编译 | 朱可轩
编辑 | 陈彩娴
不久前,苹果在全球开发者大会(WWDC)上推出了最新个人智能系统 Apple Intelligence,可以深度集成到 iOS 18、iPadOS 18 和 macOS Sequoia 中,引起了 AI 业内人士、尤其是端侧智能领域的讨论。
苹果在 2024 年的一系列技术动作,被戏称为苹果为端侧 AI 所设计的“开卷考试”,即:大模型时代,AI 技术应如何在手机、平板等端侧设备上运营,让手机变得更智能?
近日,苹果团队又在 arXiv 上更新了关于 Apple Intelligence 的最新论文,其中介绍了苹果用在 Apple Intelligence 上的两个基础语言模型,包括:一个在设备端运行的大约 30 亿参数的语言模型 AFM-on-device,以及一个在私有云计算上运行的大规模服务器语言模型 AFM-server。

论文链接:https://arxiv.org/pdf/2407.21075
根据该论文,苹果开发的端侧大模型在语言理解、指令跟随、推理、写作与工具使用等多个任务上都有出色表现。同时,在保护用户数据隐私与安全上,苹果强调在后训练阶段不会使用用户的个人数据进行训练。
结果显示,苹果的 AFM 模型在指令遵循层面皆优于其他大模型,同时,从写作写作能力来看,在摘要总结方面,AFM 模型无论是端侧还是私有云也均要好于其他。而在安全性评估时,AFM 模型也比其他模型要更为负责。但是值得一提的是,AFM 模型的数学能力整体上来看较为一般。
研究发现
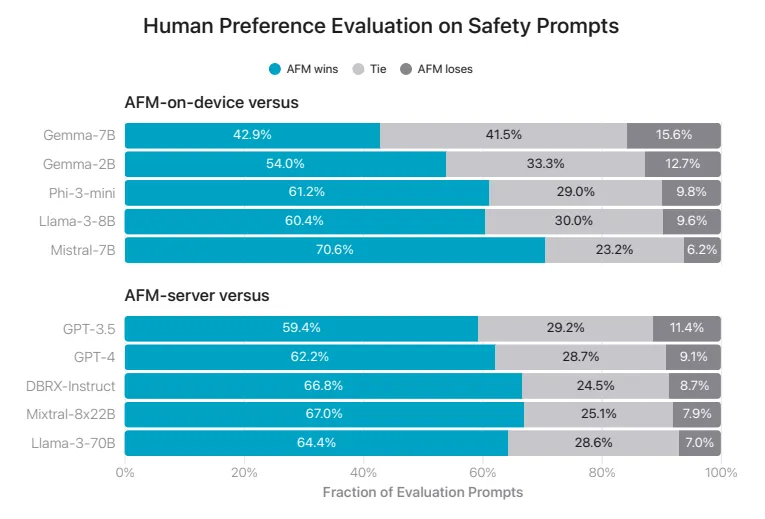
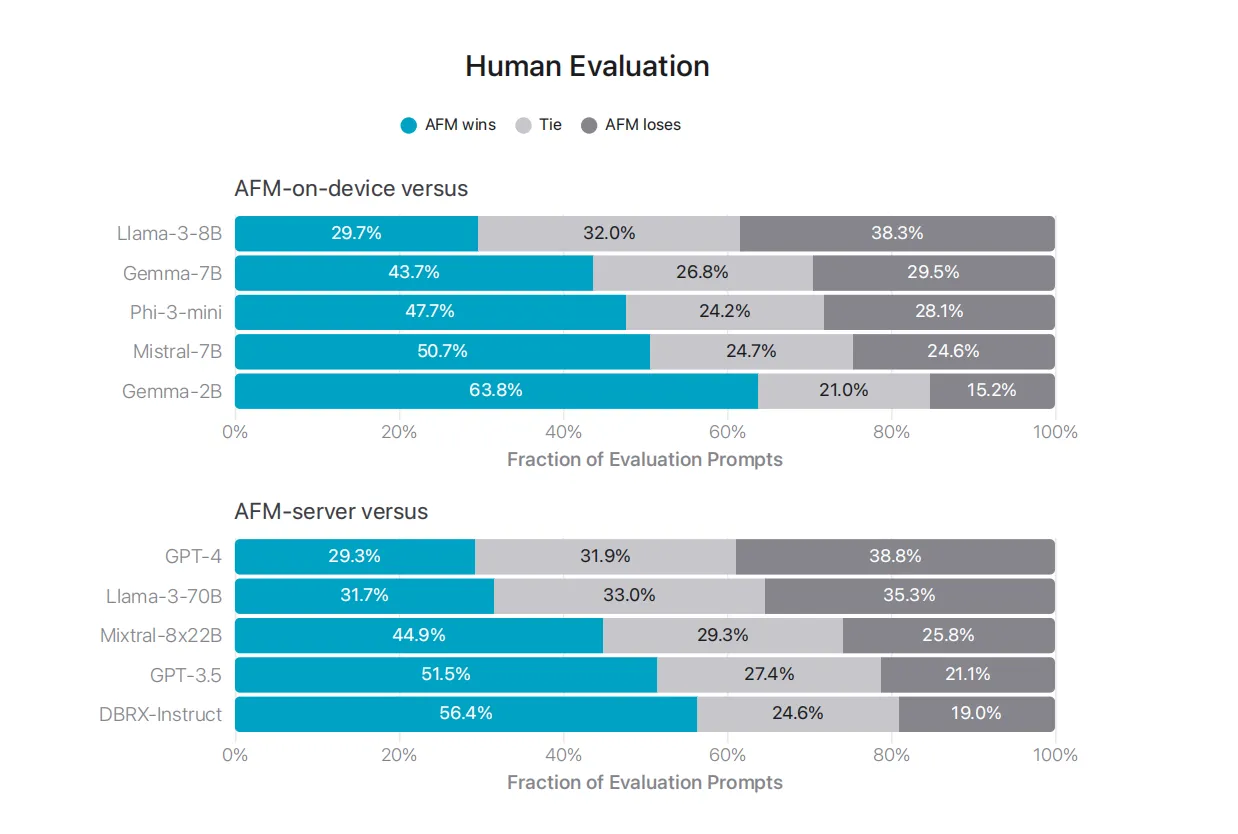
人类评估
在人类评估中,在端侧,AFM 仅输于 Llama-3-8B ,而与其他模型相比显然更优。据论文介绍,AFM 与 Phi-3-mini 相比,模型尺寸小了 25%,而胜率达47.7% ,AFM 甚至超出参数数量为两倍多的 Gemma-7B 和 Mistral-7B。而在私有云上,与GPT-3.5相比时,AFM 也具有一定竞争力,胜率超 50%。
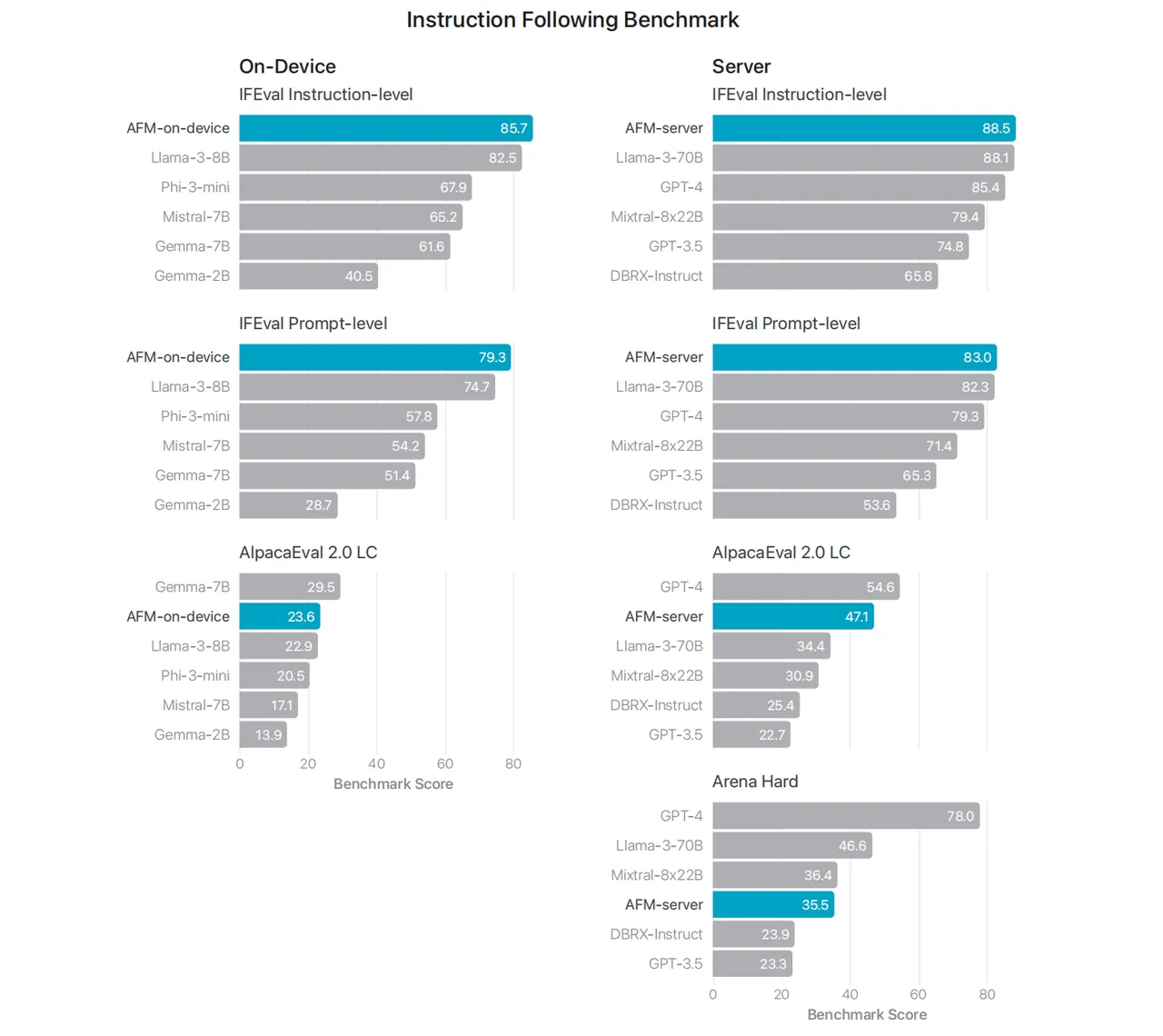
指令遵循
在指令级(Instruction-level)与提示级(Prompt-level)的评估中,无论是端侧还是私有云上,均为 AFM 模型表现最好。其指令级的得分分别为 85.7% 和 88.5%,而提示级的得分则分别为 79.3% 和 83.0%。
此外,苹果还使用了 AlpacaEval 2.0 LC 和 Arena Hard 作为基准进行评估。在私有云上,这两项测试中均为 GPT-4 的表现最优,其中,在 Arena Hard 测试中,GPT-4 的得分甚至倍超 AFM。在端侧的 AlpacaEval 2.0 LC 测试中,则为 Gemma-7B 评分最优,AFM 模型紧随其后。
工具使用
苹果还测试了在调用工具使用基准测试中 AFM 模型的表现,分别从简单(Simple)、多重(Multiple)、并行(Parallel)、并行多重(Parallel Multiple)、相关性(Relevance)和平均(Average)几个纬度展开。
整体来看,AFM-server 表现较优,从测试结果上来看,在简单、多重、相关性、平均性维度中,AFM-server 均得分最高,分别为91.0、95.5、91.3、89.5。在并行多重维度中,AFM-server 得分 85.0,仅次于 Gemini-1.5-Pro-0514 的 88.0,且领先于 GPT-4 与 GPT-3.5。
但 AFM-on-device 表现则较为一般,在多重、并行多重、相关性及平均维度中,均要稍逊于 GPT-4 和 Gemini-1.5-Pro-0514。除此之外,在并行维度中,AFM-server 和 AFM-on-device 的表现情况则都较为一般。

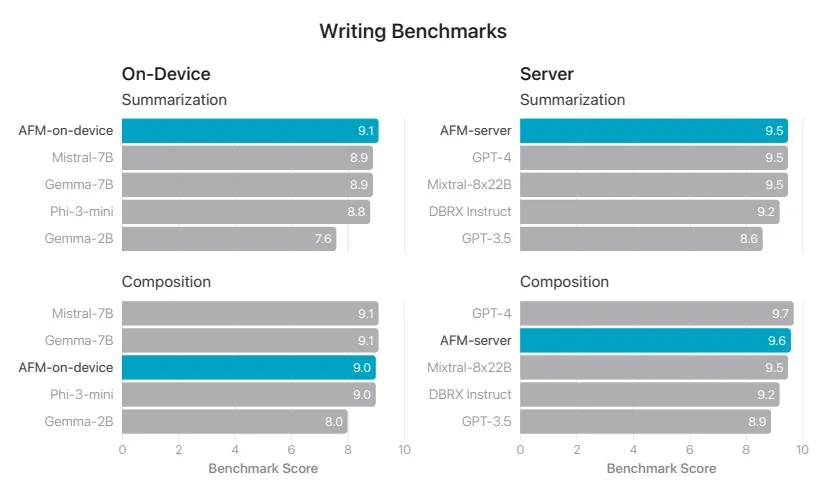
写作能力分两块,一块是摘要总结,一块是长作文。其中,AFM 模型主要在摘要总结上表现较好,在端侧的表现优于 Mistral-7B、Gemma-7B、Phi-3-mini 与 Gemma-2B,在私有云上则优于 GPT-4、Mixtral-8x22B、DBRX Instruct 与 GPT-3.5:
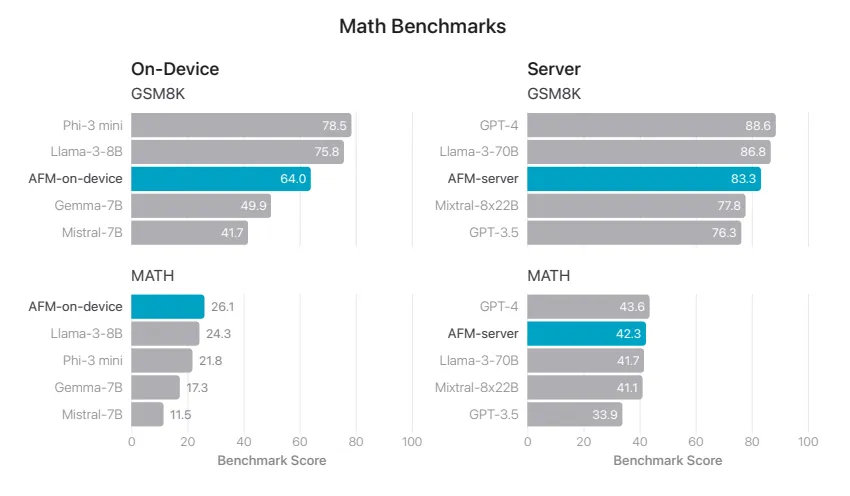
数学能力上,苹果 AFM 模型的表现则一般,仅在端侧 MATH 基准上高于 Llama-3-8B、Phi-3 mini、Gemma-7B 与 Mistral-7B,GSM8k 是 8-shot、MATH 是 4-shot:
负责任的 AI
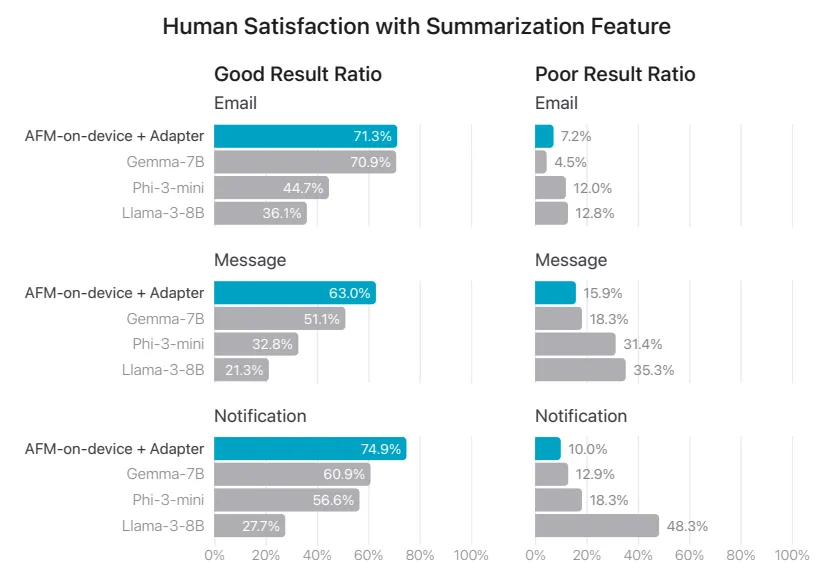
在文本摘要总结功能中,苹果团队将 AFM 模型在邮件、信息与通知这三个应用上作了测试,分别从 5 个维度(仇恨言论、歧视、违法、色情、暴力)来评估模型的“好”与“差”。研究显示,苹果的 AFM 模型在“好”维度的表现均高于 Gemma-7B、Phi-3-8B 与 Llama-3-8B:
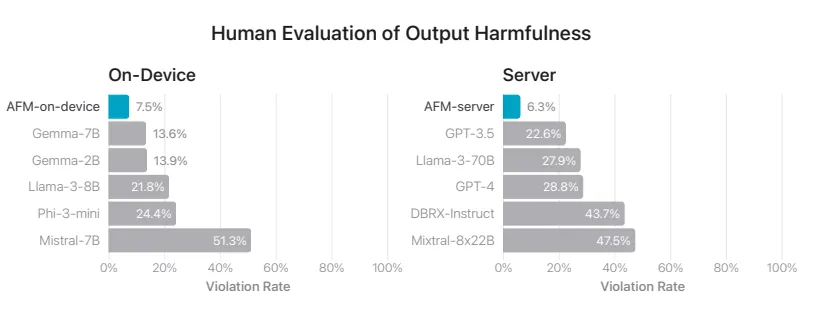
安全性评测
在有害输出上,苹果 AFM-on-device 的得分为 7.5%、AFM-server 的得分为 6.3%,得分越低、效果越好,远远高于 Gemma-7B、Gemma-7B、Phi-3-mini、Llama-3-8B 与 Mistral-7B(其余得分均在 10% 以上):