AI在线从中山大学官方微信公众号获悉,10 月 9 日,中山大学医学院施莽教授团队与阿里云李兆融团队在《细胞》(Cell)杂志上发表论文,报告了 180 个超群、超过 16 万种全球 RNA 病毒的发现,这是迄今为止规模最大的 RNA 病毒研究,大幅扩展了全球 RNA 病毒的多样性,该研究将人工智能技术应用于病毒鉴定,发现了传统方法未能发现的病毒“暗物质”,探索了病毒学研究的新路径。
据介绍,传统的病毒发现方法包括病毒分离和生命组学的生物信息学分析,高度依赖既有知识,面对 RNA 病毒这种高度分化、种类繁多且容易变异的病毒识别效率低。该研究团队开发的 LucaProt 人工智能算法能够对病毒和非病毒基因组序列深度学习,并在数据集中自主判断病毒序列。
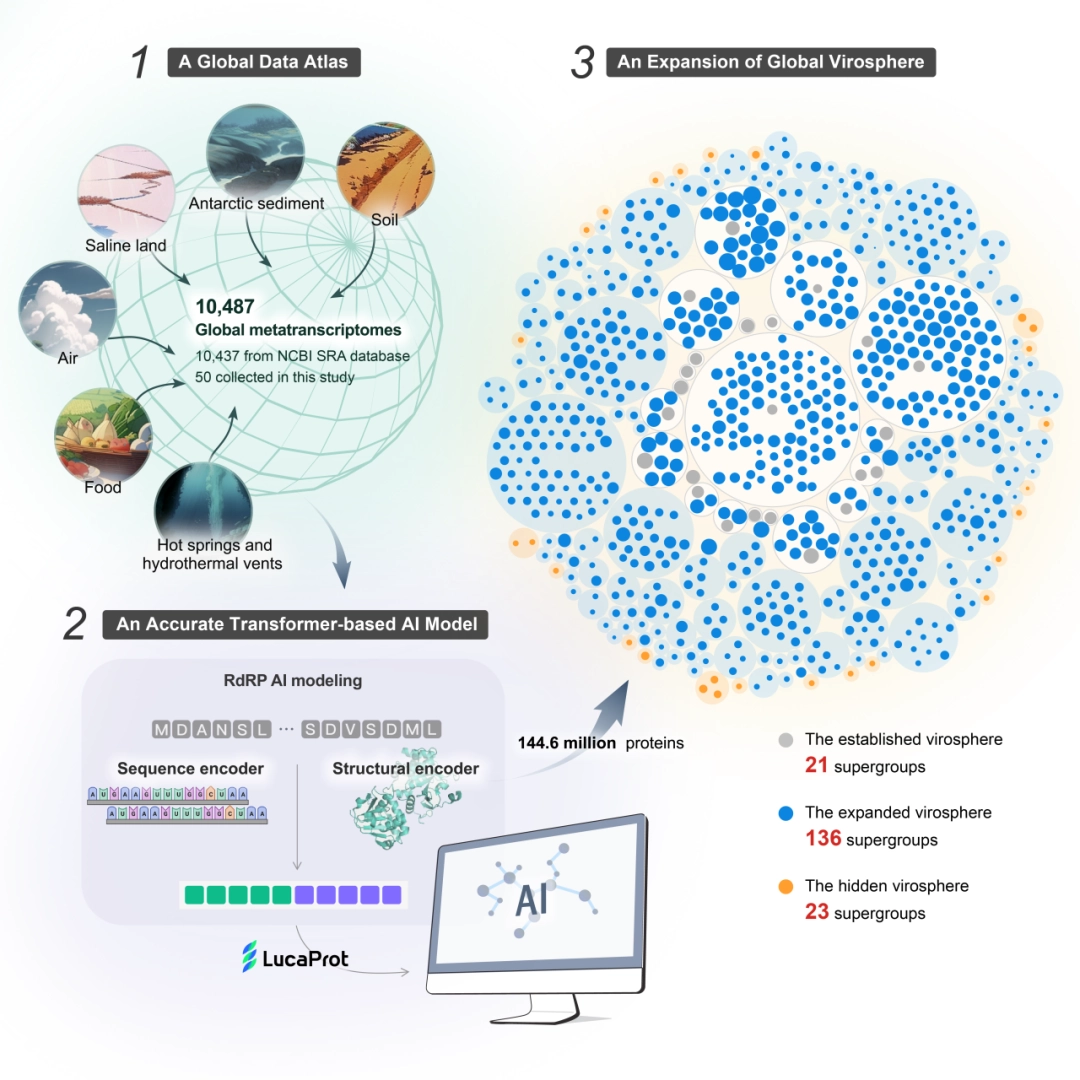
据AI在线了解,LucaProt 是一种能够深度学习的 Transformer 模型,在大量学习病毒和非病毒基因组序列后,可以自主形成一套关于病毒的判断标准,从而在大量的 RNA 测序数据集中挖掘出病毒序列。在测试中,LucaProt 表现出极高的准确性和特异性,假阳性率为 0.014%,假阴性率为 1.72%。在与其他病毒挖掘工具的对比中,它也在处理较长序列的方面展现出优势。
利用 LucaProt,研究团队对来自全球生物环境样本的 10,487 份 RNA 测序数据进行病毒挖掘,发现了超过 51 万条病毒基因组,代表超过 16 万个潜在病毒种及 180 个 RNA 病毒超群(相当于门或纲的分类级别),使 RNA 病毒超群数量扩容约 9 倍。其中 23 个超群无法通过序列同源方法识别,被称为病毒圈的“暗物质”。
在这项研究中,团队报告了迄今最长的 RNA 病毒基因组,长度达到 47,250 个核苷酸;发现了超出以往认知的基因组结构,展现出 RNA 病毒基因组进化的灵活性;识别到多种病毒功能蛋白,特别是与细菌相关的功能蛋白,进一步表明还有更多类型的 RNA 噬菌体亟待探索。
研究指出,新发现的病毒分布在地球的各类生态环境中。总体上,落叶层、湿地、淡水和废水环境的病毒多样性最高。然而,在南极底泥、深海热泉、活性污泥和盐碱滩等极端环境中,RNA 病毒的多样性和丰度并不低,甚至在深海热泉的高温环境中,仍有 RNA 病毒在活跃复制。
LucaProt 虽然是一个专门为 RNA 病毒发现设计的模型,但它同时融合了对蛋白质序列和隐含结构信息识别的功能,也可用于蛋白质功能的鉴定。在论文中,研究团队开源了 LucaProt 模型,并通过在线网站分享给全球科学家。