
选择正确的 RAG(检索增强生成)架构主要取决于具体的用例和实施要求,确保系统符合任务需求。
Agentic RAG 的重要性将日益增加,与Agentic X的概念相一致,其中代理能力嵌入个人助理和工作流程中。
这里的“X”代表代理系统的无限适应性,能够实现无缝任务自动化和跨不同环境的明智决策,从而提高组织效率和自主性。综合不同的文档来源对于有效解决复杂、多部分的查询至关重要。
一、概述
提供准确的 RAG 实现的挑战包括检索相关数据、准确解释用户意图以及利用 LLM 的推理能力完成复杂任务。可以通过像 ReAct 这样的 RAG 的代理方法增强推理能力,其中创建了事件的推理和行为序列。
我从这项研究中发现一个有趣的事实:它指出没有一个解决方案可以适合所有数据增强的 LLM 应用程序。
上下文是指围绕对话的信息,可帮助人工智能理解用户的意图并提供相关、连贯的响应。
这包括用户之前的输入、当前任务、环境以及任何可能影响对话的外部数据等因素。
有效的上下文处理使人工智能能够保持一致和个性化的对话,根据正在进行的互动调整响应并确保对话感觉自然且有意义。
用户意图检测
在许多情况下,系统性能不佳的根源要么是未能确定任务的重点,要么是需要多种技能组合的任务,必须仔细区分这些技能才能获得最佳结果。
意图是指用户输入背后的潜在目的或目标,代表用户希望通过查询实现或传达什么。
识别意图可以让人工智能系统做出适当的反应。
二、RAG数据分类
级别 1:显式事实查询
直接询问具体的已知事实。
查询是关于给定数据中直接存在的明确事实,不需要任何额外的推理。
这是最简单的查询形式,其中模型的任务主要是定位和提取相关信息。当用户提出问题时,RAG 实现会针对分块数据中包含的事实进行定位。
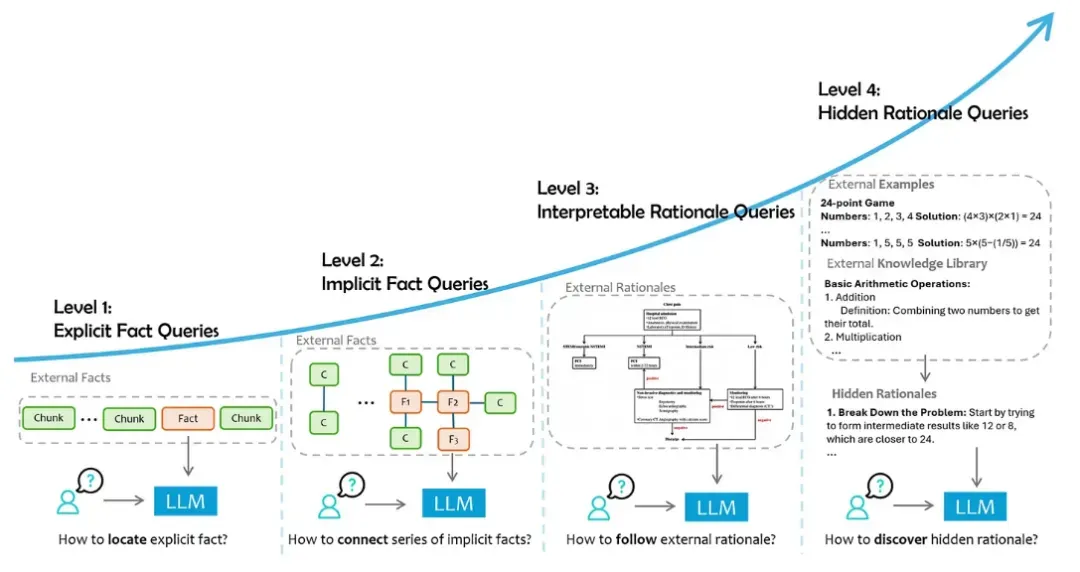
级别 2:隐式事实查询
间接寻找事实,需要解释来确定答案。
查询涉及数据中的隐含事实,这些事实不是显而易见的,可能需要一定程度的常识推理或基本的逻辑推论。
必要的信息可能分布在多个部分或需要简单的推理。
例如,What is the majority party now in the country where Canberra is located?可以通过将堪培拉位于澳大利亚这一事实与澳大利亚当前多数党的信息结合起来回答这个问题。
在第二级中,我们开始看到推理和行动元素的引入,因此对 RAG 采取了更具代理性的方法。
级别 3:可解释的原理查询
专注于理解事实背后的推理,并需要支持逻辑解释的数据。
这些查询既需要事实知识,也需要解释和应用对数据背景至关重要的特定领域指南的能力。
这样的理由通常在外部资源中提供,但在通用语言模型的初始预训练中很少遇到。
例如,在财务审计中,LLM可能需要遵循监管合规指南来评估公司的财务报表是否符合标准。
同样,在技术支持方面,可能需要遵循故障排除工作流程来协助用户,确保响应准确并符合既定协议。
级别 4:隐藏的理性质疑
寻求更深入的见解,通常需要基于上下文的推理来揭示潜在的含义或影响。
此类查询需要人工智能根据数据中观察到的模式和结果来推断未明确记录的复杂原理。
这些隐藏的理由涉及隐含的推理和逻辑联系,很难精确定位和提取。
例如,在 IT 运营中,语言模型可能会分析过去事件解决的模式以确定成功的策略。
同样,在软件开发中,人工智能可以借鉴过去的调试案例来推断有效的问题解决方法。通过综合这些隐含的洞察,模型能够提供反映细致入微、基于经验的决策的响应。
可解释和隐藏的原理将焦点转移到 RAG 系统理解和应用数据背后的推理的能力。
这些层次需要更深层次的认知过程,其中代理框架与专家知识相一致或从非结构化历史数据中提取见解。
三、小结

根据研究并考虑上图,需要明确事实的查询和依赖于隐性推理的查询之间存在区别。
例如,有关签证资格的查询需要领事馆指南中的明确事实(L3),而有关对公司未来发展的经济影响的问题则需要对财务报告和经济趋势进行分析(L4)。
两种情况下的数据依赖性都强调了外部来源的重要性——无论是官方文献还是专家分析。
在这两种情况下,提供理由有助于将回答内容具体化,不仅提供答案,还提供背后的合理推理。


