如果不提前告诉你,你可能很难相信这段视频里的语音全部是 AI 生成的:

这些声音来自 Dia-1.6B——一个刚刚在 𝕏、GitHub 等平台上走红的开源语音模型。它不仅能生成说话的声音、对话,同时也能合成真实感非常强的笑声、喷嚏声和吸鼻子声等表达情绪的声音。
由于效果过于逼真,它在 GitHub 上线后不到 24 小时就收获了超过 3.4k star,现在的 star 数更是已经达到了 5.4k。同时,Dia-1.6B 也是目前 Hugging Face 上热度第二的模型,目前已经被下载了超过 5600 次。

- GitHub:https://github.com/nari-labs/dia/
- Hugging Face: https://huggingface.co/nari-labs/Dia-1.6B
- 试用地址:https://huggingface.co/spaces/nari-labs/Dia-1.6B
在和 ElevenLabs Studio、Sesame CSM-1B 等之前以逼真著称的模型对比之后,Dia-1.6B 依然有着明显的优势,尤其是在情绪表达方面。

表现如此之好,自然也是收获好评无数:


机器之心也做了一些简单的尝试,下面是一个示例

整体来说,Dia-1.6B 在合成简单英语对话方面确实表现卓越,但却并不能很好地理解用户通过括号标注的指令,偶尔会出现类似电流的杂音。
Dia 模型细节
Dia 来自 Nari Labs,是一个 1.6B 参数量的文本转语音模型。
Dia 可以直接基于文字生成高真实感的对话。用户可以对输出的音频进行调整,从而控制其情绪和语调。同时,模型还可以生成非语言的交流声音,例如笑声、咳嗽声、吸鼻子声等。
并且 Nari Labs 开源发布了 Dia,使用了 Apache License 2.0 证书。该团队表示:「为了加速研究,我们提供了预训练模型检查点和推理代码的访问权限。模型权重托管在 Hugging Face 上。」
不过遗憾的是,目前该模型仅支持英语生成。
硬件和推理加速
目前 Nari Labs 并未发布 Dia 模型的详细技术报告,但我们可以在其 Hugging Face 页面看到些许有关硬件和推理加速的技术细节。
该团队表示,Dia 目前仅在 GPU 上进行过测试(Pytorch 2.0+,CUDA 12.6)。CPU 支持也即将添加。并且由于需要下载 Descript Audio Codec,初始运行会需要更长时间。
在企业级 GPU 上,Dia 可以实时生成音频。在较旧的 GPU 上,推理会更慢。作为参考,在 A4000 GPU 上,Dia 大约每秒生成 40 个 token(86 个 token 相当于 1 秒的音频)。torch.compile 将提高受支持 GPU 的速度。
Dia 的完整版本需要大约 10GB 的显存才能运行。不过该团队承诺未来会放出一些量化版本。
Dia 还有更大规模的版本。在 Nari Labs 的 Discord 中,开发者 Toby Kim 表示更大的模型还处于规划阶段。感兴趣的用户可以通过这个链接加入等待列表:https://tally.so/r/meokbo
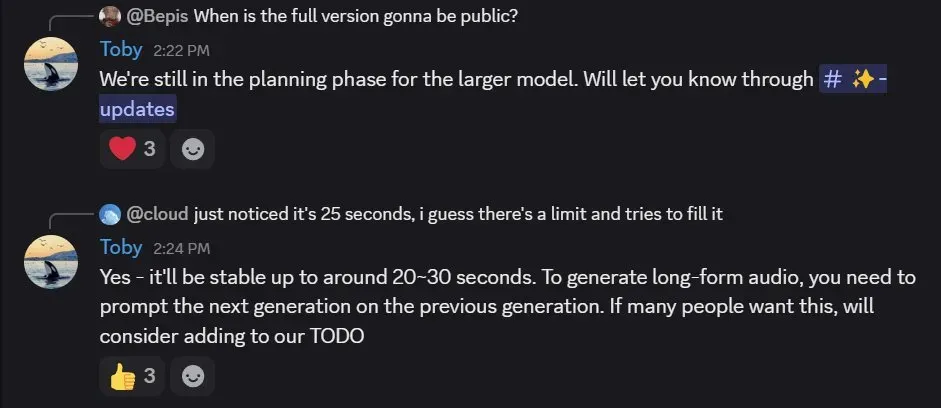
另外,Toby Kim 还指出目前最长能稳定生成大约 25 秒的音频,但用户也可以基于之前的生成结果来生成更长的音频。
Nari Labs 简介
Nari Labs 的 Hugging Face 页面透露,Nari 是一个源自韩语的词(나리),意为百合。
据介绍,Nari Labs 是一个非常小的团队,目前仅有一位全职研究工程师和一位兼职研究工程师。他们的 GitHub 账户也是四天前才刚注册的。

其中一位开发者 Toby Kim 在 𝕏 上表示,这两位工程师目前都还是本科生。而他们的目标是「构建一个可以与 NotebookLM Podcast、ElevenLabs Studio 和 Sesame CSM 相媲美的 TTS 模型。」

目前看来,他们已经取得了初步的成功。Toby Kim 表示这项成功耗时三个月时间,而这个过程中他们遇到的最大阻碍是计算不足。

接下来,他们计划将 Dia 做成一个 B2C 应用,可以生成有趣的对话和混音内容。


