
大语言模型(LMs)在许多自然语言处理任务上表现优异,但它们在记忆和回忆不太常见或不流行的事实知识方面存在明显的局限性。并且,当涉及到长尾实体(即那些在网络上讨论较少、出现频率较低的实体)的问题时,LMs 的性能显著下降,并且增加模型规模并不能有效地解决这一问题。
此外,LMs 对于自身知识边界的认识有限,有时会产生幻觉,即生成看似合理但实际上错误的信息。这种不确定性以及对模型输出的信任问题,在实际应用中部署 LMs 时显得尤为重要。
因此,何时应该依赖LMs的参数知识(即存储在其参数中的知识)?何时不应该信任其输出?以及如何通过非参数记忆(例如检索增强技术)来弥补参数记忆的不足?来自艾伦人工智能研究院发表在2023年ACL的一篇论文《When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories》深入探究了这些问题,并提出了极具启发性的解决方案。

1、大模型的“记忆困境”:何时不该信任它们?
为了评估LMs在记忆事实知识的能力,通过闭卷问答(QA)任务来评估,并使用少量样本进行测试。简单来看下作者的评估思路:
研究重点和任务
研究重点:事实知识。这项工作关注于实体的具体细节知识,将事实知识定义为一个三元组(主体、关系、对象)。如图2左图
任务格式:开放域问答(QA)。将任务构建为开放域QA,即给定一个问题,模型需要在没有任何预给定段落的情况下预测答案。
评估指标:准确率。如果预测的任何子串与任何金标准答案完全匹配,则将预测标记为正确。
分析维度
作者们假设在Web上讨论较少的事实知识可能不会被LMs很好地记忆。先前的研究通常使用预训练语料库中对象实体的词频来理解记忆能力。相反,本文通过研究是否可以根据输入问题中的信息预测记忆,并据此改进模型。因此,本文工作集中在事实知识三元组中的另外两个变量:主体实体和关系类型。
主体实体流行度:使用Wikipedia月度页面浏览量作为实体流行度的衡量标准,以此来代理实体在网络上被讨论的频率。
关系类型:也考虑了关系类型作为事实知识记忆的关键因素。
基准数据集
PopQA:现有的常见开放领域 QA 数据集(如Natural Questions,NQ)通常由高流行度的主体实体主导,并且由于问题表面形式的多样性,通常很难识别关系类型。为了能够基于上述分析维度对记忆能力进行细粒度分析,构建了一个新的大规模实体中心开放域QA数据集,包含14k个问题,覆盖了可能在流行QA数据集中被遗漏的长尾实体的事实信息。
PopQA构建流程如下:使用了维基百科页面的浏览量作为衡量实体受欢迎程度的标准,从 Wikidata 中随机抽取了 16 种不同关系类型的知识三元组,并使用自然语言模板将其转换为自然语言问题。
问题的可接受答案集是满足知识图谱中存在(S,R,E) 的实体集E。

EntityQuestions:这是另一个广泛使用的开放领域问答数据集,它也具有长尾分布的特点,即大部分问题是关于不太流行的实体。

EntityQuestions:另一个流行的开放域QA数据集,也涵盖了长尾实体分布。
结果
整体模型性能:图 4 的左上角展示了模型在 PopQA 上的整体表现,结果显示,即使没有使用上下文示例,较大的LMs也能展现出合理的性能。
主体实体流行度预测记忆:图 4(底部)显示,几乎所有关系类型的主体实体流行度与模型准确率之间都存在正相关关系。总体而言,主体实体流行度与准确率之间的相关性在较大的 LMs 中更强;GPT-3 003 显示出最高的正相关性(约为 0.4),而 GPT-Neo-1.3B 的相关性相对较弱(约为 0.1)。
关系类型影响记忆:在图 4 中可以看到,模型对某些关系类型的平均性能高于其他类型。这表明某些关系类型的事实知识比其他类型更容易记忆。同时,对于某些关系类型的问题,模型可能不需要记忆知识三元组就能通过利用表面线索来猜测答案。例如,某些关系类型(如国籍)允许模型利用主体实体名称中的表面线索。此外,模型通常对答案实体数量较少的问题输出最主导的答案实体(例如,对于颜色关系类型的问题,答案是“红色”)。
扩展可能不会帮助尾部知识:如图 4 左侧所示,随着模型规模的扩大,PopQA 数据集上的整体表现有所提升。然而,图 5 显示,在 PopQA 和 EntityQuestions 上,模型规模的增加对于流行度较低的问题的性能改善相对较小。


关系类型结果分解:图 6 更详细地展示了流行度、准确率和关系类型之间的关系,显示了不同模型在导演和国家关系类型上的准确性与流行度分布。对于前两种类型,可以看到流行度与准确性之间存在明显的正趋势,并且随着模型规模的增大,LMs记忆的知识也更多。另一方面,在“国家”关系类型中,没有模型显示出趋势,而整体准确性较高,表明LMs经常利用线索来回答不太流行的问题。

2、检索增强:为大模型“补课”
前面分析表明,即使是当前最先进的 LMs 在处理不太受欢迎的主体或某些关系类型时也存在困难,并且增加模型规模并不会带来进一步的性能提升。因此下面探索研究了检索增强 LMs的有效性,这些模型利用非参数记忆(即检索到的文本)来提高性能。
实验设置:采用了简单直接的方式将检索到的上下文与原始问题连接起来。从维基百科中获取相关段落来作为附加的上下文信息,使用BM25和神经密集检索器作为检索模型。BM25是一种基于统计信息检索的算法,而神经密集检索器则利用深度学习技术来计算文档与查询之间的相似度。
结果
图7显示,检索显著提升了性能,一个较小的 LM(例如,GPT-Neo 2.7B)通过 Contriever 检索增强后,表现优于普通的 GPT-3。

对不流行实体的帮助
对于主体实体不太受欢迎的问题,非参数记忆显著提升了所有测试模型的表现。例如,在PopQA数据集中最不受欢迎的4000个问题上,基于神经密集检索器增强的GPT-neo 2.7B模型甚至超过了强大的GPT-3 davinci-003模型。

对流行实体可能造成的误导
然而,对于关于流行实体的问题,检索增强可能会导致大型LMs表现下降。这是因为检索到的上下文有时会误导这些已经能够很好地记住相关信息的模型。对于 10% 的问题,检索增强导致 LM 错误地回答了它本可以正确回答的问题。

3、Adaptive Retrieval:自适应检索
虽然引入非参数记忆有助于处理长尾分布,但强大的 LMs 已经记忆了流行实体的事实知识,检索增强可能会带来负面影响。于是本文探索了一种两全其美的方法,即自适应检索(Adaptive Retrieval),该方法仅根据输入查询信息决定何时检索段落,并在必要时使用检索到的非参数记忆增强输入。
自适应检索基于这样的发现:当前最佳的LMs已经记忆了更受欢迎的知识,因此只有在它们没有记忆事实知识并且需要找到外部非参数知识时才使用检索。
使用PopQA 数据集来选择一个基于输入查询信息的流行度阈值,并且仅在低于该阈值的情况下才进行检索。对于更受欢迎的实体,则不使用检索。阈值是独立为每种关系类型确定的。
流行度阈值确定
采用暴力搜索(Brute Force Search)的方法来选择阈值。具体步骤如下:
1. 定义自适应准确率:自适应准确率是指在给定的流行度阈值下,模型的综合表现。具体来说:
- 对于流行度低于阈值的问题,模型使用检索增强(非参数记忆)的结果。
- 对于流行度高于或等于阈值的问题,模型使用自身的参数记忆(即不进行检索)的结果。
2. 搜索最优阈值:通过暴力搜索的方式,尝试不同的流行度阈值,并计算每个阈值下的自适应准确率。最终选择使自适应准确率达到最高的那个阈值。
性能提升结果
图9显示了基于每种关系类型的阈值自适应检索非参数记忆的结果。可以看出,对于较大的模型,自适应检索非参数记忆是有效的。在POPQA上的最佳性能是使用GPT-3 davinci-003自适应地与GenRead和Contriever结合,准确率达到了46.5%,比任何非自适应方法高出5.3%。

阈值随模型规模变化
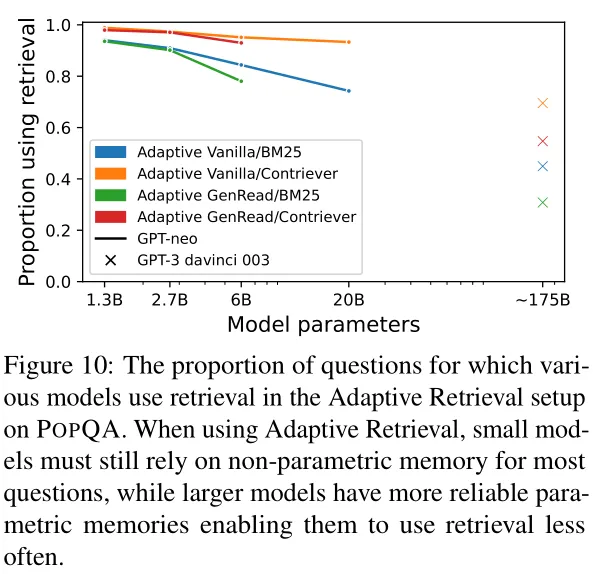
尽管自适应检索对较大模型显示出性能提升,但较小模型并没有实现相同的性能提升。图10显示,较小的LMs几乎总是需要检索,表明对于小LMs,参数记忆并不比非参数记忆更可靠。相比之下,大型模型通常检索得少得多。例如,GPT-3 davinci-003仅对40%的问题进行检索,而较小的GPT-NeoX 20B也不在超过20%的问题上检索文档。
推理成本降低
自适应检索还提高了效率;如果我们知道不需要检索文档,我们可以跳过检索组件,并且输入长度变得更短,这在检索和语言模型组件中都提高了延迟。图11显示了GPT-J 6B和GPT-NeoX 20B的推理延迟,以及GPT-3的API成本。特别是对于较大的LMs,连接检索上下文会导致显著增加的延迟(例如,对于GPT-J 6B,推理时间延迟几乎翻倍)。自适应检索能够将推理时间降低高达9%,从标准检索中节省成本。图12显示了EntityQuestions的准确率和成本节省。尽管EntityQuestions缺乏流行实体,但自适应检索能够减少API成本15%,同时保持与仅检索相当的性能。

4、总结
这篇论文深入探讨了在什么情况下为大型语言模型(LLM)应用检索增强生成技术会更有效果。并提供了一种有效的解决方案,帮助我们更合理地应用检索增强技术,让语言模型在更多场景下发挥出更好的性能。
但是对于自适应的方式,采用暴力搜索的方式选取自适应阈值,尤其是在效率和可扩展性方面存在明显的局限性。这种基于暴力搜索的策略需要对大量可能的阈值进行遍历,计算成本较高,且难以适应动态变化的数据分布或大规模应用场景。因此,探索更高效、更智能的阈值选择方法值得研究。


