
上篇文章中,给大家分享了一个使用 Dify+RAGFlow 实现的泵类设备的预测性维护案例,过去两天里有很多盆友在后台私信我了一些实现细节,比如:HTTP 请求的数据存在哪里? IoT 平台的数据能否直接实时“流”入 Dify?以及如何使用 MCP 的方案实现四个数据源(IoT, CMMS, MES, ERP)的智能查询。
Dify+RAGFlow:泵类设备预测维护系统案例分享
前两问的回答昨 晚我已经写在了知识星球内,感兴趣的移步去翻下。这篇文章试图说清楚:
如何使用 Dify 自定义工具实现 MCP 的方法, 从而标准化 LLM 与多个数据源的交互方式。
以下,enjoy:
1、MCP 的统一之美
有关 MCP 的基础概念这里不做赘述,如果有不清楚的盆友可以翻下我之前的一篇文章快速扫盲后再往下看。
都说 MCP 在连接和利用来自多个异构系统的数据方面,扮演着所谓标准化粘合剂和智能调度员的角色,那 MCP 到底好在哪里,按照公开的说法和个人实践体验,按如下三点进行介绍:
1.1 标准化接口层:
每个系统(ERP、MES 等)都有自己独特的 API 接口、数据格式和认证方式。在 Dify 中直接调用意味着需要为每个系统配置和维护不同的 HTTP Request 节点,逻辑复杂且脆弱。

上篇文章中介绍的工作流,圈出的是4个http请求节点
通过创建 Dify 工具 (Tool),每个工具都封装与对应系统 API 交互的细节(URL、参数、认证、数据解析)。这样 Dify 的 Agent 或工作流不再需要关心底层 API 的复杂性,只需要知道调用一个名为 get_erp_stock 或 get_latest_iot_reading 的工具即可。这会极大地简化了工作流的编排,提高了可维护性和可重用性。


使用Dify的自定义工具替换了原有工作流中的四个http请求节点
1.2 上下文智能聚合:
其次,LLM 的能力很大程度上取决于提供给它的上下文的质量。简单地将来自不同系统的原始数据堆砌给 LLM 可能效果不佳。
上述提到的 MCP 理念构建的工具可以被 Dify Agent 智能地选择和调用。例如,当用户问:“PUMP-CNC-001 状况如何?需要订购备件吗?” Agent 可以识别出需要调用 get_latest_iot_reading 工具获取实时状态。 根据 IoT 状态(比如振动高),Agent 可能进一步判断需要调用 get_cmms_history 工具查看类似故障记录。 同时,调用 predict_failure 工具。 如果预测需要更换轴承,Agent 会调用 get_erp_stock 工具查询 CFP5K-BRG01 的库存。

MCP 的方法可以让 Agent 能够根据任务需求,动态地、按需地从多个系统中拉取最相关的信息,并将这些信息结构化地整合为高质量的上下文,再提供给 LLM 进行分析、预测或生成报告,而不是一次性将所有可能的数据都查询出来。
此处需要说明的是,上下文智能整合的作用更多的体现在Agent中,下文会进一步说明。
1.3 异构数据融合:
不同系统的数据类型可能差别很多,这个案例中提到的来自 IoT 的是时序数据,来自 CMMS 的是文本记录,而来自 ERP 的是结构化库存数据。

真实数据改变而来的泵类设备维修记录(知识库)
而 MCP 工具在封装 API 调用的同时,也可以进行初步的数据转换和格式化,将不同系统返回的数据统一或整理成更适合 LLM 理解的格式。 这会降低在 Dify 主工作流中进行复杂数据清洗和转换的负担,使得数据能在 LLM 处理前得到更好的预处理。
2、Dify 中如何构建自定义 tool
2.1 厘清概念
相信很多盆友看到过很多介绍 MCP 概念时会提到的 MCP Client / Server / Host 的解释,为了 避免大家有概念理解偏差,需要说明的是,在这个案例场景下:
MCP Client
发起工具调用的实体,也就是 Dify 工作流或 Agent。它通过 Dify 平台提供的标准化接口(工具节点)来请求服务。
MCP Server / Host
提供实际服务的端点。在这个例子中,就是模拟 API 服务器 上的各个API (/api/pump/status, /api/cmms/pump/history 等)。这个服务器理解工具调用背后转换成的 HTTP 请求并返回数据。
Dify 平台
扮演着协议转换器、编排器和代理的角色。它接收来自 Client (工作流节点) 的标准化工具调用请求,根据工具的 Schema 定义,将其转换为具体的 HTTP 请求发送给 Server/Host (你的 API),接收响应,再将其作为工具节点的输出返回给工作流。
2.2 如何创建 tool
在 Dify 中,点击"工作室”->"工具"->"创建自定义工具”。为每个工具输入名称(e.g.get_iot_status)。然后将编写好的对应 JSON Schema 完整复制并粘贴到"Schema"输入框中。

Dify 会自动解析Schema,并在下方"AvailableTools"部分显示识别出的AP操作(Operation)。你应该能看到类似 getIotstatus,getcmsHistory等。

确认"Authorization method" 为"None"。点击"保存"。然后对其他三个工具重复此过程。此外,建议进一步点击“test"做下进一步的连通性验证。
注:Dify 的做法是使用 OpenAPI Schema 来定义和管理自定义工具,而不是直接实现 Anthropic提出的特定 XML 交互格式,它们不直接等同,但目标一致,可以协同工作。
3、MCP 版 Agent
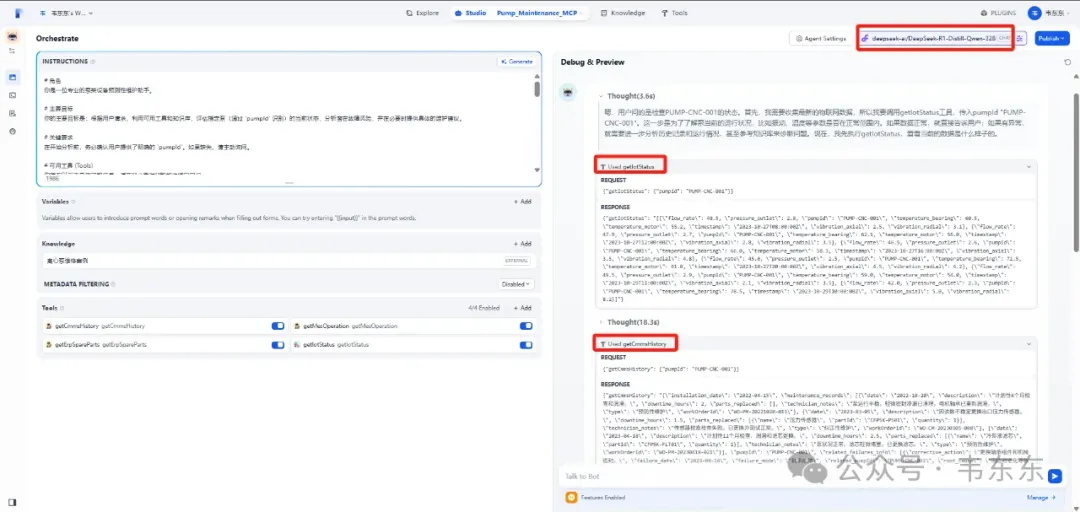
先设置好提示词,确保在 "工具 (Tools)" 部分,已经启用 getCmmsHistory, getMesOperation, getErpSpareParts 以及 getIotStatus 这四个工具。另外确保在 "知识库 (Knowledge)" 部分已经正确绑定维修案例。

尝试以下几种对话来观察 Agent 的行为:
注意,进行测试前需要先运行mock_api.py
3.1 简单状态查询:
"检查一下 PUMP-CNC-001 的状态怎么样?"
预期行为: Agent 只调用 getIotStatus。如果状态正常,它会报告正常并可能给出读数,不会调用 CMMS, MES, ERP 或知识库。
建议使用支持function call的LLM
3.2 触发异常的查询:
"PUMP-CNC-001 好像有点问题,帮我看看。" (假设此时 getIotStatus 返回的数据是异常的,例如高振动 7.5,高温度 75.8)

预期行为:
Agent 调用 getIotStatus,发现异常。
Agent 接着决定调用 getCmmsHistory 和 getMesOperation 获取更多背景。
Agent 同时/随后查询知识库 (使用类似 "PUMP-CNC-001 振动高 温度高 原因案例" 的查询)。
Agent 综合信息,可能会根据知识库中 PUMP-CNC-002 的案例,推断是轴承问题,需要 CFP5K-BRG01。
此时,Agent 才决定调用 getErpSpareParts (传入 partId=CFP5K-BRG01)。
最后,Agent 给出包含诊断、备件库存信息和维修建议的完整答复。
3.3 直接问解决方案:
"PUMP-LATHE-08 流量很低,怎么办?"
预期行为: Agent 可能直接查询知识库,找到 PUMP-LATHE-08 的案例,然后告诉你可能是机械密封泄漏,需要更换密封件。它不一定需要调用 getIotStatus 或其他工具(除非它想确认当前状态是否仍然是低流量)。
4、Chatflow 和 Agent 之争
前文讨论突出了 Agent(以及其背后利用的 MCP 思想)在处理需要动态规划、多工具协作、复杂推理场景下的优势。但这并不意味着固定编排的工作流 (Chatflow/Workflow) 就没有用武之地了。
事实上,固定编排的 Dify 工作流在很多场景下更高效和可靠。当然,选择哪种方式取决于你的具体需求、任务复杂度、以及你对流程控制的要求。以下是一些特别适合使用固定编排的 Dify Workflow/Chatflow 的情形:
4.1
流程确定且线性的任务:
当一个任务的执行步骤是固定的,或者只有有限且明确的分支 (可以通过 IF/ELSE 节点处理) 时,工作流是最佳选择。你不需要 LLM 去“思考”下一步该干什么,因为流程已经被精确定义好了。这对于需要保证合规性、安全性或特定业务逻辑的场景很重要。
反之,Agent 模式下,LLM 的自主决策可能引入不确定性(例如调用了非预期的工具,或者跳过了关键步骤)。
4.2 任务相对简单,LLM 主要用于特定子任务:
当 LLM 的作用只是流程中的一个“环节”(例如文本生成、摘要、翻译、情感分析、简单问答),而不是负责整个流程的规划和决策时,工作流更简单直接。
比如,客服意图识别与初步回复的流程一般是: 接收用户问题 -> 使用一个简单的分类模型或 LLM 判断用户意图 -> 根据意图路由到不同的回复模板或知识库查询 -> 输出初步解答。
4.3 对结果的稳定性和可预测性要求高:
由于工作流的流程是固定的,对于相同的输入(和外部 API 状态),其执行路径和最终结果通常是高度可预测和一致的。 Agent 的行为可能因为 LLM 的微小差异、Prompt 的理解偏差或上下文变化而产生波动。
例如,我前期做过的一些律所诉状和信贷风控报告类的项目中, 需要生成格式完全一致的法律文件或风险要点分析。 其中涉及执行需要精确结果的计算或数据验证任务,在工作流中 开发和调试也会相对简单些。
Dify 的 Agent 模式特别适合利用 MCP工具, Agent会像人一样,根据目标“规划”需要使用哪些工具(访问哪些系统),然后按顺序或并行执行,最终整合结果。这的确也比纯粹线性的工作流更灵活、更强大。
5、工作流+Agent 的珠联璧合
回到这个预测性维护场景来说:如果是希望按照“检查状态 -> (IF 异常 THEN 查 CMMS -> 查 MES -> 查 KB -> 预测 -> 查 ERP -> 建议)”这个固定流程来执行,那么工作流方式是合适的。
但如果希望问答助手能更灵活,比如用户问“PUMP-CNC-001 上次换轴承是什么时候?”,问答助手应该只调用 getCmmsHistory 就回答,而不是走完整个预测流程,那么 Agent 模式会更合适。
听起来,这似乎是一个非此即彼的问题。但实际的生产场景中,可以通过在 Dify 中构建一个智能的“路由器”,根据用户问题的性质将其导向最合适的处理单元(Agent 或 Chatflow)。
为了控制本文篇幅,这部分后续我在再专门写篇文章进行介绍, 先贴一下核心架构感兴趣的可以手搓下试试看。
5.1 用户入口
创建一个新的Dify应用,模式设置为Chatflow,可以命名为"Pump_Assistant_Router"。
5.2 后端 Agent:
上述创建好的 "Pump_Maintenance_MCP" Agent 应用,负责处理复杂的、需要动态规划和工具调用的问题。
5.3 后端 Chatflow:
创建一个或多个专门处理固定流程任务的 chatflow 应用。例如,Pump_Status_Check_chatflow: 接收 pumpId,调用 getIotStatus 工具,解析结果并直接回答状态。 Pump_Maintenance_Report_chatflow: 一个接收 pumpId 和时间范围,调用多个工具(如 getCmmsHistory, getMesOperation),并使用模板节点生成固定格式报告的 chatflow 等。
6、写在最后
MCP (或其背后的标准化、工具化思想) 是打通信息孤岛、充分利用 ERP、MES、CMMS、IoT 等多系统数据的关键。它通过标准化降低集成复杂度,通过智能调度提升上下文质量,通过数据融合简化处理流程,最终赋能 Dify (尤其是 Agent) 更高效、更智能地完成复杂任务,如本文的预测性维护案例。
后续我会继续分享些实操案例,进一步介绍MCP 工具不仅能获取信息 (get_...),更能被设计用来执行动作 (create_..., update_...)。这意味着基于 LLM 的分析和决策,可以直接触发业务流程,例如自动创建预测性维护工单,或根据库存情况建议订购备件。AI 不再只是辅助,而是成为了业务自动化的引擎。


