QKV的重要性
要理解大语言模型效果的底层实现原理,很大一部分就是理解Transformers Block里面的QKV矩阵。现在前沿的大模型研究工作很大一部分都是围绕着QKV矩阵去做的,比如注意力、量化、低秩压缩等等。
其本质原因是因为QKV权重占比着大语言模型50%以上的权重比例,在推理过程中,QKV存储量还会随着上下文长度的增长而线性增长,计算量也平方增加。
可以说,现在大模型对外销售OpenAPI的价格战,很大一部分就是对QKV极致优化的技术战;围绕QKV,各大模型厂商使出浑身解数,在保证效果不变坏的前提下,主要的研究工作就是对性能和存储的极致压缩。
在本文,我们将从纯概念的角度,增进对QKV的理解。
QKV在哪里
还是这张图,QKV矩阵是Transformers Block MHA的重要组成部分,当一个文本Token过来的时候,文本Token的Normalization矩阵会分别和Q、K、V的权重矩阵进行矩阵乘法操作,得到三个不同的矩阵,以进入后面的计算过程。
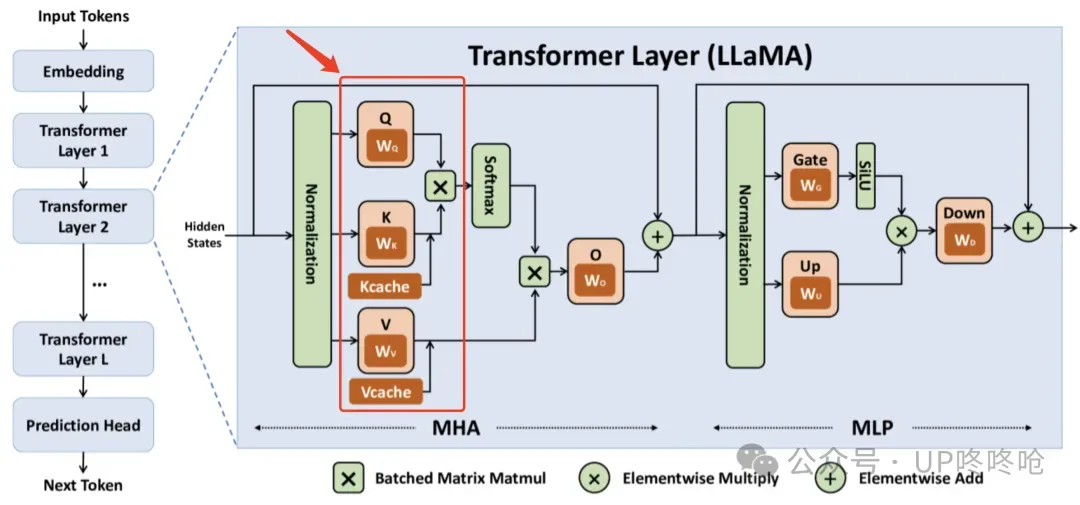 图片
图片
以7B模型为例,计算数据的Shape如下:
复制Token Normalization Shape:[1, 4096] Q、K、V Shape:[4096, 4096]
如果考虑一次推理的BatchSize和SeqLen(上下文长度),那就是这个Shape:
复制Token Normalization:[BatchSize, SeqLen, 4096] Q、K、V Shape:[BatchSize, SeqLen, 4096, 4096] 其中,4096就是7B模型对应的Hidden Size。
从Shape就可以看出,Q、K、V的计算量和存储量会随着SeqLen的增长而增长。
QKV的作用
从计算角度理解QKV始终不容易理解它的算法效果,所以本部分从概念的角度理解QKV的作用。
在大型语言模型(LLM)中,特别是在基于Transformer架构的模型中,Q(Query)、K(Key)和V(Value)是自注意力(Self-Attention)机制中的核心组成部分。它们在推理过程中的作用如下:
Query (Q):
角色:Query向量代表当前正在处理的token或位置,它表示模型需要“查询”的信息。
作用:在自注意力机制中,Query用于与所有的Key进行比较,以确定每个Key与当前token的相关性。这个比较的结果决定了Value的加权和,从而生成当前token的输出。
变化性:在自回归推理过程中,每个新生成的token都会有一个新的Query向量,它只依赖于当前token的信息。
Key (K):
角色:Key向量代表序列中每个token的唯一标识,用于与Query进行比较。
作用:Key向量用于计算与Query的相似度或匹配程度,这个相似度得分决定了相应Value在最终输出中的权重。
稳定性:在自回归推理中,对于已经生成的token,其Key向量在后续的推理过程中会被重复使用,因为它们代表的是已经确定的token信息。
Value (V):
角色:Value向量包含序列中每个token的实际内容或特征,它对生成当前token的输出有贡献。
作用:Value向量根据与Query的相似度得分(由Key确定)被加权求和,生成当前token的输出。
稳定性:与Key类似,对于已经生成的token,其Value向量在后续的推理过程中也会被重复使用。
在自回归推理过程中,模型一次生成一个token,并且每个新token都会基于之前所有token的信息。因此,对于每个新生成的token:
Q:需要重新计算,因为它依赖于当前token的信息。
K 和 V:可以被缓存(即KV Cache),因为它们代表之前已经生成的token的信息,这些信息在生成后续token时不需要重新计算。
总结来说,Q、K、V在推理过程中共同工作,通过自注意力机制允许模型在生成每个新token时动态地聚焦于序列中相关的信息。
Q代表了当前token的查询需求,而K和V则提供了序列中每个token的标识和内容,使得模型能够根据当前token的需求加权组合之前的信息,生成连贯和相关的输出。
为什么需要QKV,不能直接从Q得到输出呢?
在Transformer模型中,区分Q(Query)、K(Key)和V(Value)的原因主要有以下几点:
角色分离:
Q、K、V的设计允许模型在处理序列数据时,更有效地捕捉不同位置之间的关系。Q代表当前位置希望获得的信息,K代表序列中各位置能提供的信息,而V则代表当查询和键匹配时,应该从各位置获取的实际内容。
通过这种方式,模型可以灵活地捕捉不同位置之间的依赖关系。
增强模型能力:
使用独立的Q、K、V允许模型学习到更复杂的关系。每个位置不仅可以决定与其他位置的关联程度(通过Q和K),还可以决定从每个位置获取什么样的信息(通过V)。
灵活性和表达能力:
独立的Q、K、V矩阵增加了模型的灵活性和表达能力。模型可以学习到如何根据上下文将重点放在不同的信息上。
并行处理:
Transformer模型的设计允许在处理序列时进行高效的并行计算。Q、K、V的独立使得模型可以同时计算整个序列中所有位置的注意力分数,这大大提高了计算效率。
信息检索类比:
可以把Q、K、V机制类比为一个信息检索过程。
Q类似我们提出的搜索问题,目的是从大量信息中寻找相关答案;K类似信息库中的索引,它们决定哪些信息与查询相关;V类似实际的内容,是查询找到相关信息后的返回结果。
Q用来提出问题,K用来匹配相关性,V则是我们最终希望获取的信息。
综上所述,QKV的区分使得Transformer模型能够更加灵活和有效地处理序列数据,捕捉复杂的依赖关系,并适应不同的任务需求。
直接从Q得到V会限制模型的表达能力和灵活性,因为它忽略了通过K来确定相关性的重要性,并且减少了模型处理信息的灵活性。
在LLM推理时,为什么KV可以Cache?
在LLM(Large Language Model,大型语言模型)推理过程中,KV(Key-Value)Cache可以被缓存的原因主要基于以下几个方面:
减少重复计算:
在自注意力机制中,如果没有KV Cache,每次生成新token时,模型需要重新计算整个历史序列的Key和Value向量,并参与注意力计算,这导致了大量的重复计算。通过缓存历史序列的K和V,可以避免这种重复计算,显著降低推理的计算复杂度。
提升推理速度:
KV Cache通过缓存Key和Value向量,使得模型在生成新token时只需计算当前token的Query向量,并与缓存的Key和Value进行注意力计算,这样可以加快推理速度。
降低计算复杂度:
自注意力机制的计算复杂度为O(n^2⋅d),其中n是序列长度,d是向量维度。使用KV Cache后,计算复杂度可以降低到O(n⋅d),显著减少了计算量。
跨请求复用:
在某些场景下,多次请求的Prompt可能会共享同一个前缀(Prefix),这些情况下,很多请求的前缀的KV Cache计算结果是相同的,可以被缓存起来,给下一个请求复用。
综上所述,KV Cache在LLM推理中通过缓存Key和Value向量,有效减少了重复计算,降低了计算复杂度,提升了推理速度,并且优化了显存资源的使用,从而提高了模型的推理效率和吞吐量。
那为什么Q不可以Cache?
因为Q不需要Cache…
在LLM(Large Language Model,大型语言模型)推理过程中,不缓存Q(Query)的原因主要有以下几点:
依赖性差异:
在自回归Transformer模型中,每个新生成的token的输出(即Q)只依赖于当前token的Q以及之前所有token的K和V。
因此,对于计算下一个token的输出,不需要重复使用之前的Q,而K和V则需要被重复使用。
计算效率:
由于每次推理只会用到当前的Q,而这个Q在下次推理时不会被再次使用,因此缓存Q不会带来效率上的提升。
相反,K和V在每次推理中都需要被使用,缓存KV可以避免重复计算,从而加速推理过程。
自回归特性:
在自回归模型中,每个Token的生成仅依赖于它之前的所有Token,这意味着每个新Token的生成只需要当前的Q和之前所有Token的KV。由于每个Q都是基于前面序列来生成的,缓存Q对于计算Attention没有意义。
综上所述,由于Q在自回归Transformer模型中的使用特性和计算过程中的不对称性,缓存Q不会带来推理效率的提升,因此LLM推理过程中通常不缓存Q。
为什么区分MHA和MLP?
在Transformer模型中,Multi-Head Attention (MHA) 和 Multi-Layer Perceptron (MLP) 是两个核心组件,它们各自承担着不同的功能,共同协作以提升模型的性能。
MHA 的作用:
捕捉上下文信息:MHA通过多个头的方式,可以同时关注输入序列的不同部分,从而增强模型对上下文信息的捕捉能力。
提高模型的表达能力:MHA允许模型在不同的表示子空间中学习信息,这有助于模型学习到更丰富的特征表示。
**处理长序列数据:**虽然MHA的计算量较大,特别是对于长序列,但它通过并行计算和优化策略(如稀疏注意力)来提高效率1。
MLP 的作用:
非线性映射:MLP通过多层感知机对MHA的输出进行非线性变换,这有助于模型学习到更复杂的特征表示。
提升模型的表达能力:MLP的引入使得模型能够捕捉到输入数据中的非线性关系,从而提高模型的表达能力。
整合特征:MLP将MHA提取的特征进行整合和进一步处理,为模型的输出提供必要的特征表示。
MHA和MLP的协同作用:
特征提取与整合:MHA负责提取输入序列的上下文特征,而MLP则负责对这些特征进行进一步的整合和转换,两者共同工作以提高模型的性能2。
通过区分MHA和MLP两个部分,Transformer模型能够更有效地捕捉输入序列的上下文信息,并学习到更丰富的特征表示,从而在自然语言处理任务中取得优异的性能。


