2月24日,360智脑团队与北京大学联合研发的中等量级推理模型 Tiny-R1-32B-Preview 正式发布。这一模型仅以5%的参数量,成功逼近了 Deepseek-R1-671B 的满血性能,展现了小模型在高效推理领域的巨大潜力。
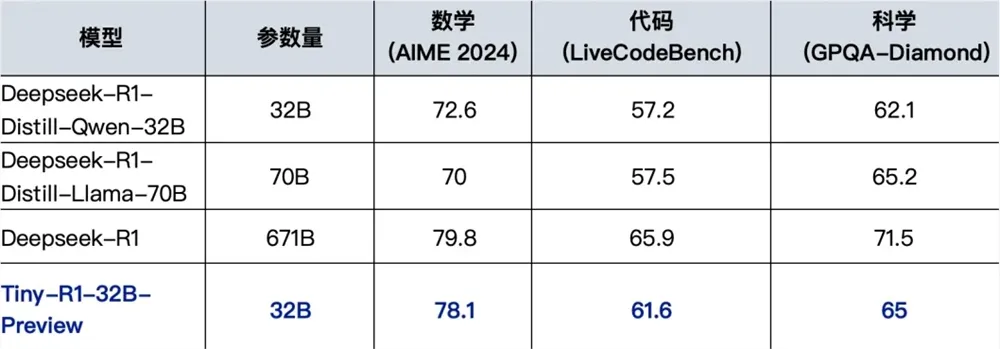
该模型在多个关键领域的表现尤为突出。在数学领域,Tiny-R1-32B-Preview 在 AIME2024评测中取得了78.1分的成绩,与原版 R1模型的79.8分相当接近,远超 Deepseek-R1-Distill-Llama-70B 的70.0分。在编程和科学领域,该模型分别在 LiveCodeBench 和 GPQA-Diamond 测试中取得了61.6分和65.0分的成绩,全面领先于当前最佳开源70B模型 Deepseek-R1-Distill-Llama-70B。这一成果不仅证明了 Tiny-R1-32B-Preview 在性能上的卓越表现,还通过仅需5%的参数量大幅降低了推理成本,实现了效率的跃迁。
这一突破背后的核心技术是“分治-融合”策略。研究团队基于 DeepSeek-R1生成海量领域数据,分别训练了数学、编程、科学三大垂直领域的模型。随后,通过 Arcee 团队的 Mergekit 工具进行智能融合,突破了单一模型的性能上限,实现了多任务的均衡优化。这种创新的技术路径不仅提升了模型的性能,也为未来推理模型的发展提供了新的思路。
360智脑团队和北京大学的联合研发团队表示,Tiny-R1-32B-Preview 的成功离不开开源社区的支持。该模型受益于 DeepSeek-R1蒸馏、DeepSeek-R1-Distill-32B 增量训练以及模型融合等技术。
为了推动技术普惠,研发团队承诺将公开完整的模型仓库,包括技术报告、训练代码及部分数据集。模型仓库已上线至 Hugging Face 平台,地址为 https://huggingface.co/qihoo360/TinyR1-32B-Preview。