编辑 | 白菜叶
经过大规模预训练的基础模型已在非医学领域取得了巨大成功。然而,训练这些模型通常需要大量全面的数据集,这与生物医学成像中常见的较小且更专业的数据集形成鲜明对比。
德国弗劳恩霍夫数字医学研究所(Fraunhofer Institute for Digital Medicine MEVIS)的研究人员提出了一种多任务学习策略,将训练任务数量与内存需求分离开来。
他们在多任务数据库(包括断层扫描、显微镜和 X 射线图像)上训练了一个通用生物医学预训练模型 (UMedPT),并采用了各种标记策略,例如分类、分割和物体检测。UMedPT 基础模型的表现优于 ImageNet 预训练和之前的 STOA 模型。
在外部独立验证中,使用 UMedPT 提取的成像特征被证明为跨中心可转移性树立了新标准。
该研究以「Overcoming data scarcity in biomedical imaging with a foundational multi-task model」为题,于 2024 年 7 月 19 日发布在《Nature Computational Science》。

深度学习由于其学习和提取有用图像表示的能力,正在逐步革新生物医学图像分析。
一般的方法是通过在大规模自然图像数据集(如 ImageNet 或 LAION)上预训练模型,再针对具体任务进行微调或直接使用预训练特征。但是微调需要更多计算资源。
同时,生物医学成像领域需要大量标注数据进行有效的深度学习预训练,但这类数据往往比较稀缺。
多任务学习(MTL)通过同时训练一个模型来解决多个任务,提供了数据稀缺的解决方案。它利用生物医学成像中许多小型和中型数据集,预训练适用于所有任务的图像表示,适用于数据稀缺的领域。
MTL 已被应用于多种方式的生物医学图像分析,包括从不同任务的多个小型和中型数据集训练,以及在单个图像上使用多种标签类型,证明了共享特征可以提高任务性能。
在最新的研究中,为了将具有不同标签类型的多个数据集结合起来进行大规模预训练,MEVIS 研究所的研究人员引入了一种多任务训练策略和相应的模型架构,专门通过学习跨不同模态、疾病和标签类型的多功能表示来解决生物医学成像中的数据稀缺问题。
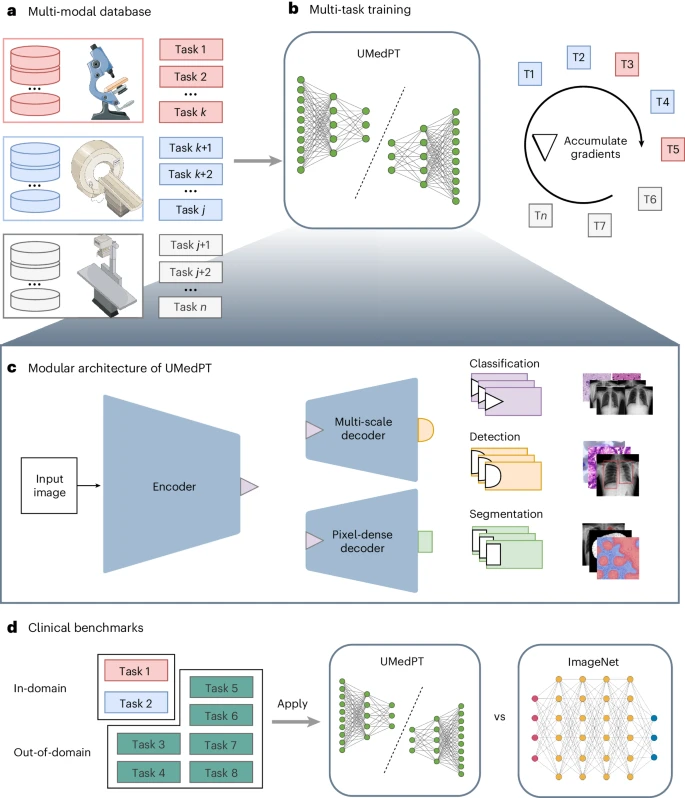
图示:研究概述。(来源:论文)
为了应对大规模多任务学习中遇到的内存限制,该方法采用了基于梯度累积的训练循环,其扩展几乎不受训练任务数量的限制。
在此基础上,研究人员使用 17 个任务及其原始注释训练了一个名为 UMedPT 的全监督生物医学成像基础模型。
下图展示了该团队的神经网络的架构,它由共享块组成,包括编码器、分割解码器和定位解码器,以及特定于任务的头。共享块经过训练可适用于所有预训练任务,有助于提取通用特征,而特定任务的主管则处理特定于标签的损失计算和预测。
设定任务包括三种监督标签类型:物体检测、分割和分类。例如,分类任务可以对二元生物标记进行建模,分割任务可以提取空间信息,物体检测任务可用于根据细胞数量训练生物标记。
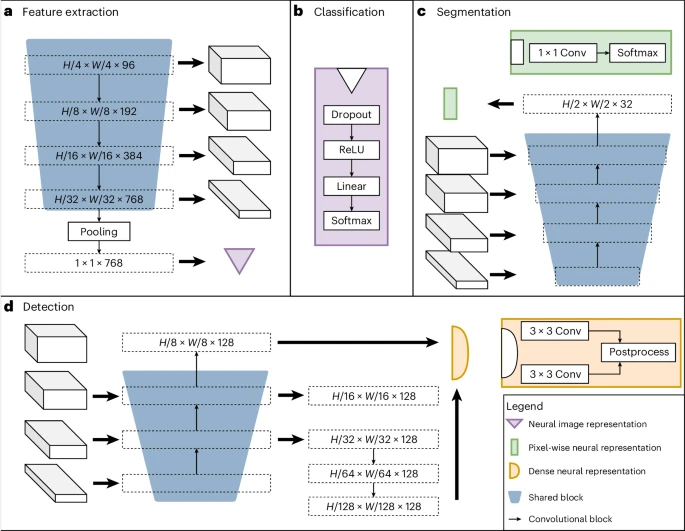
图示:UMedPT 的架构。(来源:论文)
UMedPT 在域内和域外任务中始终匹配或超越预训练的 ImageNet 网络,同时在直接应用图像表示(冻结)和微调设置时,使用较少的训练数据保持强劲的性能。
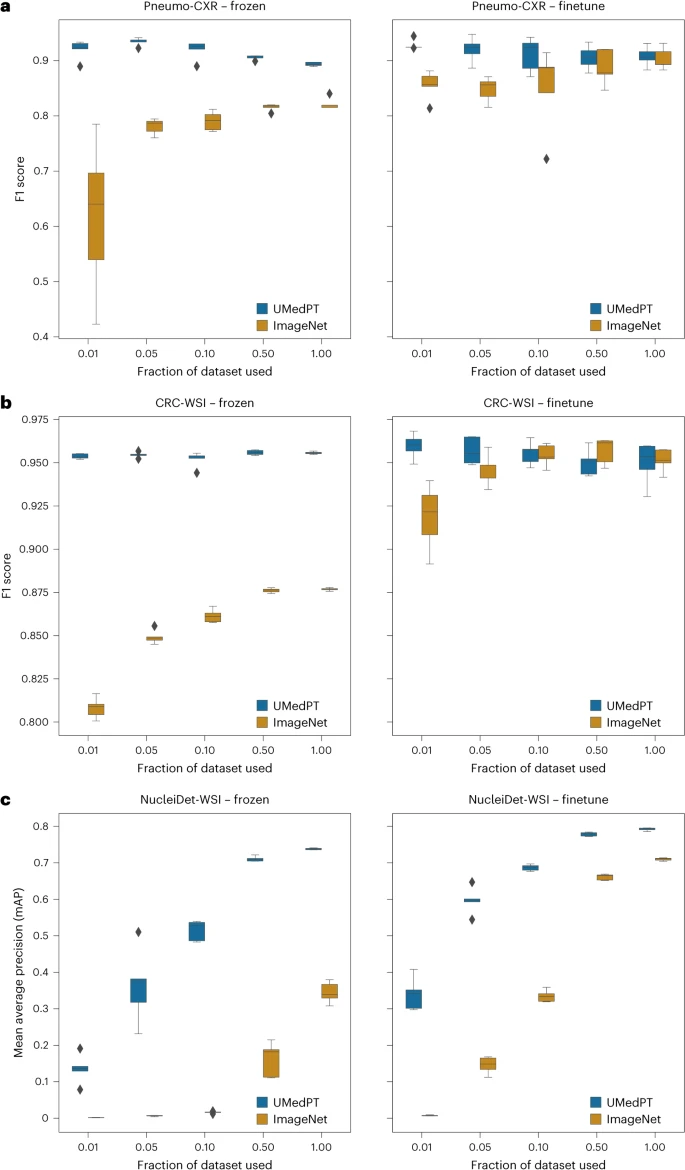
图示:域内任务的结果。(来源:论文)
对于与预训练数据库相关的分类任务,UMedPT 仅使用 1% 的原始训练数据,就能够在所有配置上达到 ImageNet 基线的最佳性能。与使用微调的模型相比,该模型使用冻结编码器实现了更高的性能。
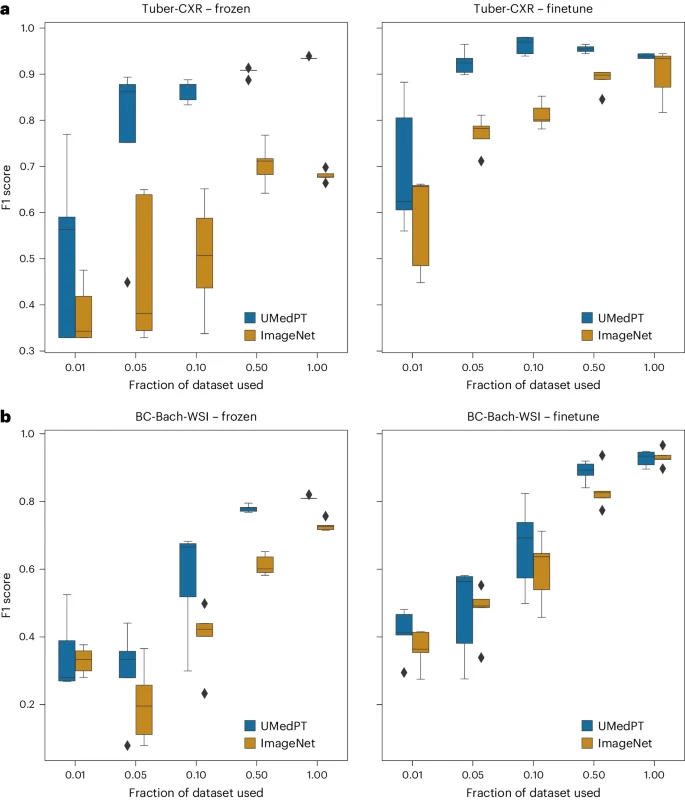
图示:域外任务的结果(来源:论文)
对于领域外的任务,即使应用了微调,UMedPT 也能够仅使用 50% 或更少的数据来匹配 ImageNet 的性能。
另外,研究人员将 UMedPT 的性能与文献中报告的结果进行了比较。使用冻结编码器配置时,UMedPT 在大多数任务中都超过了外部参考结果。在此设置下,它还超越了 MedMNIST 数据库 16 中的平均曲线下面积 (AUC)。
值得注意的是,UMedPT 的冻结应用未超越参考结果的任务属于领域外(乳腺癌分类 BC-Bach-WSI 和 CNS 肿瘤诊断 CNS-MRI)。通过微调,使用 UMedPT 进行预训练在所有任务中均超过了外部参考结果。
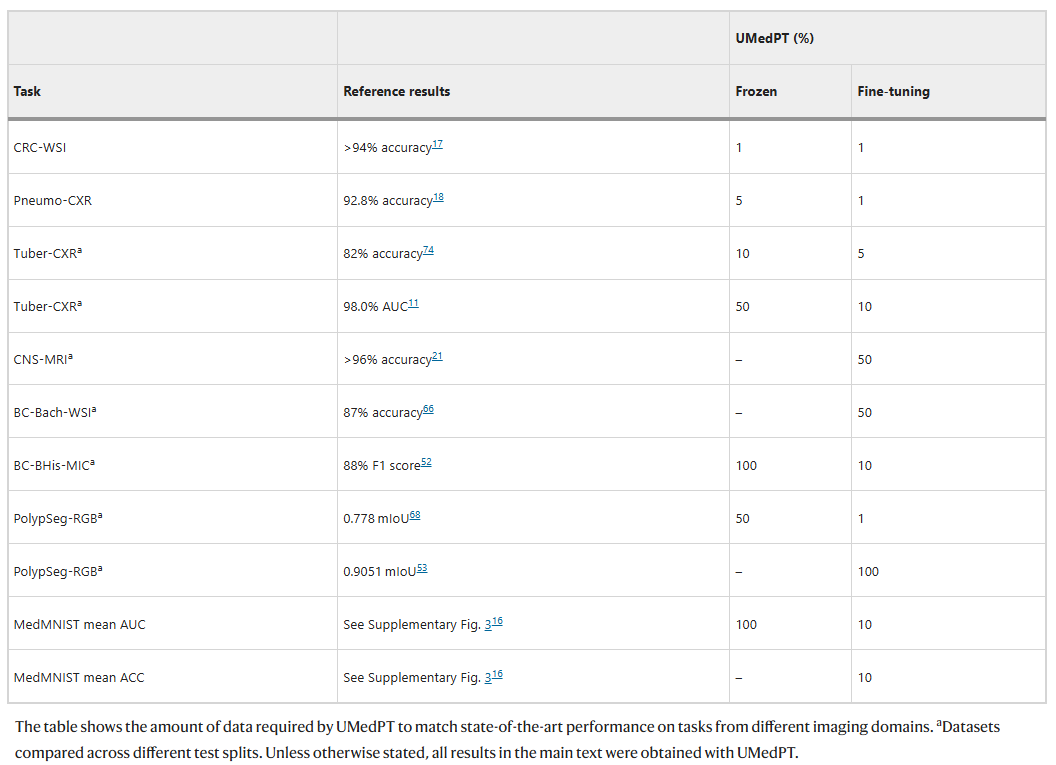
图示:UMedPT 在不同成像领域的任务上达到最新性能所需的数据量。(来源:论文)
作为数据稀缺领域未来发展的基础,UMedPT 开辟了深度学习在收集大量数据特别具有挑战性的医学领域的应用前景,例如罕见疾病和儿科影像。
论文链接:https://www.nature.com/articles/s43588-024-00662-z
相关内容:https://www.nature.com/articles/s43588-024-00658-9