InstructMove是一种基于指令的图像编辑模型,使用多模态 LLM 生成的指令对视频中的帧对进行训练。该模型擅长非刚性编辑,例如调整主体姿势、表情和改变视点,同时保持内容一致性。此外,该方法通过集成蒙版、人体姿势和其他控制机制来支持精确的局部编辑。

相关链接
- 论文:http://arxiv.org/abs/2412.12087v1
- 主页:https://ljzycmd.github.io/projects/InstructMove/
论文介绍

通过观察事物如何移动的基于指令的图像操作
摘要
本文介绍了一种新颖的数据集构建流程,该流程从视频中抽取帧对并使用多模态大型语言模型 (MLLM) 生成编辑指令,以训练基于指令的图像处理模型。视频帧本质上保留了主体和场景的身份,确保在编辑过程中内容保存的一致性。此外,视频数据捕捉了各种自然动态(例如非刚性主体运动和复杂的相机运动),否则很难建模,使其成为可扩展数据集构建的理想来源。使用这种方法,我们创建了一个新数据集来训练 InstructMove,该模型能够进行基于指令的复杂操作,而这些操作很难通过合成生成的数据集实现。我们的模型在调整主体姿势、重新排列元素和改变相机视角等任务中表现出最先进的性能。
方法
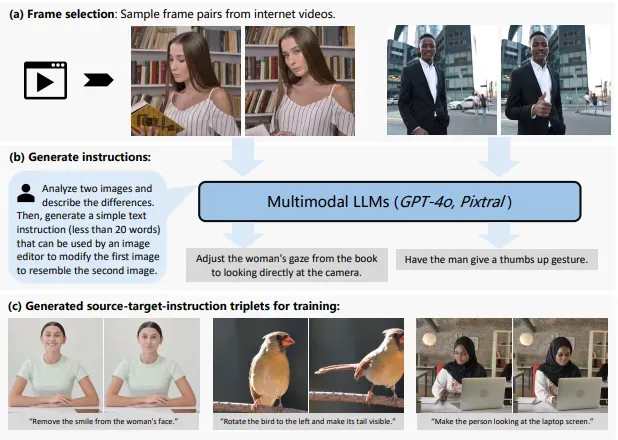
数据构建管道:
- 首先从视频中采样合适的帧对,确保转换逼真且适度。
- 这些帧对用于提示多模态大型语言模型 (MLLM) 生成详细的编辑指令。
- 此过程会产生一个具有逼真图像对和精确编辑指令的大规模数据集。
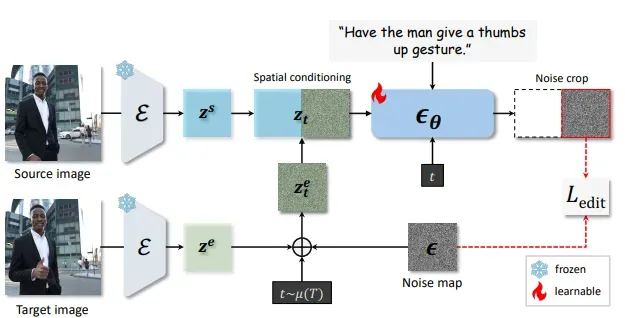
基于指令的图像编辑的模型架构概述。首先使用预训练编码器将源图像和目标图像编码为潜在表示 zs和 ze。然后通过前向扩散过程将目标潜在 z e转换为噪声潜在 zet。沿宽度维度连接源图像潜在和噪声目标潜在以形成模型输入,该输入被输入到去噪 U-Net ϵθ 中以预测噪声图。输出的右半部分(对应于噪声目标输入)被裁剪并与原始噪声图进行比较。
结果

 与最先进的图像编辑方法进行定性比较,包括基于描述和基于指令的方法。现有方法难以处理复杂的编辑,例如非刚性变换(例如姿势和表情的变化)、对象重新定位或视点调整。它们通常要么无法遵循编辑说明,要么产生不一致的图像,例如身份转变。相比之下,论文的方法在具有自然变换的真实视频帧上进行训练,成功处理了这些编辑,同时保持了与原始输入图像的一致性。
与最先进的图像编辑方法进行定性比较,包括基于描述和基于指令的方法。现有方法难以处理复杂的编辑,例如非刚性变换(例如姿势和表情的变化)、对象重新定位或视点调整。它们通常要么无法遵循编辑说明,要么产生不一致的图像,例如身份转变。相比之下,论文的方法在具有自然变换的真实视频帧上进行训练,成功处理了这些编辑,同时保持了与原始输入图像的一致性。
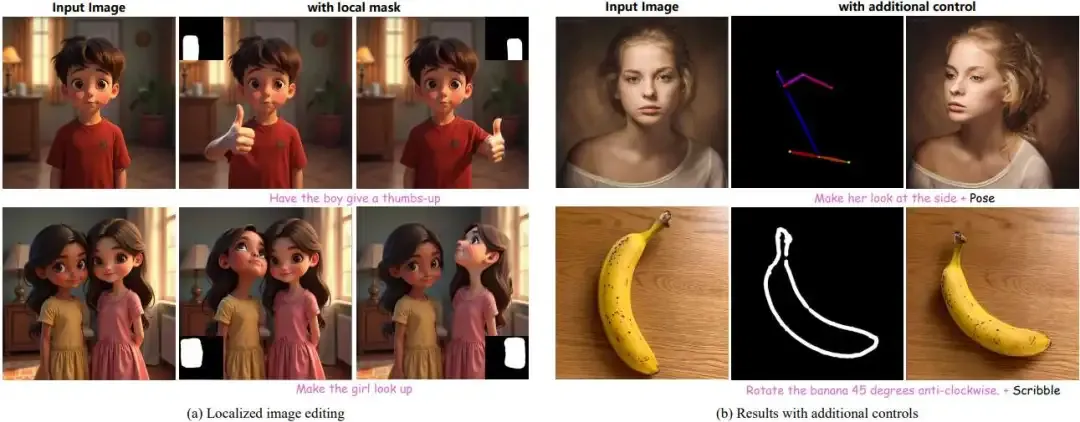 该方法与附加控制的定性结果。
该方法与附加控制的定性结果。
- 模型可以利用掩码来指定要编辑图像的哪个部分,从而实现局部调整并解决指令中的歧义。
- 与 ControlNet 结合使用时,该模型可以接受其他输入,例如人体姿势或草图,以实现对主体姿势或物体定位的精确编辑。 以前的方法无法实现这种级别的控制。
结论
文章提出了一种对视频帧进行采样并利用 MLLM 生成编辑指令以训练基于指令的图像处理模型的方法。与依赖于合成生成的目标图像的现有数据集不同,该方法利用来自视频和 MLLM 的监督信号来支持复杂的编辑,例如非刚性变换和视点变化,同时保持内容一致性。未来的工作可以集中在改进过滤技术上,无论是通过改进 MLLM 还是结合人机交互过程,以及将视频数据与其他数据集集成以进一步增强图像编辑功能。


