今天,给大家介绍上大、腾讯等提出的3D服装合成新方法ClotheDreamer,它以其革命性的能力,从简单的文本提示直接生成高保真、可穿戴的3D服装资产,正在重塑电商与空间计算领域的未来。数字人也能实现穿、脱衣自由了!


相关链接
论文阅读:https://arxiv.org/pdf/2406.16815
代码地址:https://github.com/ggxxii/clothedreamer(即将开源)
项目地址:https://ggxxii.github.io/clothedreamer/
论文阅读
 clothedreaming:文本引导的3D高斯服装生成
clothedreaming:文本引导的3D高斯服装生成
摘要
从文本合成高保真 3D 服装对于数字化身创建来说既是理想的也是具有挑战性的。最近基于扩散的分数蒸馏采样 (SDS) 方法已经实现了新的可能性,但要么与人体错综复杂地耦合,要么难以重复使用。
我们介绍了 ClotheDreamer,这是一种基于 3D 高斯的方法,用于从文本提示生成可穿戴、可用于生产的 3D 服装资产。我们提出了一种新颖的表示解缠结服装高斯溅射 (DCGS) 来实现单独优化。DCGS 将穿衣的化身表示为一个高斯模型,但冻结了身体高斯溅射。为了提高质量和完整性,我们结合双向 SDS 分别监督穿衣的化身和服装 RGBD 渲染和姿势条件,并提出了一种针对宽松服装的新修剪策略。
我们的方法还可以支持自定义服装模板作为输入。得益于我们的设计,合成的 3D 服装可以轻松应用于虚拟试穿并支持物理精确的动画。大量实验证明了我们方法的卓越和竞争力。
方法
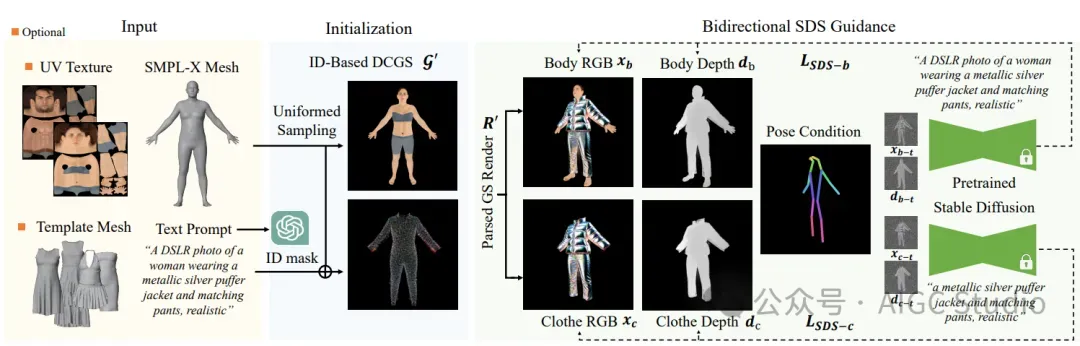 ClotheDreamer 概述。给定一个文本描述,我们首先利用 ChatGPT 确定衣服 ID 类型以进行初始化。我们引入了解缠衣服高斯溅射 (DCGS),它将穿衣服的化身表示为单高斯模型,但冻结身体高斯溅射以实现单独的监督。借助解析高斯溅射 (GS) 渲染,我们使用 Bidreactional SDS 分别根据姿势条件指导衣服和身体 RGBD 渲染。我们还支持模板网格输入,用于多功能个性化 3D 服装生成。
ClotheDreamer 概述。给定一个文本描述,我们首先利用 ChatGPT 确定衣服 ID 类型以进行初始化。我们引入了解缠衣服高斯溅射 (DCGS),它将穿衣服的化身表示为单高斯模型,但冻结身体高斯溅射以实现单独的监督。借助解析高斯溅射 (GS) 渲染,我们使用 Bidreactional SDS 分别根据姿势条件指导衣服和身体 RGBD 渲染。我们还支持模板网格输入,用于多功能个性化 3D 服装生成。
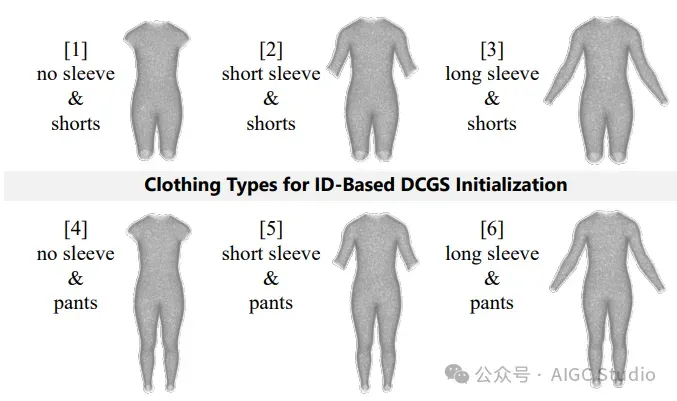
服装类型。我们提供了六个常用组来初始化零拍摄服装生成中的DCGS。
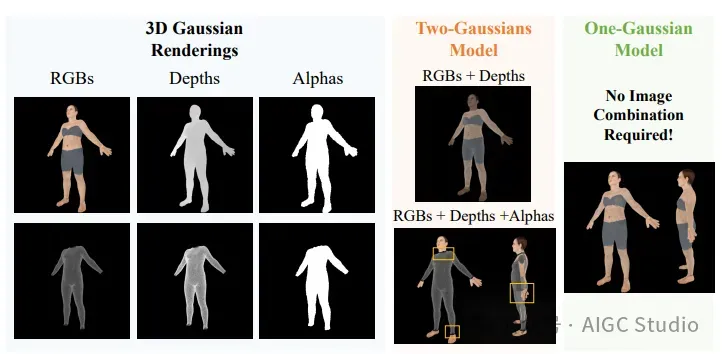
高斯初始化的重要性。用双高斯模型渲染穿衣服的角色时可能会出现伪影。
实验
动画结果
 ###自动试穿 ClotheDreamer 生成的服装可以适合不同的体形。
###自动试穿 ClotheDreamer 生成的服装可以适合不同的体形。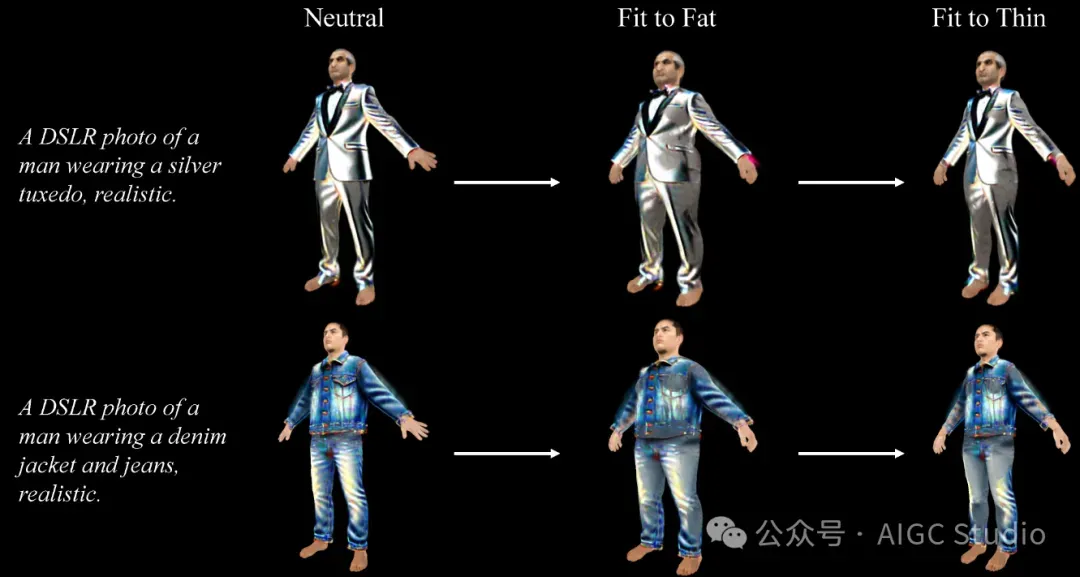
 服装文本生成的定性比较。我们比较了最新的最先进的3D生成基线在七种不同的服装文字描述。请注意,红色文本强调未完成的服装生成,而橙色箭头表示多余人体部位的几何伪影。
服装文本生成的定性比较。我们比较了最新的最先进的3D生成基线在七种不同的服装文字描述。请注意,红色文本强调未完成的服装生成,而橙色箭头表示多余人体部位的几何伪影。

模板引导服装生成结果

双向SDS制导的消融研究

松衣修剪策略的消融研究
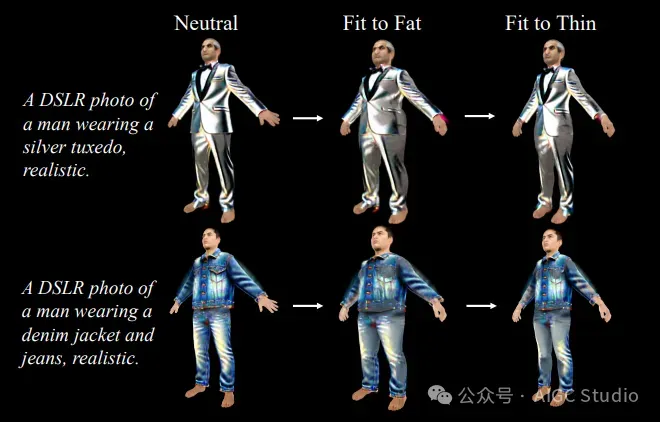
适合不同体型的DCGS服装
结论
本文介绍了 ClotheDreamer,这是一种从文本提示生成多样且可穿戴的3D服装的创新方法。本文提出了一种新颖的表示方法,名为Disentangled Clothe Gaussian Splatting (DCGS),能够有效地将衣服与身体解耦。本文还提出了双向SDS指导,它分别监督带有姿态条件的服装化身RGBD渲染,并引入了一种新的修剪策略,以增强宽松服装的生成完整性。此外,本文展示了通过结合模板网格原语进行个性化生成的多样性。本文的DCGS服装可以通过模拟的网格先验实现逼真的布料动画。实验和用户研究表明,本文的方法在外观和几何质量方面优于最先进的方法。
局限性和未来工作。尽管 ClotheDreamer 展示了令人鼓舞的结果,但它仍然存在一些局限性。首先,本文的方法目前整合了上衣和下衣,更精细的解耦将适用于更复杂的试穿场景。其次,类似于其他基于SDS的方法,本文的方法在某些情况下也会出现颜色过饱和的问题。本文相信,探索改进SDS的方法可以帮助缓解这个问题。最后,探索为3D高斯表示disentangling lighting以增强逼真度也是一个有趣的未来方向。最后,disentangling lighting 增强真实感的 3D 高斯表示也是一个有趣的未来方向。


