本文经3D视觉之心公众号授权转载,转载请联系出处。

InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
介绍:https://research.nvidia.com/labs/toronto-ai/infinicube/
论文:https://arxiv.org/abs/2412.03934v1
InfiniCube 是由英伟达主导开发的一种新型3D生成方法,用于生成无界且可控制的动态3D驾驶场景。
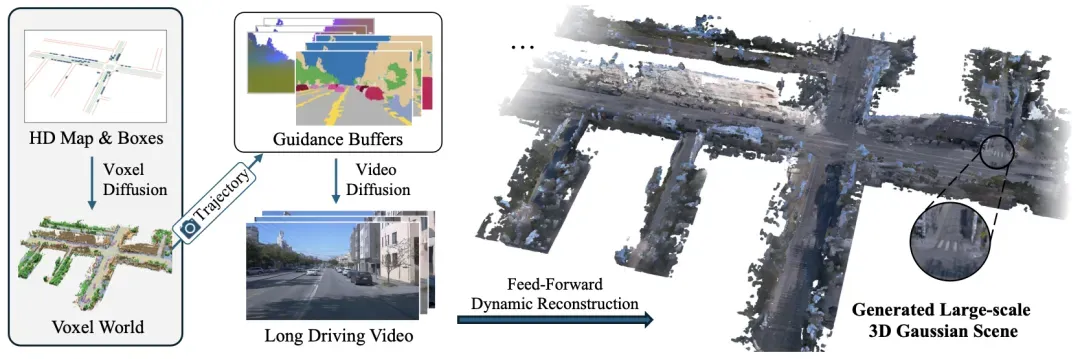
InfiniCube 通过结合高清地图、车辆边界框和文本描述,利用最新的3D表示和视频模型技术,实现了大规模动态场景的生成。

这种方法不仅能够生成具有高保真度和一致外观的3D结构,还能够保持几何和外观的一致性,这对于自动驾驶车辆的模拟训练和测试尤为重要。

InfiniCube 的关键特性在于其能够构建一个基于语义体素的3D世界表示,并将其作为视频生成模型的引导。

这一创新使得InfiniCube能够生成大规模、细节丰富且与物理世界保持一致的动态3D驾驶场景。此外,InfiniCube还提出了一种快速的前馈方法,将动态视频和体素世界转换为动态3D高斯场景,同时保留对动态车辆的控制能力。技术解读
InfiniCube 技术的思路是利用先进的3D表示和视频模型,结合高清地图、车辆边界框和文本描述,生成无界且可控制的动态3D驾驶场景。
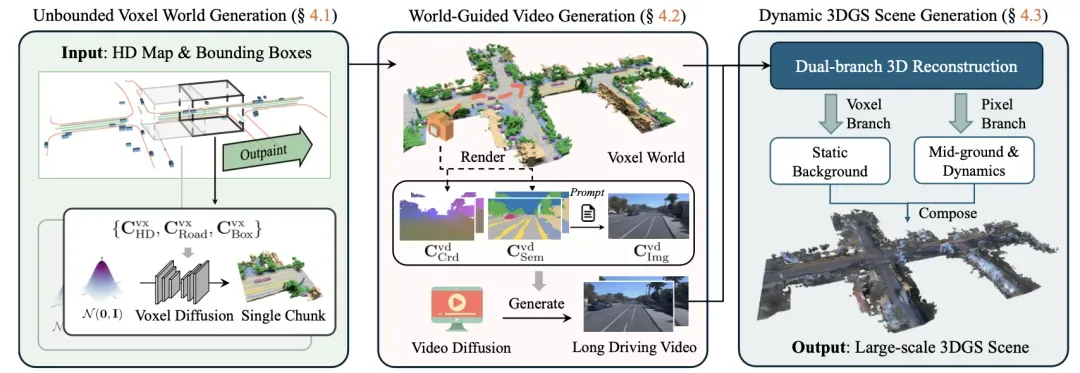
这项技术通过构建一个基于高清地图条件的稀疏体素3D生成模型来生成大规模的语义体素世界,然后利用视频模型和一系列像素对齐的引导缓冲区来合成一致的外观,最终通过快速前馈方法将视频和体素世界转换为动态3D高斯场景,实现了对动态车辆的精确控制。

InfiniCube 的具体处理过程包括三个主要阶段:
- 首先,无界体素世界生成阶段,通过HD地图和车辆边界框作为输入,生成对应的3D体素世界和语义标签;
- 其次,世界引导的视频生成阶段,基于Stable Video Diffusion模型,通过生成的体素世界提供的几何和相机轨迹条件,辅助长视频生成;
- 最后,动态3DGS场景生成阶段,通过双分支重建方法,结合体素和像素信息,生成动态3D高斯场景。
其技术特点主要包括:
- 能够处理大规模场景,支持约100,000平方米的3D动态场景生成;
- 高保真度和可控性,可以灵活控制场景布局、外观和车辆行为;
- 一致性,保持生成序列中几何和外观的一致性;
- 快速前馈方法,提高了场景重建的效率。
InfiniCube 技术为自动驾驶车辆的训练和测试提供了一个高度真实和可控的虚拟环境,这对于模拟复杂交通场景和对抗性场景尤为重要,有望在自动驾驶领域实现更广泛的应用。此外,其在混合现实和机器人技术等领域也具有广泛的应用前景。论文解读
这篇论文介绍了一个名为InfiniCube的系统,它是一个用于生成无界且可控制的动态3D驾驶场景的方法。以下是论文内容要点概括:
摘要
- 提出了InfiniCube,一个可扩展的方法,用于生成高保真度和可控性的无界动态3D驾驶场景。
- 该方法利用高清地图、车辆边界框和文本描述来实现灵活控制。
- 通过结合3D表示和视频模型的最新进展,实现了大规模动态场景的生成。
引言
- 生成可模拟和可控的3D场景对于混合现实、机器人技术以及自动驾驶车辆的训练和测试等领域至关重要。
- InfiniCube旨在满足以下关键需求:保真度和一致性、大规模场景生成以及可控性。
相关工作
- 回顾了3D生成、可控视频生成和驾驶场景重建等领域的相关研究进展。
预备知识
- 介绍了潜在扩散模型(LDM)和稀疏体素LDM,这些是InfiniCube方法的基础。
方法
- InfiniCube的目标是生成大规模动态3D场景,通过输入高清地图、车辆边界框和文本提示来实现。
- 4.1 无界体素世界生成:基于高清地图和车辆边界框生成语义体素世界。
- 4.2 世界引导的视频生成:使用视频模型生成与体素世界一致的外观。
- 4.3 动态3DGS场景生成:将体素和视频合成为动态3D高斯场景。
实验
- 5.1 数据处理:使用Waymo Open Dataset进行训练,提取地面真实场景几何以监督语义体素生成。
- 5.2 实现细节:详细介绍了各个阶段的网络架构和训练细节。
- 5.3 大规模动态场景生成:展示了完整管道生成的场景,并分析了各个组件的重要性。
- 5.4 主要组件分析:通过消融研究验证了HD地图条件设计的有效性,并与基线方法进行了比较。
- 5.5 应用:InfiniCube支持新视角合成、碰撞模拟等应用,并展示了车辆插入和天气控制等高级应用。
讨论
- 讨论了InfiniCube的局限性,包括几何多样性的限制和管道的复杂性。
- 总结了InfiniCube的贡献,并提出了未来的研究方向,包括扩大训练数据规模和加速生成过程。
结论
- InfiniCube通过结合体素世界生成模型、世界引导的视频模型和动态3DGS生成模型,能够生成具有丰富外观细节和完全可控性的现实3D场景。


