微软又有“1 bit LLM”新成果了——
发布BitNet v2框架,为1 bit LLM实现了原生4 bit激活值量化,由此可充分利用新一代GPU(如GB200)对4 bit计算的原生支持能力。
同时减少内存带宽&提升计算效率。
之前,微软持续研究BitNet b1.58,把LLM的权重量化到1.58-bit,显著降低延迟、内存占用等推理成本。
然鹅BitNet b1.58激活值还是8-bit,这就导致没办法充分利用新一代硬件的4 bit计算能力,计算环节出现效率瓶颈。
还有个问题也很关键:
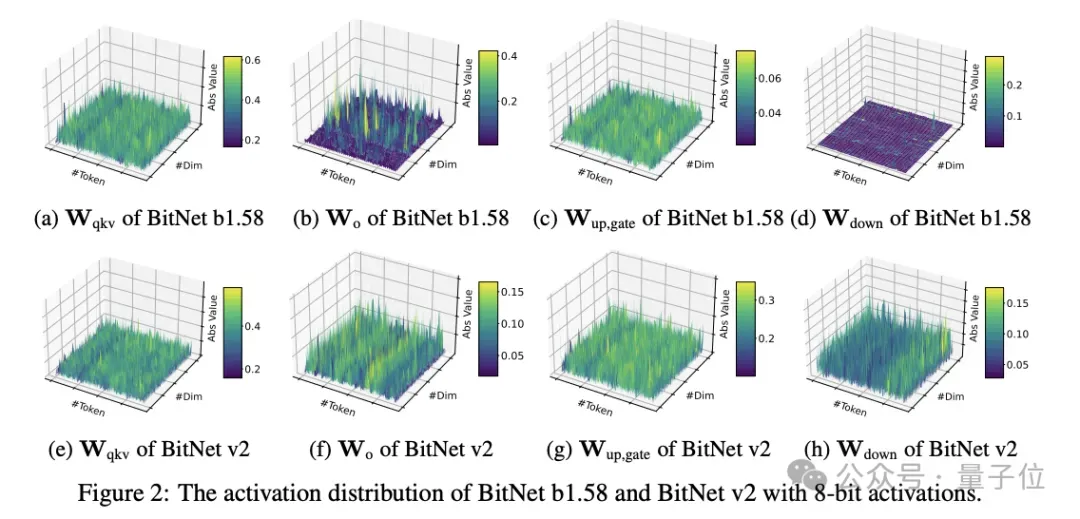
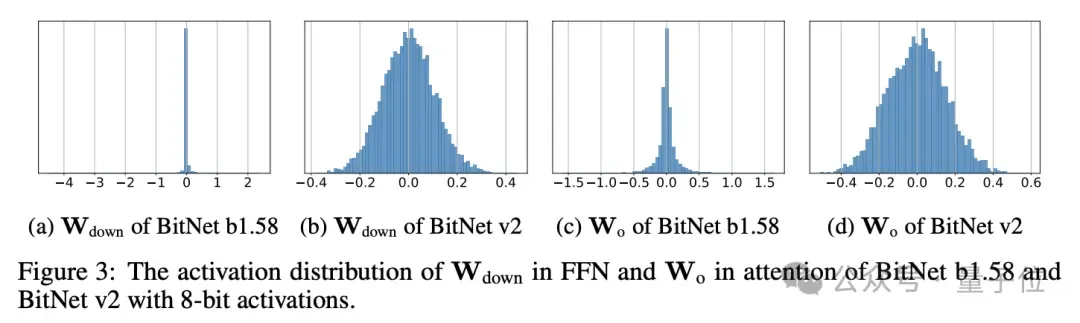
研究发现注意力层和前馈网络层的输入激活值分布还比较接近高斯分布,量化起来相对容易。
但中间状态的激活值有很多异常值,这就给低bit量化带来了很大阻碍。
此前的BitNet a4.8相关研究,尝试过用4 bit量化输入,8 bit稀疏化处理中间状态。
这种方法虽然性能损失不大,可稀疏化在批量推理场景里不太适合用来提高吞吐量,因为硬件更适合密集计算。

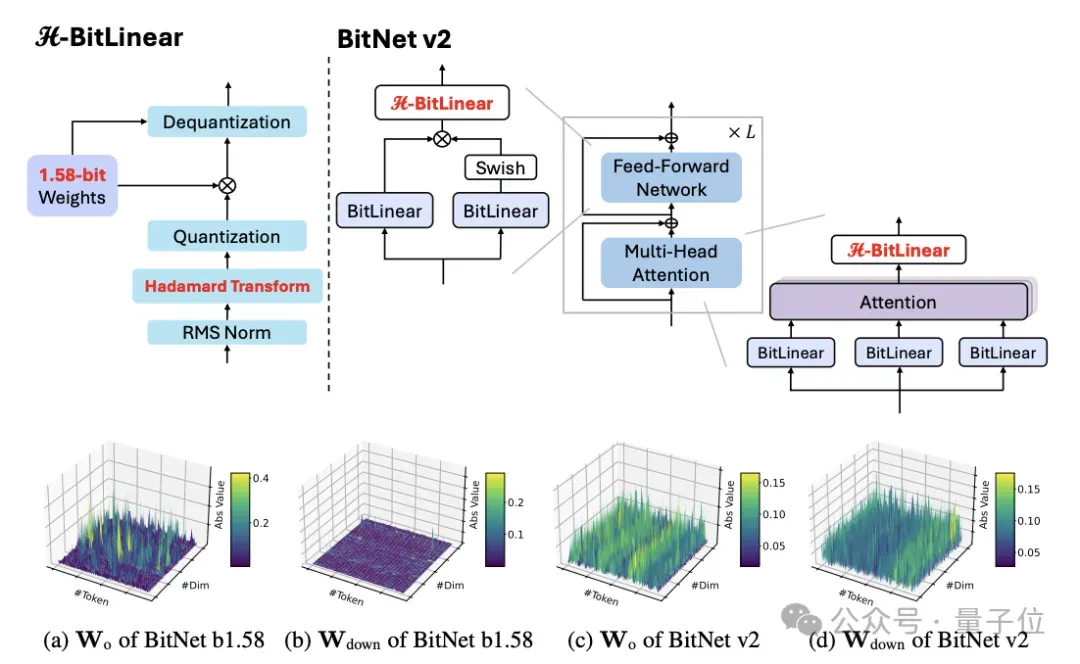
这次,团队最新推出了BitNet v2,通过引入H-BitLinear模块,该模块在激活量化前应用Hadamard变换。
研究中能有效将注意力层和前馈网络中尖锐的激活分布重塑为更接近高斯分布的形式,显著减少异常通道,使4 bit激活量化成为可能。

下面来看看究竟是怎么做的。
引入H-BitLinear模块
对于权重量化,根据团队此前研究,使用per-tensor absmean函数将权重量化为三元值{-1, 0, 1}:
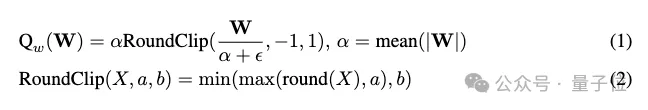
对于低bit激活,团队引入了H-BitLinear。
H-BitLinear被用于注意力层的权重矩阵Wo和前馈网络(FFN)层的Wdown中,这两处正是激活值异常值最为集中的位置。
该模块在激活值量化前应用Hadamard变换,满足以下条件:
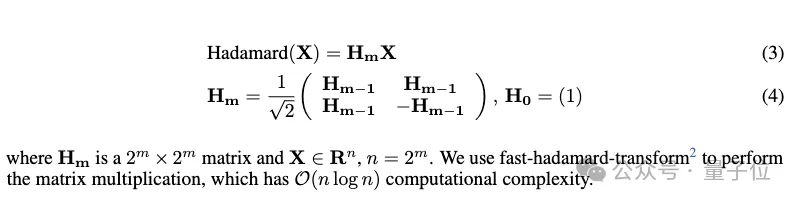
通过Hadamard变换,中间状态分布更接近高斯分布,显著减少了异常值数量,使其更适合INT4量化。
对于8 bit和4 bit激活,分别采用per-token absmax和absmean函数,激活量化可以表示为:
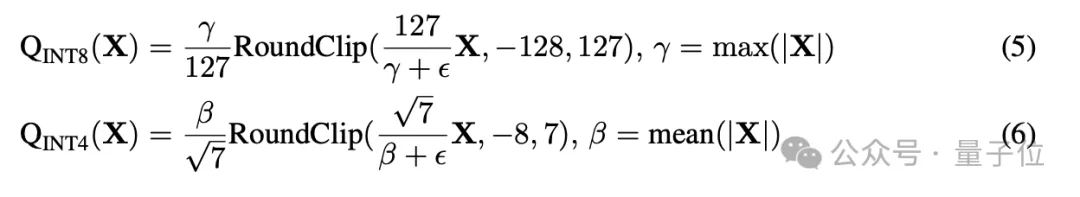
最终,H-BitLinear的矩阵乘法运算可形式化表示为:
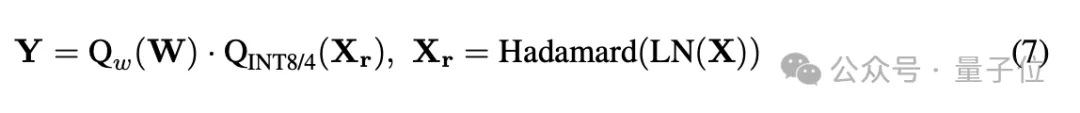
其中LN表示层归一化(layer normalization)操作。
另外,训练策略方面,研究人员用了STE来近似梯度,还采用混合精度训练更新参数。在反向传播的时候,会绕过量化里那些不可微函数,并且利用Hadamard变换矩阵的正交性,对梯度也进行变换。
团队还表示,4 bit激活的BitNet v2可以从8 bit激活的版本接着训练,用少量数据微调就行,性能损失基本可以忽略不计,优化器的状态还能接着用。
4bit激活版本相比8bit激活性能几乎不降
实验阶段,研究者将BitNet v2与BitNet b1.58、BitNet a4.8在不同模型规模(400M、1.3B、3B和7B)上进行了对比,所有模型都使用1.58bit权重训练。
主要实验结果显示,引入Hadamard变换的BitNet v2(8 bit激活)相比BitNet b1.58在各规模模型上都有所提升,在7B规模上,平均准确率提高了0.61%。
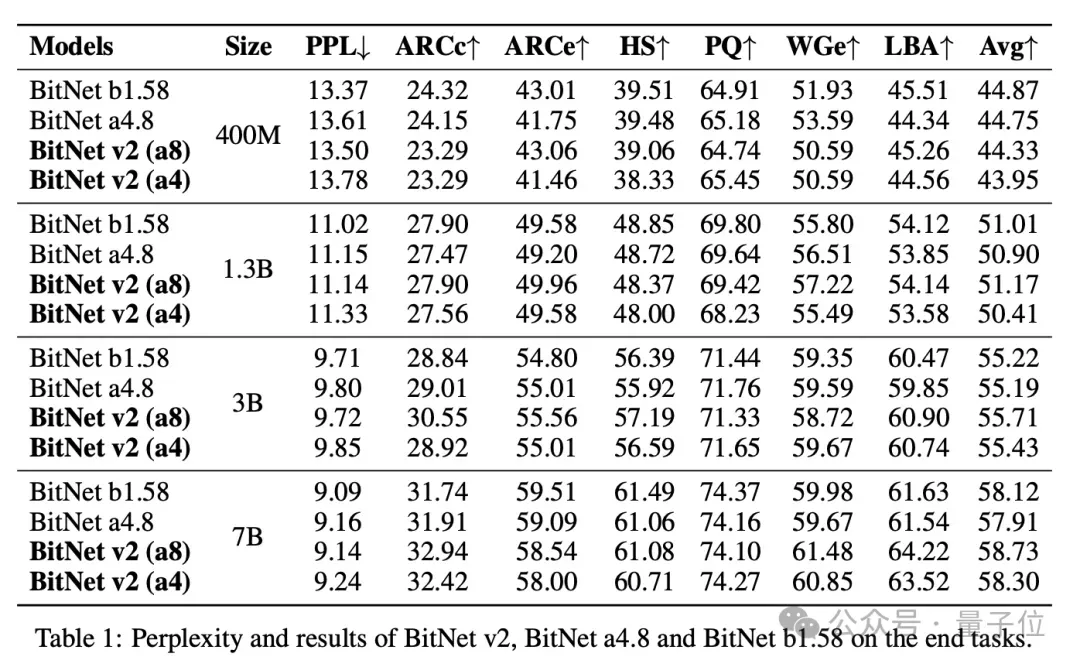
当降至4 bit激活时,BitNet v2的困惑度与BitNet a4.8相当,下游任务表现甚至更优。
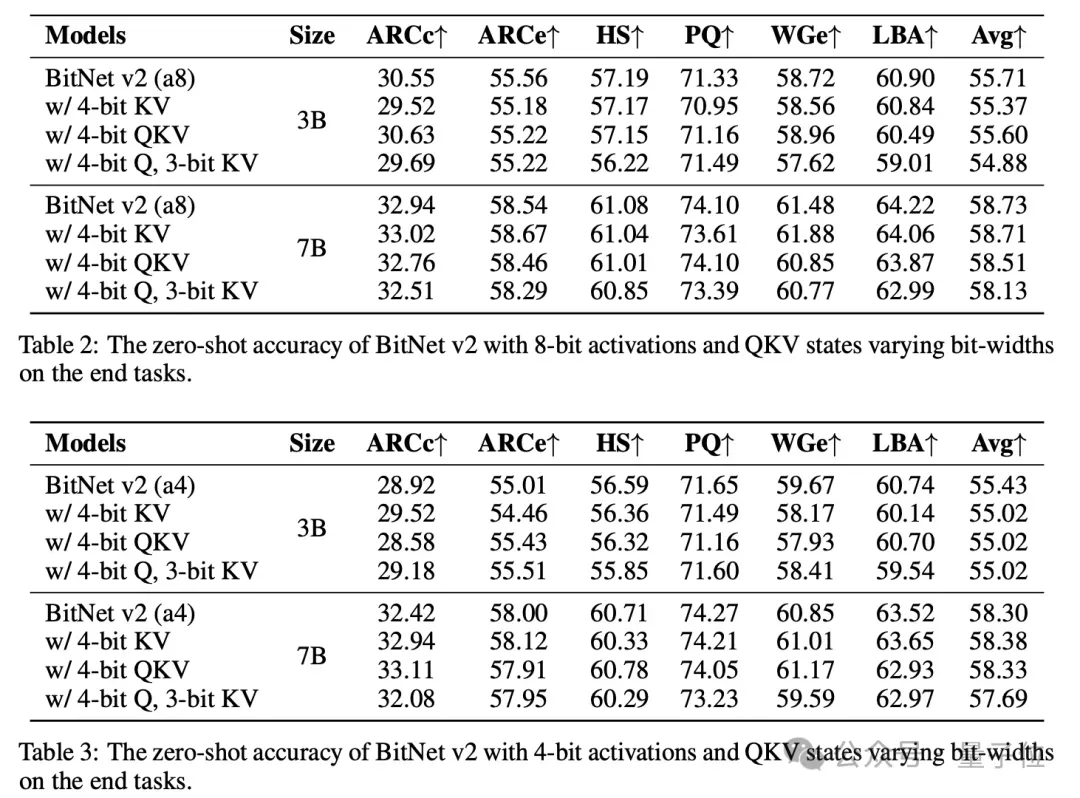
研究者还对BitNet v2进行了低bit注意力状态的详细实验,采用后RoPE量化处理QKV状态。采用3 bit KV缓存的BitNet v2在3B、7B模型上达到了与全精度KV缓存版本相当的准确率:
与后训练量化方法SpinQuant、QuaRot相比较,BitNet v2表现更优:

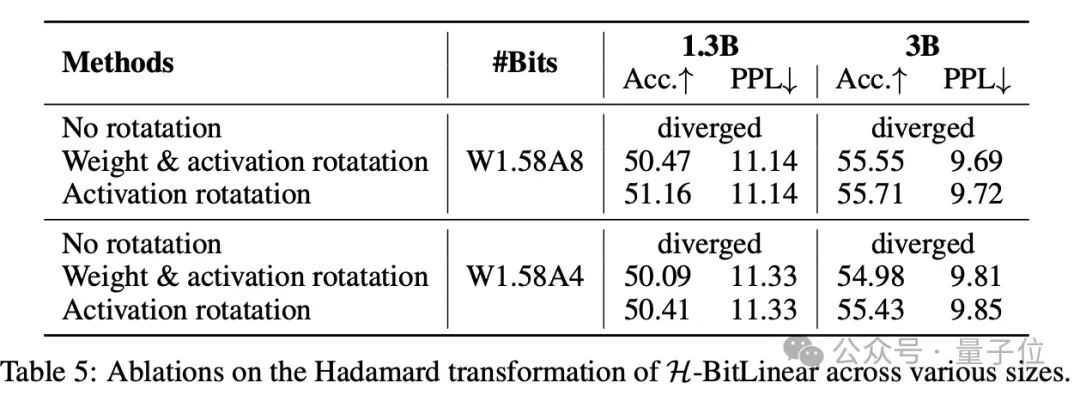
消融实验则进一步验证了Hadamard变换对低bit激活的关键作用,没有旋转变换则模型会发散。
更多研究细节,感兴趣的童鞋可以查看原论文。
论文链接:https://arxiv.org/pdf/2504.18415


