OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。
近日,华为诺亚方舟实验室的研究人员提出了一个名为思维森林 “Forest-of-Thought”(FoT)的全新大模型高阶推理框架,它通过在推理时扩展计算规模,显著提升了 LLM 的高阶推理能力。

- 论文链接:https://arxiv.org/abs/2412.09078
- 项目链接:https://github.com/iamhankai/Forest-of-Thought
LLM 的推理困境
尽管 LLM 在多种语言任务上表现出色,但在解决复杂推理问题时,它们常常陷入困境。以数学问题为例,LLM 可能会在分解问题的过程中忽略关键细节或在中间步骤中出错,导致最终答案错误;通常完成一条推理路径后,大模型通常不会重新审视其他可能的方法,这种缺乏重新评估的能力使得解决方案无法全面应对复杂的问题。相比之下,人类在处理复杂问题时,会从不同角度反复思考和验证,以确保答案的准确性。
思维森林 FoT 方法介绍
图 1 中的 FoT 框架通过整合多个推理树,利用集体决策的优势来解决复杂的逻辑推理任务。它采用稀疏激活策略,选择最相关的推理路径,从而提高模型的效率和准确性。此外,FoT 还引入了动态自校正策略,使模型能够在推理过程中实时识别和纠正错误,并从过去的错误中学习。共识引导决策策略也被纳入其中,以优化正确性和计算资源的使用。
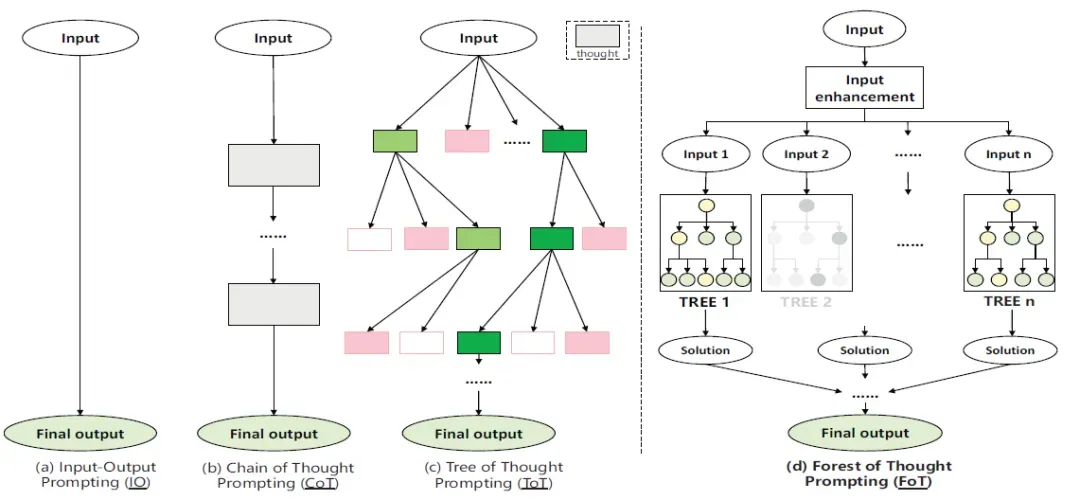
图 1 思维森林 FoT
稀疏激活策略
在 FoT 的推理过程中,并不是所有的推理树或树中的每个节点都会被计算,而是只选择最相关的推理树或节点进行计算。这种方法不仅提高了效率,还通过选择最相关的推理路径来提高模型的准确性。通过稀疏激活,FoT 能够过滤掉每个推理树的激活,确保只有某些推理树的路径被 “激活” 用于推理。
动态自校正策略
为了提高每个推理树给出正确答案的概率,FoT 引入了动态自校正策略。对于推理树的初始结果,自校正策略会评估其正确性和有效性,并在每个推理步骤完成后分配相应的分数。一旦某个步骤的分数低于预设阈值,策略会自动触发校正机制。该机制首先回顾和分析过去的失败案例,识别低分和常见错误模式的原因,然后尝试纠正错误并优化推理方向。通过这种从历史中学习和实时校正的机制,模型不仅避免了在相同问题上重复犯错,还能更迅速、更准确地找到解决新问题的有效方法。

图 2 动态自校正策略
共识引导决策策略
为了解决复杂的数学问题,FoT 设计了共识引导专家决策(CGED)策略,以确保最终答案的高准确性和可靠性。CGED 方法结合了集体智慧和专家判断,引导推理过程从基于共识的决策转向专家评估。在 FoT 方法中,每个独立树通过其独特的推理路径生成一个或多个可能的答案。子树会对候选答案进行投票,选出获得最多支持的答案。如果无法达成共识,数学专家将评估推理过程并选择最终答案,以确保其准确性和有效性。
实验结果
研究人员在多个 LLM 推理基准测试中评估了 FoT 方法,包括 24 点游戏、GSM8K 和 MATH 数据集,使用了多个开源 LLM 模型,包括 Llama3-8B,Mistral-7B 和 GLM-4-9B。
24 点游戏
24 点游戏的目标是使用给定的四个数字各一次,通过加、减、乘、除和括号构造一个算术表达式,使其结果为 24。表 1 中的实验结果表明,当推理树的数量从 2 增加到 4 时,FoT 的准确率提高了 14%,显示出显著的推理性能提升。相比之下,仅增加单个树的叶子节点数量的 ToT 方法遇到了性能瓶颈,进一步增加叶子节点数量并未带来显著的性能提升。这表明 FoT 通过多棵树提供的推理路径多样性比单纯增加单个树的复杂性更有效,凸显了 FoT 框架在实现可扩展和高效推理改进方面的优势。
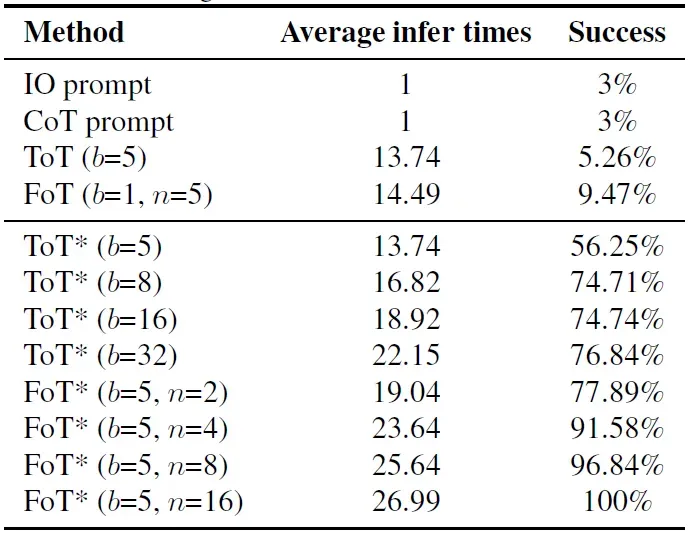
表 1 24 点游戏,Llama3-8B 基模型,b 是叶子节点数量,n 是树数量
GSM8K 基准测试
研究人员在 GSM8K 数据集上评估了 FoT 在不同基模型上的性能。图 3 中的实验结果表明,基于不同的大语言模型 Llama3-8B,Mistral-7B 和 GLM-4-9B,都存在类似的 scaling law:FoT 中的树数量越多,带来的准确率提升越显著。
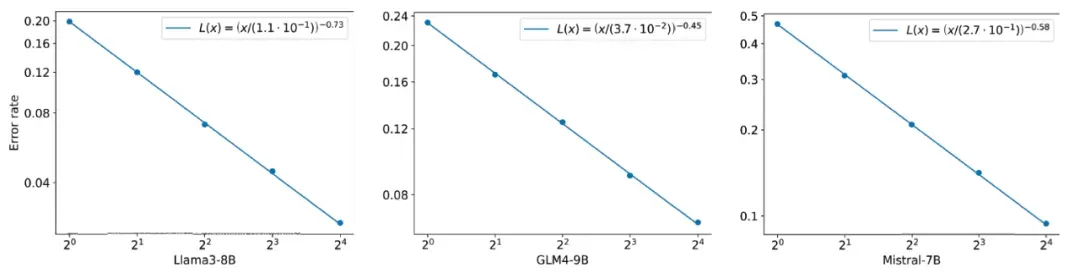
图 3 FoT 在不同基模型的性能
MATH 基准测试
在 MATH 数据集上,FoT 算法在不同复杂度级别的问题上均展现出一致的性能提升。如表 2 所示,从最简单的 level1 到最具挑战性的 level5,FoT(n=4)的准确率比 MCTSr 提高了约 10%。这种一致的提升凸显了 FoT 方法在处理从简单到复杂问题的有效性。
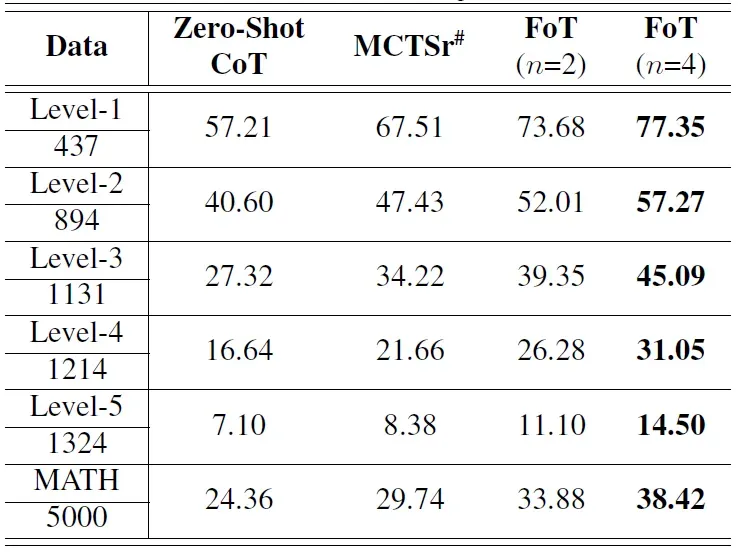
表 2 FoT 在 MATH 数据集上的性能
FoT 的广泛应用前景
FoT 框架不仅在理论上具有创新性,而且在实际应用中也具有广泛的前景。它可以帮助 LLM 在数学、逻辑、金融、医疗和法律等需要复杂推理的领域中更好地发挥作用。例如,在金融领域,FoT 可以用于风险评估和投资决策分析;在医疗领域,它可以辅助医生进行疾病诊断和治疗方案制定;在法律领域,FoT 可以用于案例分析和法律推理。此外,FoT 还可以与现有的 LLM 相结合,提升其在法律、教育、科研等领域的应用效果,为用户提供更加智能、准确的服务。
结语
思维森林 Forest-of-Thought 框架的提出,为 LLM 的推理能力提升提供了一条新的路径。它通过多路径探索和动态激活推理路径的结构化框架,有效解决了现有 LLM 推理范式中的关键局限。FoT 不仅提高了模型在复杂任务中的问题解决能力,还生成了多样化的推理结果,无需依赖反向传播或微调。随着大模型在日常工作和生活的不断渗透,FoT 有望在更多的应用场景中发挥重要作用,推动大模型向更智能、更高效的方向发展。


