
现有的检索增强型语言模型(Retrieval-Augmented Language Models, RALMs)在处理外部知识时存在一定的局限性。这些模型有时会因为检索到不相关或不可靠的信息而产生误导性的回答,或者在面对检索信息和模型内在知识的干扰时,无法正确选择使用哪一种知识。此外,在检索信息不足或完全不存在的情况下,标准的RALMs可能会尝试生成一个答案,即使它们并不具备足够的信息来准确作答。因此,来自Tecent AI Lab的一篇工作,提出CHAIN-OF-NOTE(CON),旨在通过生成一系列阅读笔记来增强RALMs的鲁棒性。
1、方法介绍
CHAIN-OF-NOTE的核心思想是通过创建顺序阅读笔记来对每个检索文档进行评估。这种方法不仅评估了每个文档与查询的相关性,还确定了这些文档中最关键和可靠的信息。这个过程有助于过滤掉不相关或可信度较低的内容,从而导致更准确和上下文相关的响应。
给定一个输入问题x和k个检索到的文档 ,模型的目标是生成包含多个段落的文本输出
,模型的目标是生成包含多个段落的文本输出 。其中,
。其中, 表示第i个段落的标记,代表相应文档
表示第i个段落的标记,代表相应文档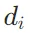 的阅读笔记,如图2所示。在生成各个阅读笔记后,模型综合这些信息以生成最终的响应y。Chain-of-Note (CoN)的实现包括三个关键步骤:(1) 设计笔记
的阅读笔记,如图2所示。在生成各个阅读笔记后,模型综合这些信息以生成最终的响应y。Chain-of-Note (CoN)的实现包括三个关键步骤:(1) 设计笔记 ,(2) 收集数据,(3) 训练模型。
,(2) 收集数据,(3) 训练模型。

笔记设计
CON 主要构建三种类型的阅读笔记,基于检索文档与输入问题的相关性:
- 直接回答型笔记:当一个文档直接回答了查询时,模型基于此相关信息制定最终响应。(图2a)
- 间接推断型笔记:如果检索文档没有直接回答查询但提供了有用的上下文,模型利用这些信息及其内在知识推断答案。(图2b)
- 未知型笔记:在检索文档无关且模型缺乏足够知识的情况下,默认回复“未知”。(图2c)
这种细致的方法模拟了人类信息处理的方式,在直接检索、推理以及承认知识空白之间取得平衡。
数据收集
为了使模型能够生成这样的阅读笔记,需要收集适当的训练数据。由于手动注释资源密集,研究团队使用 GPT-4 来生成笔记数据。具体步骤如下:
- 问题选取:首先从 NQ 数据集随机抽取 10000 个问题。
- 笔记生成:然后用特定指令和情境例子提示 GPT-4 生成不同类型的笔记,确保覆盖所有三种类型。

- 质量评估:对小部分生成的数据进行人工评估以保证质量。
模型训练
使用这些数据训练LLaMa2 7B模型,将指令、问题和文档连接起来作为提示,模型学习顺序生成每个文档的阅读笔记,以评估它们与输入查询的相关性,并基于文档的相关性生成回答。
另外,为了减少CON推理成本,使用了一种称为混合训练的策略,将50%的训练时间分配给标准RALM(直接生成答案,不使用笔记),另外50%分配给使用CON的RALM。这种策略允许模型在训练期间内化中间推理步骤。
在推理阶段仅使用标准 RALM 提示来指导模型输出答案,而不依赖显式的阅读笔记。这使得模型可以在保持相同推理速度的同时,只略微降低性能。
2、实验结果
数据集
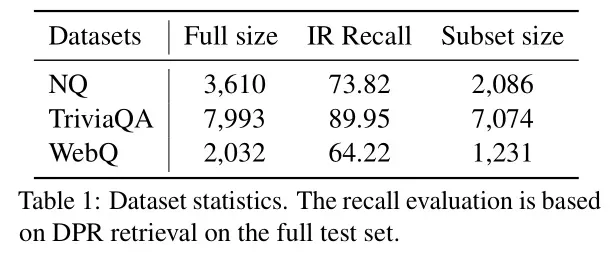
为了全面评估 Chain-of-Note 的性能,除NQ外,还在三个额外的开放域数据集上测试了其性能,包括TriviaQA、WebQ和RealTimeQA,展示了其对域外(OOD)数据的泛化能力。
- NQ (Natural Questions):一个大型的问答数据集,包含来自搜索引擎的真实用户查询。
- TriviaQA:一个涵盖多个领域的事实性问题数据集。
- WebQ:一个基于网络的问题回答数据集,主要涉及简单的事实性问题。
- Real-TimeQA:作为特殊情况用于评估“未知”稳健性,该数据集包括了2023年5月之后收集的问题,这些问题超出了 LLaMa-2 的预训练知识范围。
为了全面评估模型性能,实验分为两个部分:
- 全集评估:使用测试集中的所有问题来评估整体 QA 性能。文档通过 DPR(Dense Passage Retrieval)检索,并将 top-k 文档输入生成器。
- 子集评估:为了评估模型的噪声稳健性和未知稳健性,从上述测试集中提取包含相关文档的子集。根据噪音比率 r 确定相关和无关文档的数量。例如,当噪音比率是 20% 且需要 top-5 文档时,则 4 个为相关文档,1 个为无关文档。
整体 QA 性能评估
表2展示了不同模型在 NQ、TriviaQA 和 WebQ 上的整体表现。实验结果表明,装备CON的RALM在所有三个数据集上的平均EM分数提高了1.97%。
当DPR检索到相关文档时,平均改进为+1.2,当DPR未检索到相关文档时,NQ数据集的平均改进为+2.3。这一差异表明,CoN在检索阶段获取更多噪声文档的情况下提高了RALM的性能。

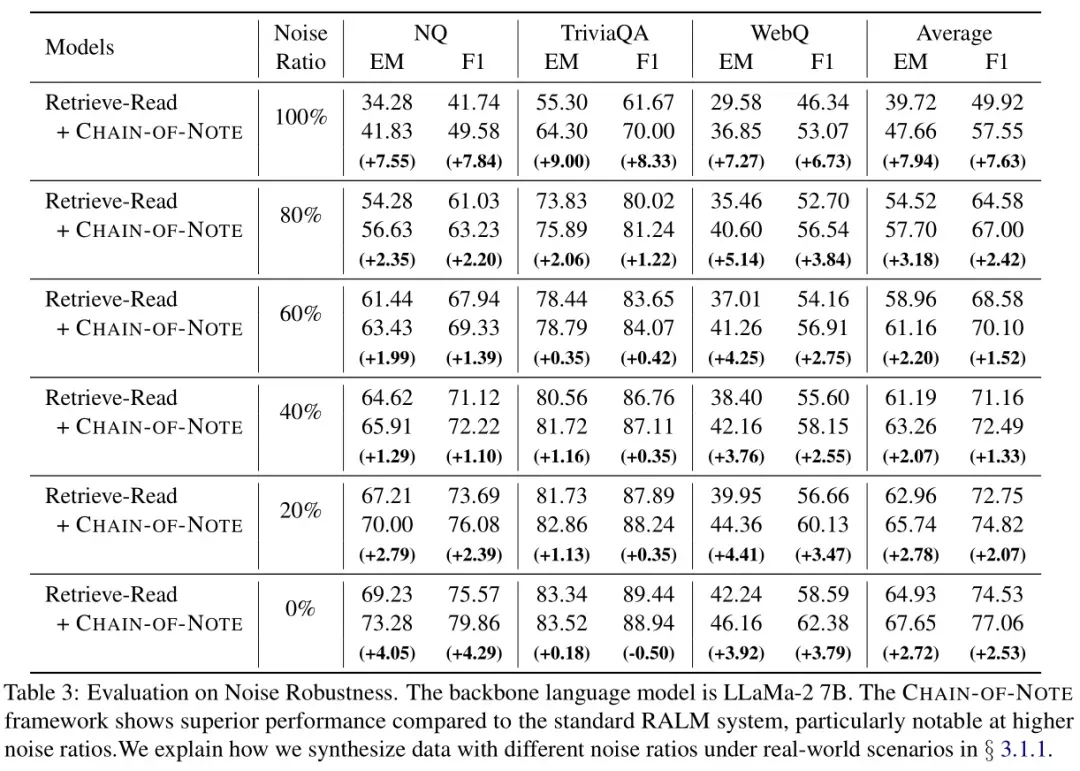
噪声稳健性评估
实验结果显示,CON 方法在引入噪声文档后仍能保持较好的性能。在不同噪声比例下,CON始终优于标准RALM,尤其是在完全噪声文档的情况下。表明 CON 可以有效过滤无关信息,提高模型对噪声数据的容忍度。
未知稳健性评估
针对 Real-TimeQA 数据集的评估表明,CON 方法在面对超出预训练知识范围的问题时具有更好的“未知”稳健性。具体表现为更高的拒绝率(RR),这意味着模型更倾向于承认自己的知识局限,而不是尝试猜测答案。这一特性对于实际应用尤为重要,因为它减少了误导性响应的风险。

混合训练策略的效果
最后,混合训练策略的效果也得到了验证。实验表明,经过混合训练的模型能够在保持与纯 CON 方法相似性能的同时,实现与标准 RALM 相同的推理时间。这意味着混合训练不仅有效地降低了推理成本,还保留了 CON 在处理复杂查询方面的优势。

3、总结
Chain-of-Note 技术通过构建详细的阅读笔记数据集,模拟人类的思考总结过程,增强了模型的推理能力。它在提高模型对噪声数据的容忍度、增强未知稳健性以及保持推理效率等方面表现出色,为检索增强型语言模型的发展提供了新的思路和方法。然而,需要注意的是,微调可能会改变模型的参数分布,对于模型的通用能力的影响还有待进一步评估。
未来的研究可以关注如何更好地平衡模型的推理能力和通用能力,以及如何进一步优化 Chain-of-Note 技术,使其在更多领域和应用场景中发挥更大的作用。


