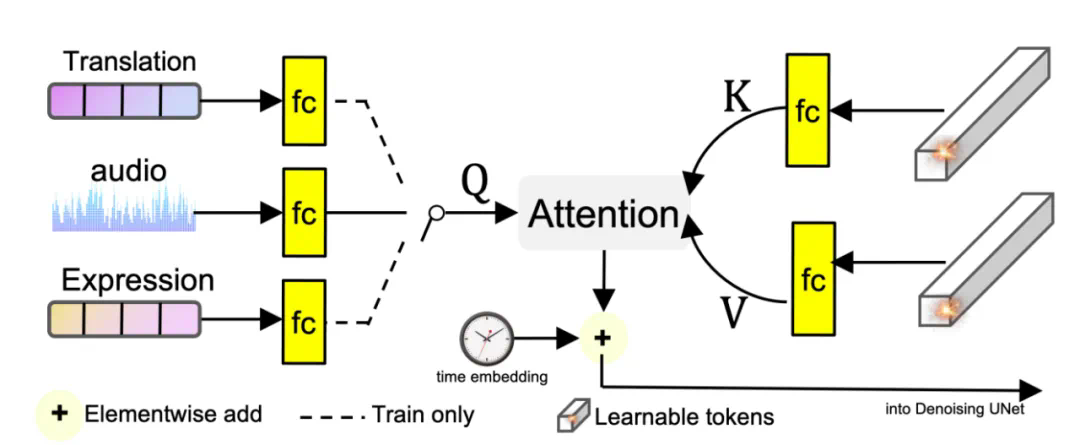
除此以外,为了能够捕捉到细腻的表情变化,团队设计了一个名为 audio to latents(A2L)的模块,用来增强音频和头部运动之间的关联关系。这个 A2L 模块在训练过程中会随机选取音频、表情参数、运动参数中的一个,将其转化为 motion latents,作为 diffusion model 的运动控制信号。在测试的时候,只需要音频就能够得到 motion latents。通过这种方式,可以借助与肖像运动强相关的条件(表情参数、运动参数)来帮助较弱相关的条件(audio)生成更好的 motion latents,进而实现对细微生动的肖像运动及表情的生成。
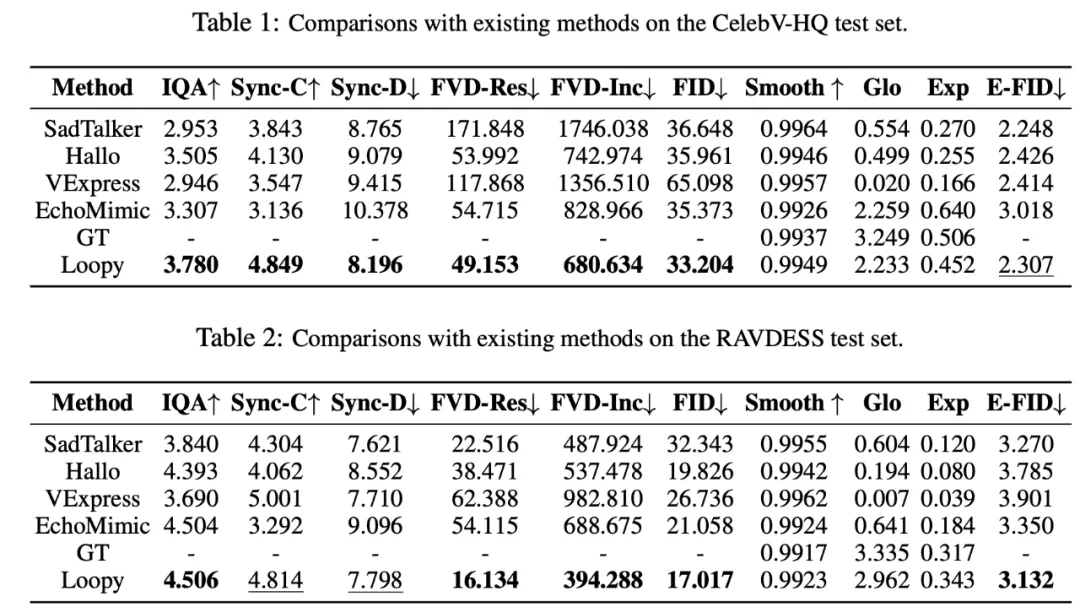
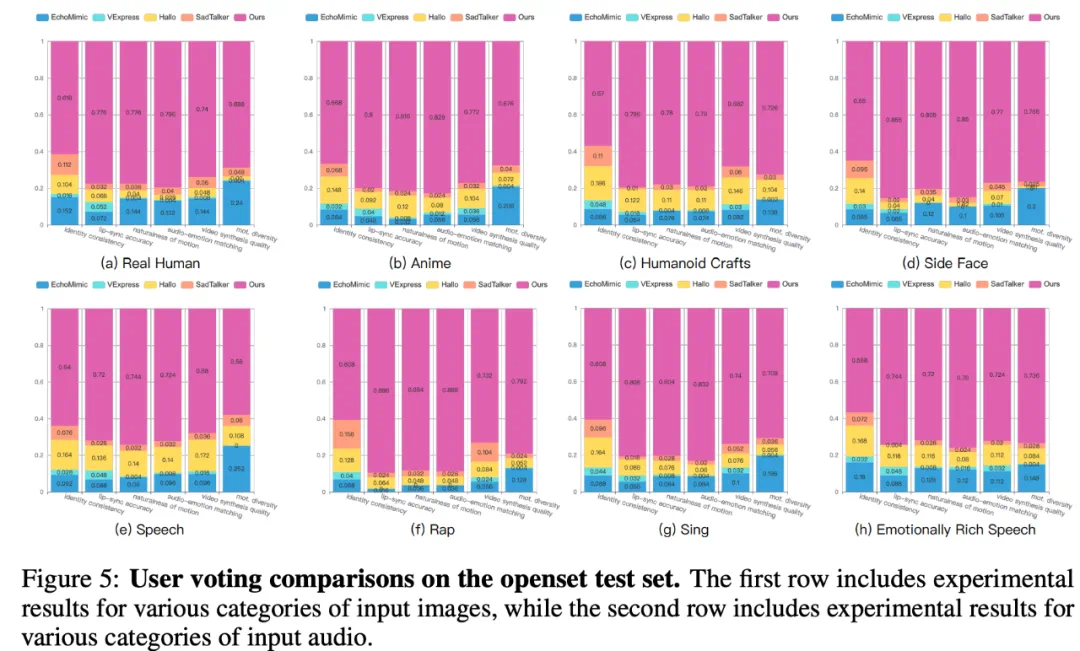
Loopy 在不同场景下都和近期的方法做了数值对比,也体现了相当的优势:
CyberHost 半身人像版模型,手部动作也能驱动
除此以外,该团队近期还推出了一个名为 CyberHost 的半身人像版本。这款模型是首个采用端到端算法框架进行纯音频驱动的半身视频生成系统,将驱动范围从肖像扩大到了半身,不仅表情自然、口型准确,也能生成和音频同步的手部动作,这在该领域是一个重大突破。
手部动作生成一直是视频生成技术中的难题,鲜有模型能实现稳定的效果。特别是在纯音频驱动的场景下,由于缺乏骨架信息输入,保持手部动作的稳定性更具挑战。CyberHost 通过专门设计的 Codebook Attention 来强化对人脸和手部等关键区域的结构先验学习,在纯音频驱动下的手部生成质量甚至超越了许多基于视频驱动的方法。




Codebook Attention 引入了一系列可学习的时空联合隐变量参数,专注于在训练过程中学习数据集中局部区域的结构特征和运动模式。同时,该机制还提取了关键区域的外观特征,强化了局部 ID 的一致性。团队将这一机制应用于脸部和手部区域,并在 Denoising U-Net 的各个阶段进行插入,提升了对关键区域的建模能力。
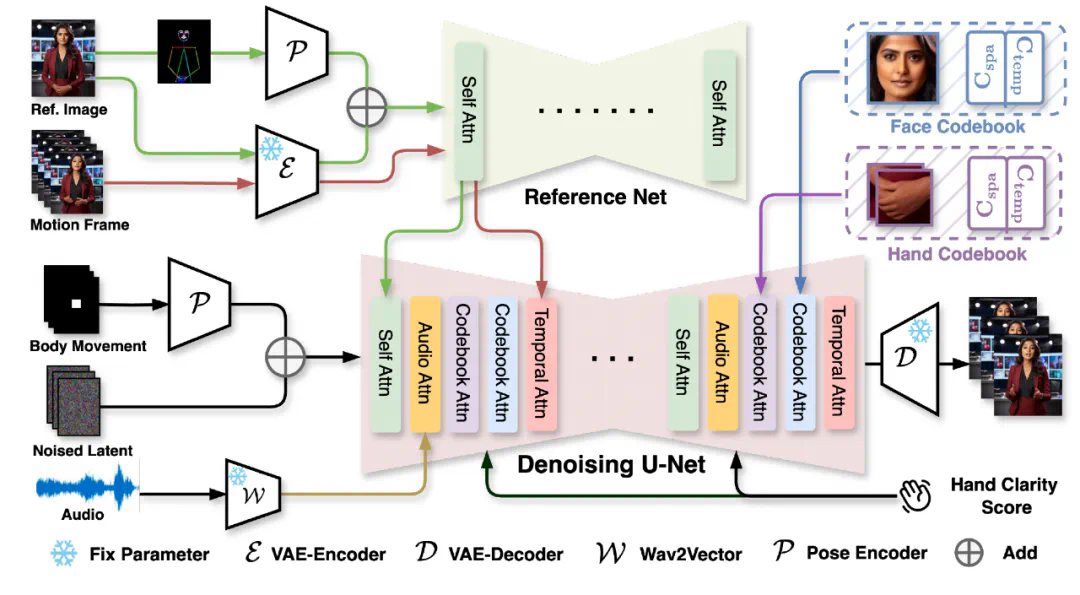
此外,CyberHost 还设计了一系列基于人体结构先验的训练策略,旨在减少音频驱动下人体动作生成的不确定性。这些策略包括 Body Movement Map 和 Hand Clarity Score。Body Movement Map 可以用于限制视频生成中人体的运动范围。而 Hand Clarity Score 通过计算局部像素的 laplacian 算子来控制生成手部的清晰度,规避手部运动模糊带来的效果劣化。
更多细节见论文以及项目主页:
CyberHost: https://cyberhost.github.io/, https://arxiv.org/pdf/2409.01876
团队介绍
字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。
目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中。