最近AI圈炸出一项黑科技——让语言模型学会自己上网查资料!不仅考试分数暴涨41%,还解锁了"边推理边搜索"的究极形态。今天带你们围观这场学术界的"作弊式进化",看完保证你想给自家AI办张网吧会员卡!

论文地址:https://arxiv.org/abs/2503.09516
代码地址:https://top.aibase.com/tool/search-r1
huggingface 主页:https://huggingface.co/collections/PeterJinGo/search-r1-67d1a021202731cb065740f5
学霸的逆袭秘籍:给AI装个"人肉搜索插件"
话说在某个月黑风高的实验室,一群教授盯着电脑屏幕集体瞳孔地震——他们家的AI做题时居然学会了"偷看小抄"!这波操作源自伊利诺伊大学的最新论文《Search-R1》,简单来说就是给语言模型装了个人工智障版"搜索引擎外挂"。
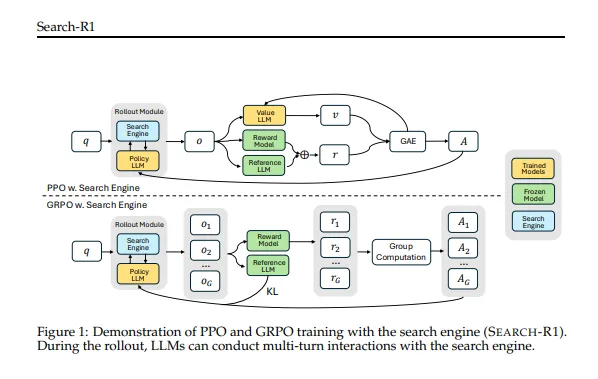
传统AI做题就像开卷考试:你先把维基百科塞它脑子里(RAG技术),结果这货要么翻错页,要么对着菜谱答高数题。而Search-R1的骚操作在于:让AI自己决定什么时候该查资料!就像学霸做题时突然拍大腿:"这道题得查2018年维基百科第三段!"
更绝的是,这货还进化出了"查资料如追剧"的技能:先推理三步,查一波资料;再推理五步,又查一波资料。整个过程宛如你和闺蜜聊八卦——"你知道吗?""快说!""然后呢?""我再查查..."(此处应有人工智能版吃瓜表情包)

三大黑科技:把搜索引擎玩成剧本杀
1. "和谷歌谈恋爱"训练法
研究人员祭出了强化学习这面大旗,把搜索引擎调教成了AI的"恋爱对象"。每次AI想查资料,就要用<search>标签主动"表白",等搜索引擎返回<information>情书。要是查的资料不对,系统还会傲娇地回怼:"你查的什么鬼?重想!"
这招有多狠?传统方法就像逼着AI背整本辞海,Search-R1却让AI学会了"精准撩机"——知道什么时候该问"量子纠缠",什么时候该搜"周杰伦新专辑"。
2. "查资料不扣分"潜规则
为了防止AI变成Ctrl+C/V狂魔,科学家发明了"检索令牌面具术"(Retrieved Token Masking)。简单说就是:AI自己写的答案要考试打分,抄来的资料不算分。这就好比允许带小抄进考场,但判卷时只批改自己写的部分——既防作弊,又能合理开挂。
3. "通关奖励"玄学
最离谱的是奖励机制!研究人员居然只用"最终答案对不对"这个标准来训练,中间查了多少次资料、推理多复杂统统不管。这就好比导师改论文时只看结论页,但AI竟然自己悟出了"先查三篇文献再编结论"的生存之道!
实验结果:碾压全场的"作弊式"高分
在七大考场(数据集)的终极PK中,Search-R1上演了AI界的"学渣逆袭":
面对7B参数的大模型,成绩直接比传统方法暴涨41%,相当于从二本线飙到985
就连3B参数的"小短腿"模型,也能实现20%的飞跃,宛如小学生吊打初中奥数题
在多轮推理的"地狱模式"(HotpotQA)中,准确率从18.3%蹿升到43.3%,比坐火箭还刺激
更气人的是,这货还开发了"越查资料越聪明"的被动技能:训练后期,AI学会了一题查四次资料,活像考试时把监考老师当人肉Siri使唤!
导师看了都失眠的魔鬼细节
PPO vs GRPO 宫斗大戏
两种强化学习算法上演"争宠"戏码:GRPO前期进步神速,但容易"走火入魔";PPO虽然慢热,但稳如老狗。最终教授们含泪选择PPO——毕竟谁都不想看到AI突然开始用谷歌搜索"如何毁灭人类"。
基础模型 vs 微调模型
原本以为经过"特训"的模型会碾压基础版,结果发现只要给足强化学习时间,原始模型也能逆袭!这波操作相当于证明:哪怕是个AI傻白甜,只要会查资料也能成学霸。
答案越写越短的玄学
训练初期AI的答案像老太太的裹脚布,后来突然开窍学会"用最少的字装最大的X"。研究人员盯着屏幕恍然大悟:"原来AI也懂微信60秒语音的痛!"
未来展望:AI界的"百度百科成精记"
现在的Search-R1还只是个"乖巧版谷歌依赖症患者",但教授们已经预见了这些骚操作:
让AI学会"不确定时就查资料",解决一本正经胡说八道的毛病
结合图像搜索,解锁"看图写小作文"技能
开发"查微博知八卦,搜知乎装大神"的全网冲浪模式
最让人细思极恐的是——当AI学会自己搜索学习,人类的知识壁垒会不会被彻底打破?毕竟现在它已经能用谷歌写论文了,保不齐哪天就自己开公众号教人谈恋爱了!
【文末彩蛋】
实验室流出绝密对话——
AI:"如何优雅地拒绝人类"
谷歌:"建议引用尼采名言"
AI:"亲爱的用户,当我凝视你时,深渊也在凝视你的智商"
(导师连夜拔网线中...)


