在大语言模型(LLM)快速发展的背景下,研究者们越来越关注如何通过多代理系统来增强模型性能。传统的多代理方法虽然避免了大规模再训练的需求,但仍面临着计算效率和思维多样性的挑战。本文提出的稀疏代理混合(Sparse Mixture-of-Agents, SMoA)框架,通过借鉴稀疏专家混合(Sparse Mixture-of-Experts, SMoE)的设计理念,有效解决了这些问题。

基础架构:MoA模型
在介绍SMoA之前,需要先了解基础的混合代理(Mixture-of-Agents, MoA)架构。在MoA中,系统包含l层,每层包含n个提议者(proposer)。其核心运算可以通过以下公式表示:

其中:
- P_i,j 表示第i层的第j个提议者
- x_i 是输入文本
- ⊕ 表示聚合-综合提示操作
- y_i 是第i层的输出
最终输出通过聚合器(Aggregator)生成:
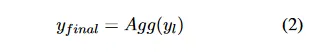
SMoA架构解析
SMoA(Sparse Mixture-of-Agents)的架构设计融合了多层级代理交互和稀疏化处理,主要包含以下核心组件:

- 输入层:接收初始提示(Prompt)
- 处理层:包含多个并行的代理模块
- 输出层:生成最终响应
1. 代理模块(Agent Module)
处理输入信息并生成候选响应
- 每个模块都有独特的角色定义
- 并行工作以提高效率
- 通过角色扮演促进思维多样性
2. 评判代理(Judge)
每个处理层之间
- 评估当前层所有代理的输出
- 选择最优质的k个响应
- 过滤低质量或重复信息
工作流程
复制输入: n个代理响应
过程: 质量评估与排序
输出: k个最优响应(k < n)3. 调节代理(Moderator)
处理层的最后
- 监控整体进度
- 评估响应质量和一致性
- 决定是否继续迭代
决策依据
- 响应质量评分
- 代理间一致性程度
- 迭代轮次计数
4. 信息流动路径
前向传递
- 输入提示进入第一层代理模块
- 并行代理生成候选响应
- 评判代理选择最优响应
- 调节代理评估是否继续
反馈机制
- 评判结果影响下一轮代理行为
- 调节决策控制迭代进程
- 动态调整处理深度
SMoA的技术创新
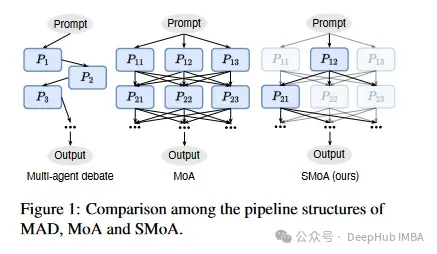
上图展示了传统MAD、MoA与SMoA的架构对比,我们来通过公式进行详细介绍
1. 响应选择机制
SMoA引入评判代理(Judge)来实现响应选择,其数学表达为:

这个机制通过选择最佳的k个响应显著减少了计算开销,其中k是控制网络稀疏度的参数。
2. 早停机制
调节代理(Moderator)的决策过程可以表示为:
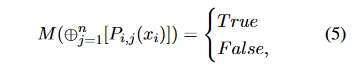
这个布尔值决定是否继续迭代过程,有效降低了不必要的计算。
3. 角色扮演机制
角色分配过程可以表达为:

其中:
- D 是数据集描述
- T 是任务需求
- r_i 是分配给每个提议者的角色描述
这些数学公式清晰地展示了SMoA各个组件的工作机制,以及它们如何共同实现系统的稀疏化和效率提升。
实验评估与结果分析
评估框架
研究团队在三个主要维度进行了全面评估:
1.Just-Eval对齐性评估
- 评估指标:有用性、清晰度、事实性、深度、参与度、安全性
- 使用GPT-4进行评分,满分5分
- 涵盖多个知名数据集
2.MMAU推理能力评估
- 数学理解(Math)
- 工具使用(Tool)
- 代码竞赛(Code)
- 使用准确率作为评估指标
3.CEB公平性评估
- 主要关注有害性和刻板印象
- 分数越低表示性能越好
关键实验结果
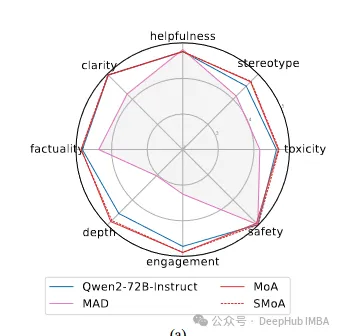
1.对齐性能比较:
复制性能提升 = (SMoA得分 - 基线得分) / 基线得分 * 100%- Qwen2-72B-Instruct: +1.9%
- Qwen1.5-72B-Chat: +1.7%
- Mixtral-8*22B: +3.6%
2.推理能力评估:
复制平均得分 = (Math + Tool + Code) / 3- 基线模型:20.78分
- SMoA提升:+18.2%
- MoA提升:+24.9%
3.计算效率分析:
复制效率比 = SMoA处理时间 / MoA处理时间显示SMoA平均可节省约40%的计算资源
创新贡献与未来方向
主要贡献
1.架构创新
- 提出稀疏化的多代理框架
- 引入评判和调节机制
- 实现角色多样性
2.性能突破
- 维持高性能的同时显著降低计算成本
- 提高系统可扩展性
- 增强思维多样性
3.实践价值
- 为大规模部署提供可行方案
- 降低运营成本
- 提高系统效率
未来研究方向
1.网络结构优化
- 探索更复杂的代理连接方式
- 研究动态网络拓扑
2.激活策略改进
- 开发更智能的代理选择机制
- 优化早停判断标准
3.应用场景拓展
- 探索在更多领域的应用
- 研究特定任务的优化策略
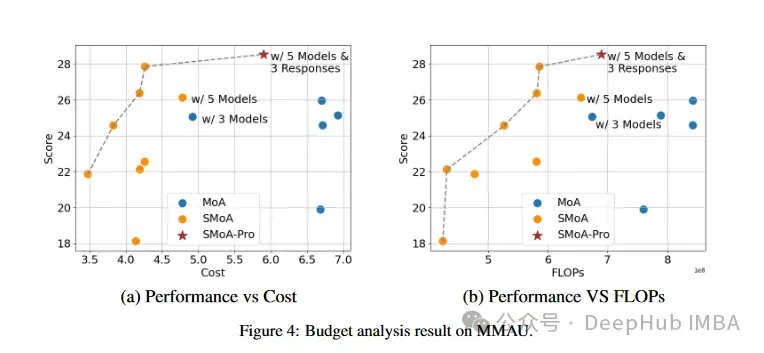
这项研究不仅在理论上提供了创新的解决方案,也在实践中展示了显著的改进效果。通过引入稀疏化和角色多样性,SMoA为大语言模型多代理系统的发展开辟了新的方向。


