字节跳动豆包大模型团队与香港大学公开联合研究成果 —— HybridFlow。
官方宣称,HybridFlow(开源项目名:veRL)是一个灵活且高效的大模型 RL 训练框架,兼容多种训练和推理框架,支持灵活的模型部署和多种 RL 算法实现。
该框架采用混合编程模型,融合单控制器(Single-Controller)的灵活性和多控制器(Multi-Controller)的高效性,可更好实现和执行多种 RL 算法,显著提升训练吞吐量,降低开发和维护复杂度。
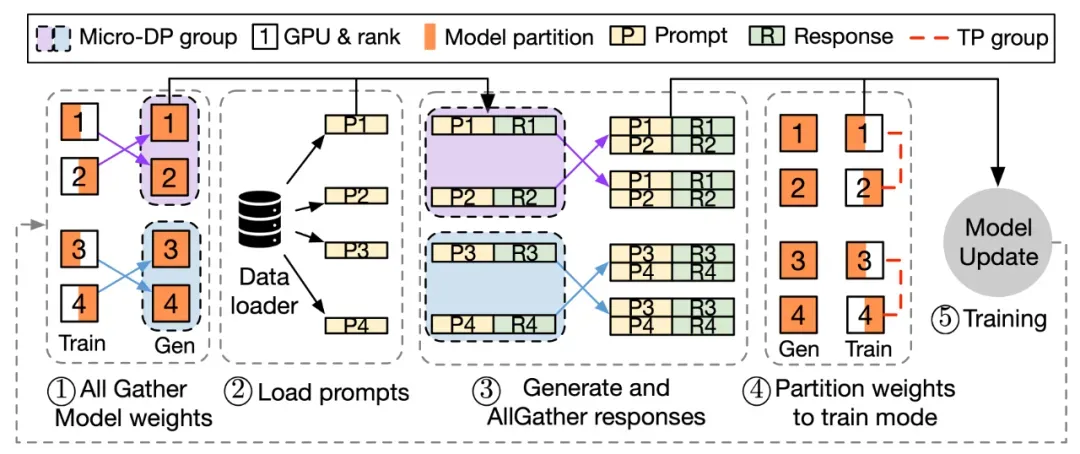
实验结果表明,HybridFlow 在各种模型规模和 RL 算法下,训练吞吐量相比其他框架提升了 1.5 倍至 20 倍。
目前,该论文已被 EuroSys 2025 接收,代码仓库也对外公开,AI在线附相关链接如下:
论文链接:https://arxiv.org/abs/2409.19256
代码链接:https://github.com/volcengine/veRL


