
会议背景
2024年10月28日至11月1日,ACM Multimedia(ACM MM) 2024在澳大利亚墨尔本召开,该会议是中国计算机学会(CCF)推荐的多媒体领域的A类国际学术会议。2024年共4395篇参与审稿,最终录用1149篇论文,录用率26.1%。
火山引擎-流媒体技术与湖南工商大学、湘江实验室合作的论文"Align-IQA: Aligning Image Quality Assessment Models with Diverse Human Preferences via Customizable Guidance" 被ACM Multimedia 2024 收录。
论文链接:https://openreview.net/pdf?id=CdA18J5jJx

论文方案
论文背景
图像质量评价(Image Quality Assessment, IQA)是图像处理和计算机视觉领域中的一项重要任务,旨在模拟人类视觉系统对图像质量的感知过程,构建与人类主观判断尽可能一致的客观质量评价算法。最初,IQA的研究主要聚焦于评估经过特定处理(如压缩、模糊或添加噪声)的自然场景图像、之后逐步扩展到用户生成内容(User-Generated Content, UGC)(如使用智能手机等电子设备拍摄的图像),以及近年来流行的人工智能生成内容(AI-Generated Content, AIGC)(如通过文本到图像模型生成的图像)。为了应对这些不同类型的图像内容的质量评估需求,研究者们投入了大量精力,提出了多种IQA方法。然而,由于人类对于不同类型的图像内容的偏好存在差异,如何使得IQA模型与这些偏好保持一致,依然是一个亟待解决的挑战。尽管现有的IQA方法通过利用预训练模型中的知识,在评估特定图像内容(自然场景图像、UGC图像)方面取得了重大成功,但由于影响最终评估结果的复杂因素众多,以及这些方法所特有的、精心设计的网络架构,它们在准确捕捉人类对新型的图像内容(AIGC图像)的偏好方面仍存在不足。
基于可定制指导的对齐人类主观偏好的图像质量评价方法——Align-IQA
为了解决现有的IQA方法在准确捕捉人类对新颖图像内容的偏好方面的不足,本文提出了一种基于可定制指导的对齐人类主观偏好的图像质量评价方法——Align-IQA。该方法能够针对不同类型的图像内容,生成与人类偏好高度一致的质量评分。
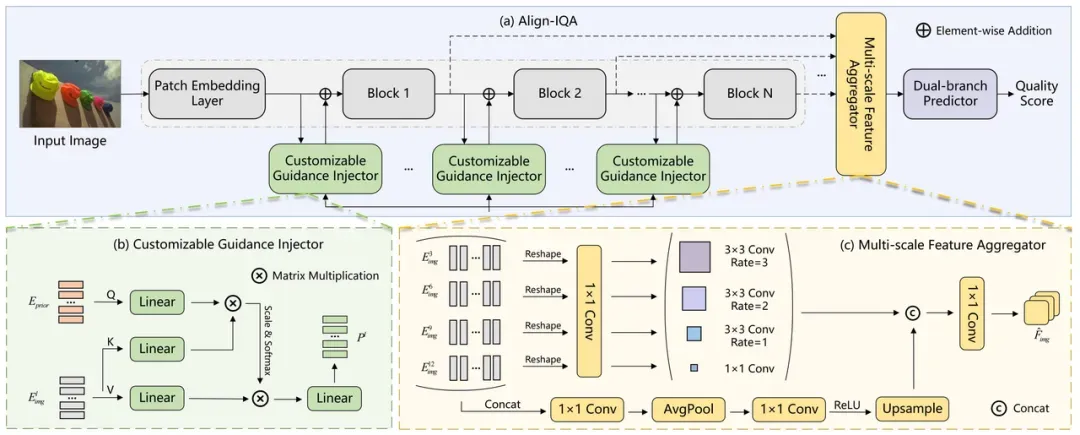
可定制指导注入模块
在对自然场景图像、UGC图像和AIGC图像进行质量评估时,人类能够根据自身的知识和经验灵活地调整评估标准。对于自然场景图像和UGC图像,人类评估的重点是图像的视觉保真度;而对于AIGC图像,除了视觉保真度之外,人类还会关注图像与文本提示之间的语义一致性。为此,本文提出了一种可定制指导注入模块(Customizable Guidance Injector, CGI),旨在根据不同类型的图像内容(自然场景图像、UGC图像和AIGC图像)引入相应的人类先验知识,从而使得同一个质量评价模型能够针对这些不同类型的图像内容进行自适应评估。
具体而言,对于自然场景图像和UGC图像,CGI模块通过引入视觉显著性特征作为指导,来帮助模型提取与质量感知相关的特征;对于AIGC图像,CGI模块则通过引入图像和文本提示之间的语义一致性特征,来引导模型提取与质量感知相关的特征。

多尺度特征聚合模块
在人类视觉系统中,有许多视觉特性影响着人类对图像质量的感知。为了构建一个能更贴近人类视觉感知的图像质量评价模型,本文提出了一种多尺度特征聚合模块(Multi-scale Feature Aggregator, MSFA)。该模块通过模拟人类视觉系统的多尺度机制,能够更全面且有效地提取与质量感知相关的特征。同时,它还结合了深度可分离膨胀卷积,以较少的参数高效地实现多尺度信息的提取和融合工作。
实验结果
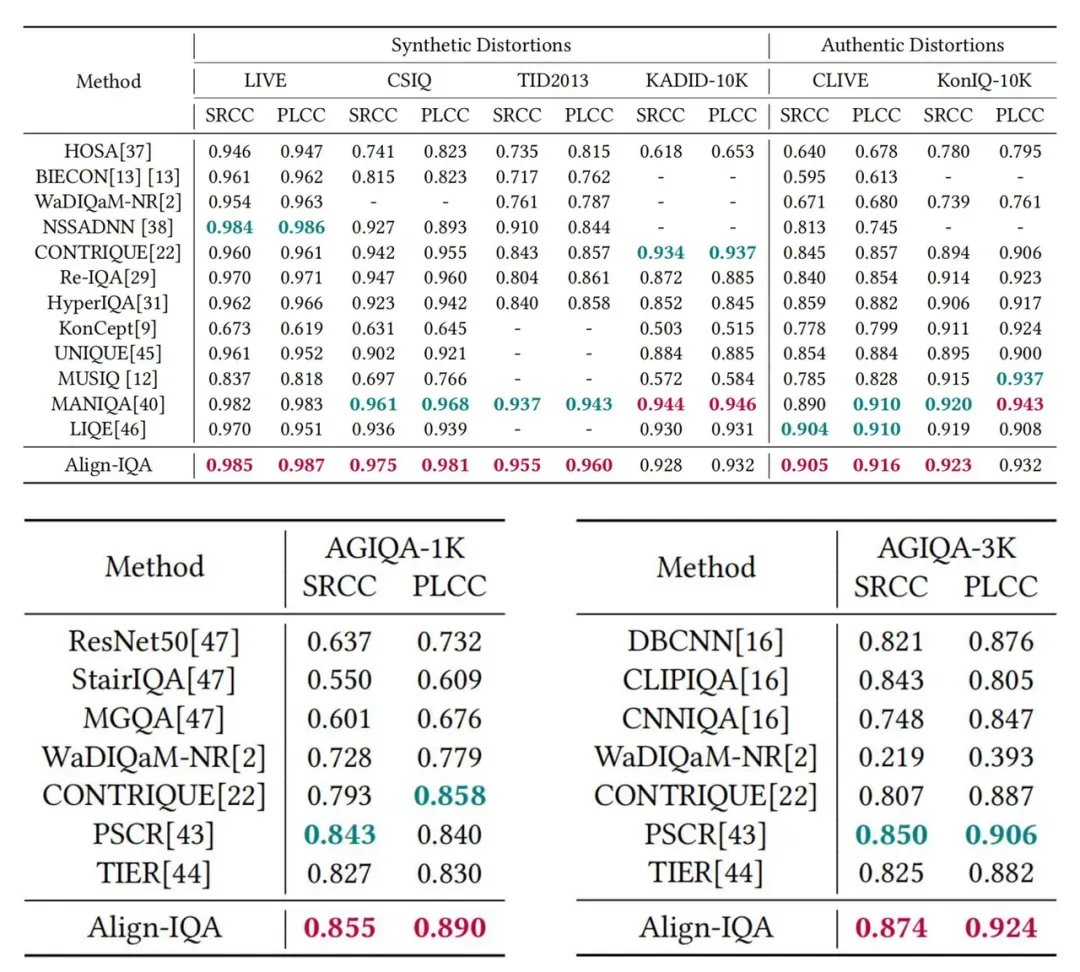
在八个公开数据集(四个自然场景图像数据集:LIVE、CSIQ、TID2013和KADID-10K;两个UGC图像数据集:CLIVE和KonIQ-10K;两个AIGC图像数据集:AGIQA-1K和AGIQA-3K)上的实验结果显示,Align-IQA能够针对不同类型的图像内容,生成与人类偏好高度一致的质量评分。这充分验证了Align-IQA的有效性和普适性。
总结
本文提出了一种基于可定制指导的对齐人类主观偏好的图像质量评价方法—Align-IQA,该方法能够自适应地对自然场景图像、UGC图像和AIGC图像进行高效的质量评估。为了实现这一适应性评估,本文提出了一个可定制指导注入模块,用于根据不同类型的图像内容引入相应的人类先验知识。此外,为了更准确地从人类视觉感知的角度预测图像的质量评分,本文提出了一个多尺度特征聚合模块。实验结果表明,Align-IQA在涵盖多种图像类型的八个公开数据集上,达到了优于或与SOTA方法相当的性能。


