
编辑 | 萝卜皮
为了应对生物医学研究中科学出版物和数据的快速增长,知识图谱(KG)已成为整合大量异构数据以实现高效信息检索和自动知识发现的重要工具。
然而,将非结构化的科学文献转化为知识图谱仍然是一项艰巨的挑战,之前的方法无法达到人类水平的准确率。
在最新的研究中,佛罗里达州立大学(Florida State University)和 Insilicom LLC 的研究人员使用了在 LitCoin 自然语言处理挑战赛 (2022) 中获得第一名的信息提取流程,利用所有 PubMed 摘要构建了一个名为 iKraph 的大规模知识图谱。提取的信息与人类专家注释相匹配,并且大大超出了手动整理的公共数据库的内容。
为了增强知识图谱的全面性,团队整合了来自 40 个公共数据库的关系数据和从高通量基因组学数据推断出的关系信息。该知识图谱有助于对自动化知识发现进行严格的性能评估。
该研究以「A comprehensive large-scale biomedical knowledge graph for AI-powered data-driven biomedical research」为题,于 2025 年 3 月17 日发布在《Nature Machine Intelligence》。

每天,科学文献中都会产生大量以自然语言表达的信息,因此,即使是在相对狭窄的研究领域中,手动阅读所有出版物也是不切实际的。
此外,高通量技术的进步也导致了大量研究数据的产生,其中许多数据在各种数据库中仍未得到充分利用。这种信息爆炸对研究人员利用所有可用数据来识别和开发创新想法提出了重大挑战。
并且,将非结构化的科学文献转换为结构化数据一直是 NLP 领域的长期挑战。成功解决这一问题可能会彻底改变科学发现的速度。尽管多年来已经进行了大量研究,但计算方法在提取方面尚未达到手动注释的精度,这是一个重大障碍。
迄今为止最全面生物医学 KG
近年来 LLM 的出现通过 LLM 微调带来了信息提取方面的显著进步。佛罗里达州立大学和 Insilicom LLC 的研究团队将为 LitCoin NLP 挑战赛开发的信息检索流程应用于所有 PubMed 摘要(截止日期为 2023 年 5 月)来构建大规模生物医学 KG。
通过进一步整合从 1997 年起 40 个公共数据库的关系数据和从公开可用的基因组数据分析而来的数据,最终形成的 KG(称为 iKraph,Insilicom 知识图谱的缩写)脱颖而出,成为迄今为止构建的最全面的生物医学 KG。

图示:iKraph 的覆盖范围和一些基本属性。(来源:论文)
手动验证证实了该流程拥有人工注释者级别的准确性。通过注释 LitCoin 数据集中的关系方向并训练模型来预测关系的方向,研究人员还构建了一个能够进行间接因果推断的因果 KG。iKraph 的覆盖范围比研究人员提取的关系的公共数据库大得多。
为了在知识图谱中不直接相连的实体之间进行因果推理,研究人员设计了一种基于概率的方法,即概率语义推理 (PSR)。PSR 具有高度可解释性,因为它通过直接的推理原理直接使用直接关系推断间接关系。驾驭现代药物开发领域错综复杂,资源密集。成本上升很大程度上源于先前的研究耗尽了更直接的药物靶标,因此需要转向更复杂的靶标。在这种情况下,知识图谱在 AKD 中发挥着关键作用,特别是在药物靶标识别和药物再利用领域。
开发此类应用方法的一大挑战是全面评估这些研究的有效性。例如,在药物再利用的情况下,收集特定疾病或药物的所有已知治疗关联需要彻底搜索文献。没有这样的知识,就不可能严格评估药物再利用方法。
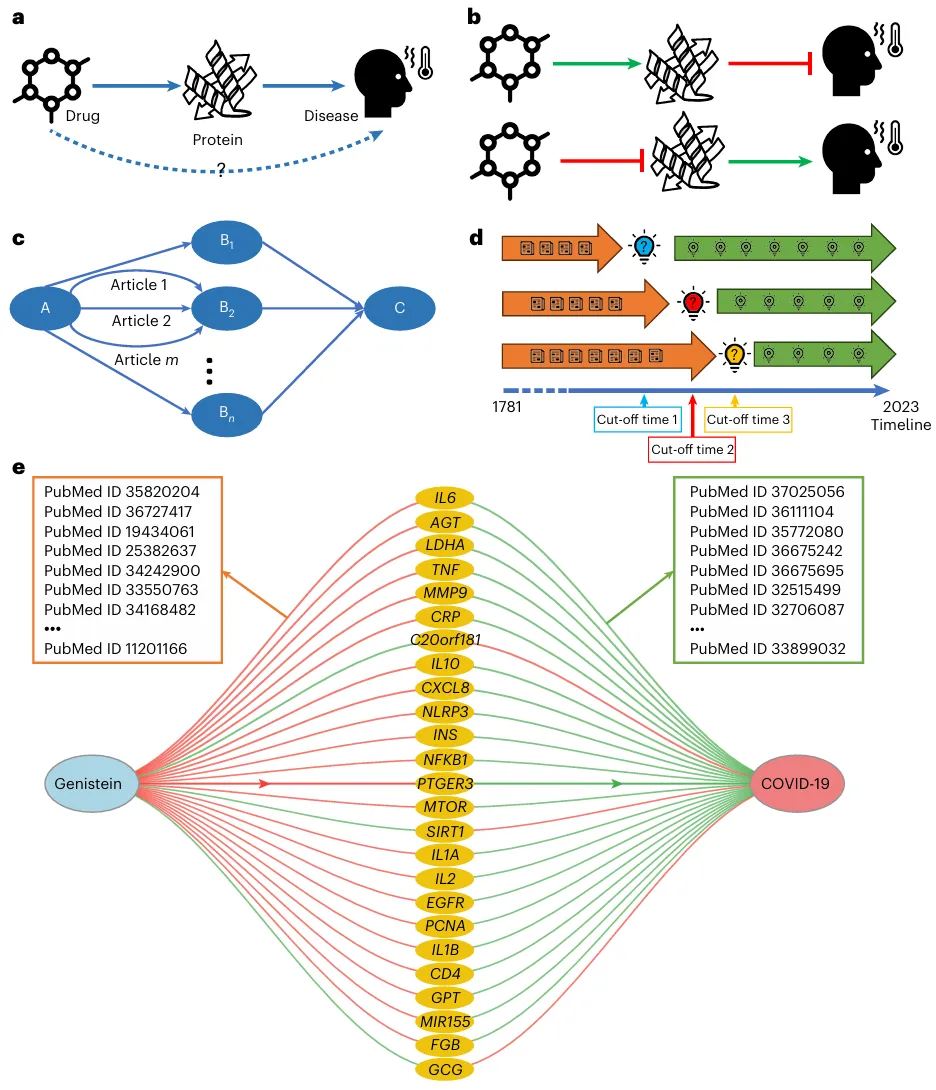
图示:提出的药物再利用策略和验证方法概述。(来源:论文)
在实验中,对于每个再利用目标,研究人员提取了 PubMed 摘要中记录的所有治疗关联。这使他们能够测量召回率和观察阳性率 (OPR),这在以前的药物再利用研究中是不可行的。
该团队通过开展几项药物再利用研究证明了该方法的强大功能:针对 COVID-19、囊性纤维化以及十种没有令人满意的治疗的疾病和十种常用处方药的药物再利用。

图示:药物再利用治疗 COVID-19。(来源:论文)
对于 COVID-19 和囊性纤维化,团队进行了回顾性的实时药物再利用测试。该方法确定了许多可行的候选药物,并得到了将药物和疾病实体联系起来的大量文献证据的支持。在确定后续研究工作的必要性时,这种可解释性水平是无价的。

图示:针对囊性纤维化的药物再利用。(来源:论文)
讨论
生物医学研究界传统上通过手动注释在知识管理方面投入了大量的资源和人力。该研究表明,利用现代 LLM 的功能可以实现范式转变。通过最初生成一组有限的高质量标记数据,可以训练一个信息提取模型,该模型可以在更大的文本数据集上以人类水平的精度运行。这种方法可以显著扩大公共数据库的覆盖范围,而不会影响数据质量。
研究人员将该研究置于当前 NLP 研究界流行的 LLM 背景下。虽然 LLM 在理解和生成自然语言方面表现出色,但它们并非没有缺点。一个明显的限制是它们的知识截止日期是固定的,这限制了它们对最新发展的了解。在精确度至关重要的生物医学研究中,由于 LLM 的知识库有限,仅依靠 LLM 来回答特定问题可能会出现不准确的风险。
另外,LLM 倾向于生成文本,虽然表达令人信服,但可能缺乏事实准确性。这种倾向引发了人们对 LLM 生成的答案的真实性的担忧,需要验证机制和产生更有根据的结果,可能还需要适当的引用。
不过研究人员表示,他们相信将 iKraph 等 KG 与 LLM 集成可以有效缓解这些限制。为此,他们正在积极开发一个综合问答系统,将 iKraph 与开源 LLM 相结合。总之,iKraph 是更有效、更高效的信息检索和 AKD 的强大推动者。
该团队还开发了一个云平台,供学术用户访问这些结构化数据和相关工具。
平台链接:https://biokde.insilicom.com
论文链接:https://www.nature.com/articles/s42256-025-01014-w


