论文有两位共同一作。何秉翔,清华大学博士一年级,研究方向为大语言模型对齐、强化学习。张文斌,哈尔滨工业大学博士一年级,研究方向为自然语言处理。
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
尽管已有诸多研究致力于扩展偏好数据集的规模并优化标注方式,但对于哪些因素会对偏好数据集的对齐性能产生影响缺乏系统性分析,导致优化策略往往依赖经验,缺乏明确的原则指导。
这不禁引发了一个核心问题:哪些因素会影响偏好数据集的对齐性能?
为填补这一空白,近期来自清华大学、哈尔滨工业大学和阿里安全的研究团队提出 AIR(Annotations, Instructions, Response Pairs)框架,系统性地剖析构成偏好数据集的三大核心要素:标注(Annotations)、指令(Instructions)与回复对(Response Pairs),并通过控制变量实验,量化不同组件对于最终对齐效果的独立贡献。
研究团队在 MT-Bench(多轮对话)、ArenaHard(复杂推理)、AlpacaEval 2.0(指令遵循)等 6 大评测集构建实验矩阵,覆盖编码、数学、知识推理、指令遵循等对齐关键领域,发现三个要素对偏好数据的质量都会产生关键影响,设计合理的优化策略能够显著提升累积对齐性能。
这意味着我们将偏好数据集的设计转变为一种更加科学、关注组件优化的策略。这种方法不仅显著提升了对齐性能,还为未来的对齐研究提供了一张高效的蓝图。
同时,AIR 技术已赋能阿里安全御风大模型的业务偏好优化,提升了模型 zeroshot 解决业务问题的能力,促进阿里广泛多域安全审核业务的模型上线。
【TL;DR】AIR 框架提出大模型偏好数据集的三大设计准则
极简标注策略:利用生成式奖励模型(如 Llama-3.1-70B-Instruct)的文本生成能力完成偏好标注,仅需基础的 point-wise 评分指令(如「请从 0-9 分评估回复质量」)配合贪心解码。实验证明复杂标注设计会产生过度干预,反而不利于模型学习偏好信号。
智能指令筛选:基于动态质量方差分析的指令优选机制,通过多模型采样后保留回复分数方差最小的指令。值得注意的是,虽然多轮对话指令能增强对话连贯性,但因在其他评估维度未现显著增益,最终采用非筛选的指令轮数方案。
科学回复对构造:通过三重黄金准则实现高效对比学习:① 设置合理质量差(Δ=2/3)构建清晰对比梯度;② 锚定高质量基线(评分≥8)确保回复可靠性;③ 采用 On/Off-Policy 混合策略(1:1 配比)精准控制策略分布偏移。

论文标题:AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
论文链接:https://arxiv.org/abs/2504.03612
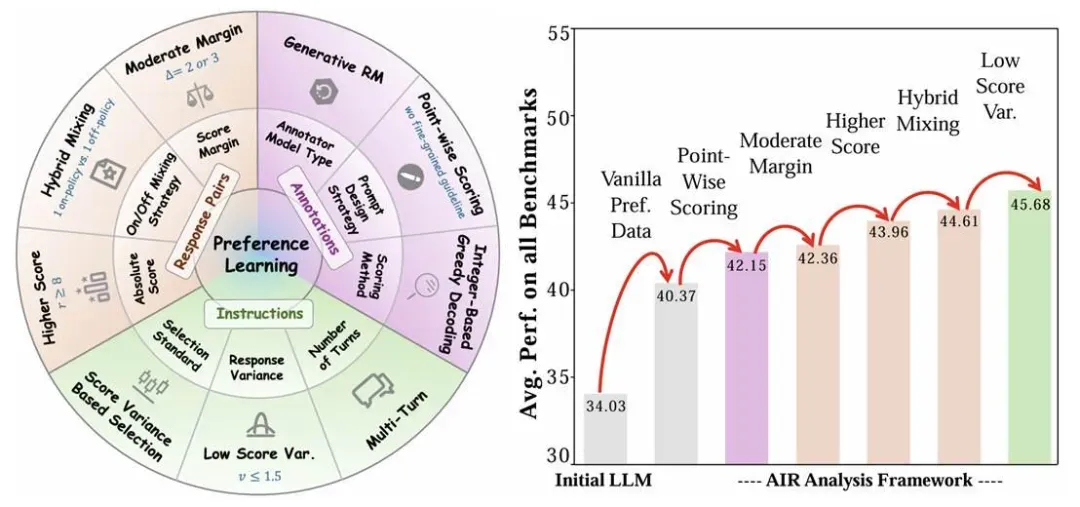
图 1:(左)AIR 框架将偏好学习拆解为这三个核心部分,并在最外层标注了经过实证验证的最佳设计原则。(右)当我们逐步整合这些优化后的标注、响应组合和指令时,在 14k 偏好数据对上的累积效果非常显著,明显提升了所有基准测试中的对齐性能。
我们在一个被广泛使用的开源 SFT 模型(Llama-3.1-Tulu-3-8B-SFT)基础上,结合 ShareGPT 与 UltraFeedback 指令集,基于最简单的 DPO 设置,系统性探索了偏好数据集的三大核心组件——标注(A)、指令(I)、回复对(R),提出可扩展的组件化优化框架 AIR,并在 MT-Bench、ArenaHard、AlpacaEval 2.0 等 6 大评测集做了大规模、系统性的评测。
同时为了确保实验结论可信,我们在不同的指令集、不同的标注模型上做了验证实验。我们总结出如下三大设计原则:
偏好标注:大道至简,避免复杂标注策略
我们从标注模型架构、标注 Prompt 设计和解码方式三个方面,分析了如何对偏好进行有效标注。
标注模型架构:我们分别用 SOTA 的分类式的奖励模型(Skywork-Reward-Gemma-2-27B-v0.2; RewardBench: 94.3)和普通的生成式模型(Llama-3.1-70B-Instruct; RewardBench: 84.0)标注偏好数据集,然后评测它们用于对齐的性能。我们发现尽管在 RewardBench 上得分较低,Llama-3.1-70B-Instruct 在所有 Benchmark 上的平均分比基于分类器的模型高 1.4(图 2 左),这表明分类式奖励模型可能过拟合了 RewardBench,而 RewardBench 同样低估了生成式模型用于偏好标注的泛化能力。
标注 Prompt 设计:对于用生成式模型标注偏好,我们由简单到复杂设计了六种标注策略。从最简单的单点打分(Single)开始,变成成对打分(Pair),加入评分手册(Guided),让模型先给出解释再打分(Explained),提出多个细粒度问题再打分(Fine-Grained)。我们惊讶地发现最简单的单点打分策略性能最佳(表 1)。这可能表明,在追求复杂标注流程时,过多的人类要求引入了噪音,而使用简约的标注 Prompt 并利用标注模型的固有判断力,比使用复杂的标注 Prompt 更契合真实世界的偏好信号,这和 DeepSeek-R1-Zero 在 Zero-RL 过程中使用的简约 prompt 有着异曲同工之妙。
标注解码方式:近期的研究中出现了多种聚合解码方法,用以提高标注的可靠性。如多样本平均(计算多次高热采样的平均得分)和基于概率的加权(对输出「0」到「9」的概率进行加权)。我们将这两种方法与贪心解码方法进行了比较,如图 2(右)所示,贪心解码性能最佳。尽管它最简单,但其平均得分比多样本平均高出 1.9,比基于概率的加权高出 1.4。

图 2:(左)生成式标注性能超越 SOTA 分类器模型(+1.4),揭示 RewardBench 评估盲区;(右)Greedy Decoding 效果优于多次打分平均(+1.9)与概率加权(+1.4)

表 1:单点打分策略(Single-Basic)比复杂两两对比方案性能提升 +3.12
指令筛选:偏好数据需要能够引发细粒度差异的指令
当前指令筛选方法主要关注指令本身的静态属性(如质量、难度、多样性),却忽视了动态的响应一致性问题——同一指令在不同大语言模型中可能引发差异显著的回复。这种响应分歧会模糊偏好学习的信号边界,降低对齐效率。
因此,我们探究了更高的指令推理稳定性(即指令能够引发不同 LLMs 回复之间更细粒度的差异)能否为模型对齐提供更有效的信号。
为了验证这一点,我们提出了基于回复质量方差的指令选择方法,首先从不同的 LLMs 中采样回复,然后标注他们的得分并计算方差,最后优先选择方差较低的指令。结果如图 3(左)所示,仅仅筛选质量较高的指令(InsTag Quality Filtering)并没有显著收益,而筛选低方差的指令取得了最佳性能,在 AlpacaEval 2(+3.7)和 ArenaHard(+4.6)上表现出色。这可能由于低方差的指令迫使模型学习细粒度偏好差异(如逻辑严谨性),而不会依赖于回答对之间明显的差别,或简单地对错误进行修正。
我们还将指令筛选的分析扩展到了指令的结构——具体来说,提高对话的轮数能否改善偏好学习的性能。为了验证这一点,我们将单轮和多轮指令分开,并以与之前相同的方式构建偏好对。结果如图 3(右)所示,多轮上下文指令在 MT-Bench 第二轮中产生了提升(+0.7),但在其他单轮测试中改进较小。这表明多轮指令增强了多轮对话的能力,但它的价值取决于未来的评测集是否会优先衡量对话深度而不是单轮任务。

图 3:(左)低方差指令表现最佳,在推理任务(ArenaHard,+4.6)和指令遵循(AlpacaEval 2,+3.7)上表现突出;(右)含有多轮上下文的指令在涉及多轮对话能力的评测集(如 MT-Bench Turn 2,+0.7)上效果较好,但在其他评测集上提升不明显
回复对构造:信号清晰性、回复质量和策略多样性的平衡
回复对的构造必须平衡三个相互竞争的目标:(1)信号清晰性(正负样本之间的对比应该明确无误)(2)回复质量(回复应该都具有足够的质量以避免无效比较)(3)策略对齐(混合 On-Policy 和 Off-Policy 回复以控制偏好学习时的分布偏移)。
信号清晰性:在 10 分制下,我们构建了具有低(Δ=1)、中等(Δ=2 或 3)和高(Δ≥4)分数差距的回复对,并平衡了各组之间的数据集规模。如图 4(左)所示,中等差距在所有评测集的性能上实现了更高的平均性能(+1.29/+5.42)。这是因为正负样本之间适度的差距提供了清晰的偏好信号,又不会过度简化学习目标,从而避免了噪声(低Δ)或过拟合(高Δ)。
回复质量:如图 4(中)所示,在控制各组分数差距的分布一致的前提下,高分回复对(正样本分数≥8)在所有基准测试中都取得了最显著的性能,总体上比低分回复对(正样本分数<7)高出 +9.35。这表明,高分回复对提供了更清晰的学习信号,因为两个回复都是合格的且可区分的。而低分回复对存在放大低质回复噪声的风险。
策略对齐:一系列研究验证了在偏好学习中,使用 On-Policy 样本的有效性,但是在 DPO 训练中如何最好地混合 On-policy 和 Off-policy 的样本仍然不确定。因此我们研究了不同混合策略的影响。我们比较了 4 种基于混合 On-Policy 样本比例的混合策略。实验结果如图 4(右)所示,中等混合(所有回复对都包含一个 On-Policy 和一个 Off-Policy 的回复)取得了最佳的性能。这表明,将 On-Policy 和 Off-Policy 回复适度混合,既能保证避免对静态数据集的过拟合,又保持了偏好学习过程中策略的更新不会偏移。

图 4:中等分数差(左)、较高绝对分(中)、On/Off-Policy 1:1 混合(右)的偏好对效果最好
各组件之间协同带来的综合影响
为了量化我们发现的所有有效组件之间的协同效应,我们将各个组件逐步整合到偏好数据集中,并观察偏好学习性能的逐步提升。
如图 1(右)所示,当我们逐步整合这些优化后的标注、回复组合和指令时,稳步带来了 +5.3 的平均性能提升。更改为单点打分策略和使用更高的绝对回复质量分数显示出了显著的改进(+1.78,+1.6)。
由于最先进模型训练使用的偏好数据集大小远大于我们这里使用的 14k 偏好数据,因此可以预见将 AIR 框架下全部组件组合起来的 scaling law 将在更大的偏好数据集规模下继续扩大。
结语
AIR 框架的提出,为偏好学习的科学化和系统化进程提供了一种新的思路与方法。通过解构标注、指令和回复对三大核心要素,我们揭示了对齐性能提升的关键路径。
这一创新标志着偏好学习从盲目追求数据量到注重数据质量和设计原则的飞跃,为构建构建高质量的偏好数据集、更智能更可靠的 AI 系统奠定了坚实基础。


