在语音识别领域,中文识别的技术发展一直备受关注。近日,小红书的 FireRed 团队发布了一个全新的开源语音识别模型 ——FireRedASR。这个基于大模型的语音识别系统在多个标准测试集上取得了优异的成绩,标志着中文语音识别技术的一次重大突破。
FireRedASR 的核心指标是字错误率(CER),该指标越低,表示模型的识别效果越好。在最近的公开测试中,FireRedASR 的 CER 达到了3.05%,较之前的最佳模型 Seed-ASR 降低了8.4%。这一结果显示出 FireRed 团队在语音识别技术上的创新能力。
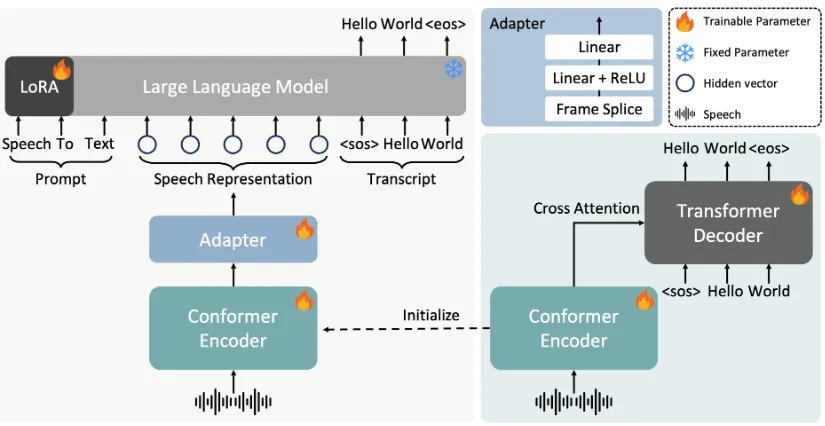
FireRedASR 模型分为两种核心结构:FireRedASR-LLM 和 FireRedASR-AED。前者专注于极致的语音识别精度,后者则在准确率与推理效率之间实现了良好的平衡。团队提供了不同规模的模型和推理代码,以满足各种应用场景的需求。
在多个日常应用场景中,FireRedASR 同样展现了强大的性能。在由短视频、直播和语音输入等多种来源组成的测试集中,FireRedASR-LLM 的 CER 相较于业内领先的服务提供商降低了23.7% 至40%。特别是在需要歌词识别的场景中,该模型的表现尤为突出,CER 实现了50.2% 至66.7% 的相对降低。
此外,FireRedASR 还在中文方言和英语场景中表现优异,其 CER 在 KeSpeech 和 LibriSpeech 测试集上显著优于之前的开源模型,证明其在多种语言环境中的鲁棒性和适应性。
FireRed 团队希望通过开源这一新模型,推动语音识别技术的发展和应用,为语音交互的未来贡献力量。所有模型和代码已在 GitHub 上公开,鼓励更多开发者和研究者参与其中。
huggingface:https://huggingface.co/FireRedTeam
github:https://github.com/FireRedTeam/FireRedASR
划重点:
- 🎤 FireRedASR 是小红书团队新发布的开源语音识别模型,中文识别准确率表现优异。
- 🚀 模型分为 FireRedASR-LLM 和 FireRedASR-AED,分别针对精度和效率需求。
- 🌍 FireRedASR 在多种场景下表现优异,适用于普通话、中文方言及英语等多种语言环境。