编辑丨&
生命的诞生充满谜团。从第一个蛋白质分子出现,再到首个细胞完成了自己的分裂。现在的奇迹来自于一个个鲜活的细胞聚合体。
而现在,随着人工智能的发展,AI 虚拟细胞(AIVC)的创建也逐渐从无走到有。为了能更好的了解生命的运作方式与疾病的发病原理,AIVC 成为了当前热门且极有潜力的探索方向。
虽然,细胞的属性与行为无不在挑战物理与计算建模的极限,其中动态和适应系统所蕴含的复杂行为让整个细胞内部对于扰动的反应处于截然不同的反应状态。
现有的细胞模型通常是基于规则,并将有关潜在生物学机制的假设与来自观察数据的参数相结合。这通常依赖于明确定义的数学或计算方法,不同的复杂程度涵盖了细胞生物学的不同方面。
来自斯坦福大学的研究人员们呼吁,现在正是利用 AI 来创造第一个 AIVC 的时候。他们的声音以「How to build the virtual cell with artificial intelligence: Priorities and opportunities」为题,于 2024 年 12 月 12 日发布在《Cell》。

对人类细胞进行建模可以被认为是生物学的圣杯。团队中,一位教授如此形容道。AI 提供了直接从数据中学习的能力,并超越假设和直觉来发现复杂生物系统的新兴特性。
AIVC
从实验上讲,测量技术吞吐量的指数级增长导致不同细胞和组织系统内和之间收集了大型且不断增长的参考数据集。在过去几年中,数据以及将这些测量与系统扰动耦合的能力每 6 个月翻一番。
在计算方面,AI 的并发进步增强了我们直接从数据中学习模式和过程的能力,而无需明确的规则或人工注释。
AI 中的最新建模方法提供了表示和推理工具,这些工具满足预测、生成和可查询的三重奏,是推进生物学研究和理解的关键实用程序。通过建立这些特性,现在有方法来开发一个完全由数据驱动的基于神经网络的 AIVC 表示。
它可以通过实现快节奏的计算机研究,以及计算方法和验证性湿实验室实验之间的强大桥梁来加速生物医学的研究。
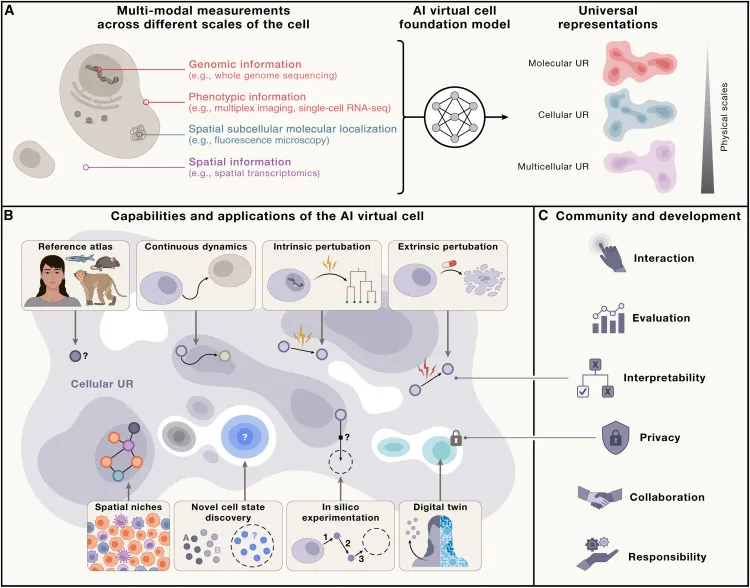
图 1:AIVC 的功能。(图源:论文)
AIVC 的创建将开启生物学高保真模拟的新时代。将通过改变生成假设和确定优先级的方式,使生物学家能够跨越一个大大扩展的范围,更好地适应生物学的巨大尺度,从而赋予实验者和理论家权力。
尽管细胞模型可能并不总是直接识别机制关系,但他们可以被视为有效缩小机制假设并搜索空间的工具,从而加速发现细胞功能背后的潜在因素。
虚拟细胞路上的重大挑战
生物学中数量激增的基础模型执行了本视角中概述的虚拟单元功能的子集。生物学非常复杂:它在不同的尺度、不同的环境中运作,并用不同的模式进行测量。AIVC 模型必须在所有这些轴上保持一致。
AIVC 模型最终将根据大型基础模型通过为生物过程提供新的见解或加速科学过程来扩展我们对生物学的理解的能力进行评判。可操作的模型输出是设计经济实惠且高效的验证实验的高实用性,是初始实际使用的关键。
AIVC 的成功开发需要跨学科的合作,而生成反映人类多样性的大型数据集是非常艰难的。且先不说在使用 AIVC 的时候,方式方法是否合乎道德或者透明,亦或者数据是否会被伪造造成模型污染。
AIVC 协作开发的一个基本问题是应该收集哪些数据和模式以实现跨生物背景和规模的泛化。
这些数据需要涵盖不同物种、领域和模式的生物学广度,代表生命的异质性,同时保持足够的深度以区分真实信号和噪声。数据生成的一个关键方面是同时测量时间和物理尺度,同时还允许对系统进行扰动。
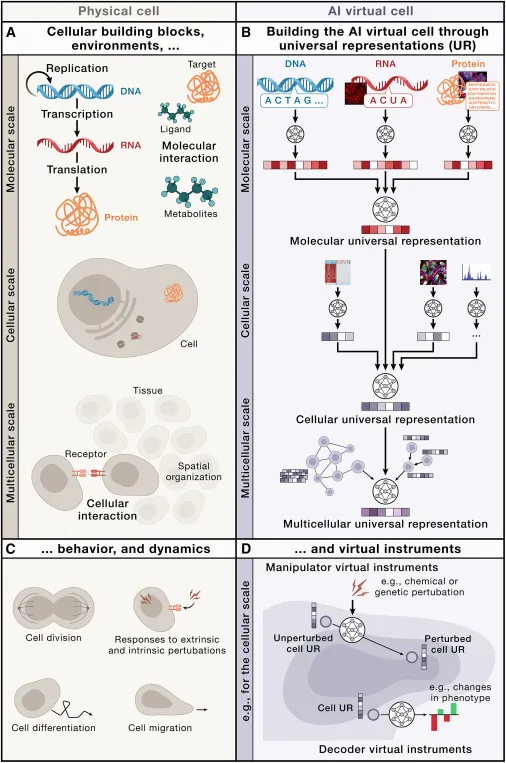
图 2:AIVC 概述。(图源:论文)
AIVC 将是一个多尺度基础模型,它在每个物理尺度上学习生物实体的不同表示。每种表示都普遍适用于特定类别的生物实体。这种抽象允许虚拟单元在这个通用框架内无缝发展和整合新数据。无论是来自新模式还是来自分布式外源。
用于构建的 AI 技术
AIVC 将连接许多不同的神经网络架构。尽管这些架构可能不是专门为生物应用而设计的,但它们在与特定的生物模式和归纳偏差匹配时都得到了成功的结果。
扩散模型是一类生成式深度学习模型,最近因其能够在各个领域生成高质量、多样化的样本而受到关注。基于扩散模型架构,流匹配方法等方法也可以对随时间推移的分布演变进行建模。
扩散和流匹配模型学习和复制复杂分布的能力,结合流匹配方法的时间和空间建模功能,使其特别适合涉及生物系统典型高维复杂数据结构的任务。
AIVC 的起点是模拟中心法则的三种类型的分子:DNA、RNA 和蛋白质。这些都可以表示为字符序列核苷酸或氨基酸。此类序列数据特别适合最初为自然语言处理开发的 AI 方法,例如大型语言模型(LLM)。
下一个抽象级别对单个细胞状态进行建模。由于细胞功能以细胞中形成的分子相互作用和信号网络为基础,因此可以使用分子和其他特征的表示来构建细胞 UR,描述分子成分的组织和丰度。
从模型架构的角度来看,transformer 或利用卷积神经网络(CNN)的模型广泛适用于生物图像,跨多个成像通道进行建模,捕捉不同的生物特征。随着 AIVC 模型的复杂性增加,对细胞器和无膜隔室进行建模也至关重要。
从单细胞到多细胞的建模,需要走的路会更长,此处不做过多赘述。
值得乐观的前景
遗传学和基因组学界已经创建了许多大型参考数据集,而借由这些项目,可以使用大量参考数据来训练机器学习模型。虽然这些努力并未发展完善,但它们也促进了一项新的平行努力:创建细胞生物学的虚拟模拟,这是一种科学探究的新流程。
因此,AIVC 有可能彻底改变科学过程,从而在生物医学研究、个性化医学、药物发现、细胞工程和可编程生物学方面取得未来突破。作为虚拟实验室,其可以促进模拟实验数据与现实实验结果的无缝衔接。
团队坚定不移地倡导开放科学方法的作用,在开放科学方法中,科学界乐于共享数据、模型和基准,将发现和见解置于情境中,并营造持续改进的氛围。他们欢迎并鼓励各部门和领域的所有利益相关者参与这项工作。
在庞大的科学背景与共同目标的促成下,他们相信,人类正迈向科学发展的新方向。
原文链接:https://www.cell.com/cell/fulltext/S0092-8674(24)01332-1