最近几天,开源大模型是异常活跃。
从前几天有爆料deepseek-r2即将发布的消息:
 图片
图片
到昨天Qwen3短暂发布又撤回:
 图片
图片
再到今天Qwen3正式发布。
感觉就像一场军备竞赛,阿里这次终于抢在了deepseek-r2发布之前发布了Qwen3!接下来的压力给到了DeepSeek,毕竟万一后发者在各方面没能超越对方的话,这一版本的努力影响力就要小很多了。
言归正传,一起看看这次阿里发布的最新开源大模型:Qwen3 的超强表现
Qwen3 概览
 图片
图片
Qwen3是阿里推出的Qwen系列最新一代大型语言模型,是国内首个“混合推理模型”。“混合推理”相当于把顶尖的推理模型和非推理模型集成到同一个模型里去,需要极其精细、创新的设计及训练。目前除了Qwen3之外,只有Claude3.7和Gemini 2.5 Flash可以做到。
性能炸裂
Qwen3旗舰模型Qwen3-235B-A22B在编码、数学、通用能力等基准评估中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,表现出色。
 图片
图片
此外,小型MoE模型Qwen3-30B-A3B以10倍激活参数超越QwQ-32B,甚至像Qwen3-4B这样的微型模型也能媲美千问2.5-72B-Instruct的性能。
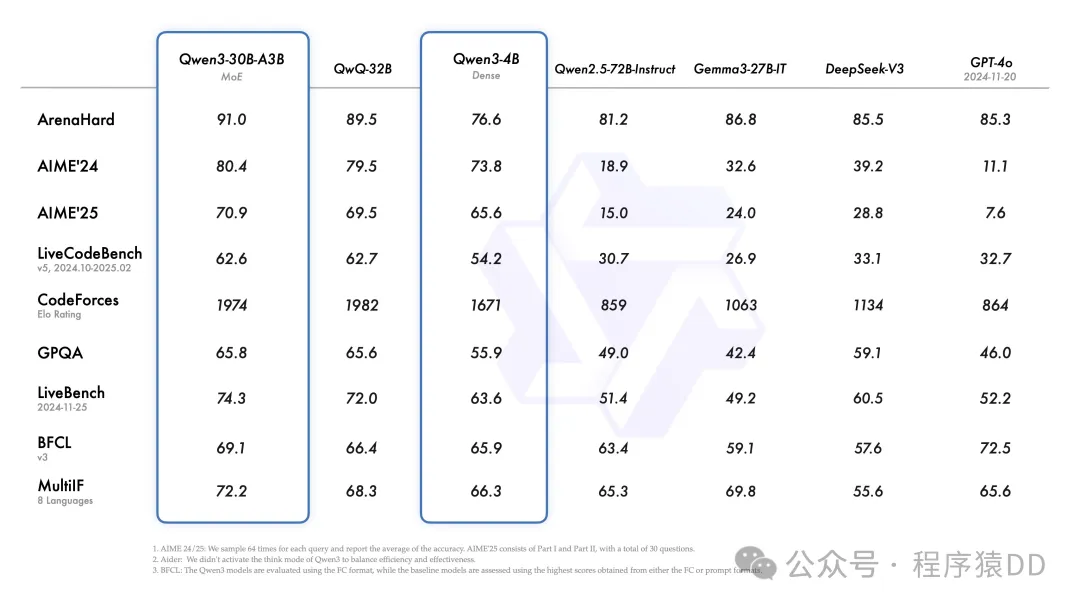 图片
图片
关键能力
• 单一模型内无缝切换思维模式:思考模式(适用于复杂逻辑推理、数学和编码)和非思考模式(适用于高效的通用对话),确保在各种场景下实现最佳性能。
• 多语言支持:覆盖119种语言和方言,具备强大的多语言指令遵循和翻译能力。
• 代理能力增强:支持MCP协议和自定义工具集成,强化了在思考和非思考模式下与外部工具的写作能力
• 极致成本控制:满血版仅需4张H20即可部署
• 上下文长度支持扩展至128K
快速上手
目前 Qwen3 已上架 ollama 和openrouter ,大家可以快速接入体验:
 ollama
ollama
 openrouter
openrouter
最后,对于即将发布的deepseek-r2,您觉得能否超越Qwen3呢?


