让推理模型不要思考,得到的结果反而更准确?
UC伯克利新研究发现,强制要求模型跳过思考过程,推理能力却比正常思考还好。
例如在定理证明任务当中,“不思考”模式仅使用30%的Token,就能实现和完整思考一样的准确率。

特别是施加Token限制之后,“不思考”模式的效果变得更加明显。

这究竟是怎么一回事呢?来看下UC伯克利发表的论文。
跳过思考,推理模型反而更强了
论文的研究目的,是比较显式思考过程(Thinking)和跳过思考过程(NoThinking)的效果差异,并在不同约束条件下评估这两种方法的表现。

研究使用DeepSeek-R1-Distill-Qwen-32B作为主要实验模型,该模型通过在Qwen-32B基础上使用DeepSeek-R1生成的数据进行蒸馏得到。
为了确保结果的可靠性,研究同时选择了Qwen-32B-Instruct作为基线模型,并在7B和14B规模的相同架构模型上进行了验证实验。
在数据集的选择上,研究力求全面覆盖不同类型的推理任务:
- 在数学问题方面,既包含了AIME 2024、AIME 2025、AMC 2023等标准难度的测试集,也包含了更具挑战性的OlympiadBench数学子集;
- 在编程能力评估方面,使用了持续更新的LiveCodeBench v2版本;
- 在定理证明领域,则通过MiniF2F测试形式化数学推理能力,通过ProofNet评估逻辑和定理证明能力。
实验首先进行了基础性能评估,也就是在不限制token的情况下比较三种方法的表现。研究团队详细记录了每种方法在不同k值下的pass@k性能表现和token使用量。
结果显示,在无预算限制的情况下,NoThinking在定理证明任务上能够以30%的token用量达到与Thinking相似的性能,两种方法都明显优于基线模型。
在其他任务上,虽然NoThinking的初始pass@1性能较低,但随着k值增加会逐渐追平Thinking的表现,同时token使用量减少

随后,实验引入了预算强制,通过设置token限制来进行对照实验。
具体来说,当模型达到预设的token预算时,系统会强制其生成最终答案,如果此时模型仍在思考框内,则会在最终答案标签前添加结束思考标记。
研究分别在低预算(约3000tokens以下)和高预算(约3500tokens)两种场景下进行了详细测试。
在预算受限的场景下,NoThinking在低预算情况下(<3000 tokens)完全优于Thinking,这种优势会随着k值的增加而扩大。
在高预算场景下(~3500 tokens),尽管Thinking在pass@1上略有优势,NoThinking从k=2开始就展现出更好的性能。

在并行扩展测试中,研究根据任务特性采用了不同的评估方法。
对于有完美验证器的任务(如形式定理证明),可以直接使用验证器选择最佳答案,并详细记录延迟和token使用量;
对于没有验证器的任务,研究实现了多数投票机制和基于置信度的选择策略,通过实验比较了不同选择策略的效果。
对于具有验证器的任务,NoThinking可以在将延迟降低至1/7、token使用量减少至1/4的同时,保持与传统方法相似的准确率。
在没有验证器的任务中,比如AMC 2023和OlympiadBench,NoThinking甚至超越了完整版Thinking的表现,同时可将延迟降低至1/9。

为了避免实验结果受到数据污染的影响,研究团队专门使用了新发布的AIME 2025数据集进行验证。
结果作者发现。相同的性能模式在新旧数据集上都能稳定重现,这证实了研究发现反映了模型的真实行为特征。
大模型“思考过程”引热议
Hacker News上,有人表示这项研究让其对大模型的思考有了新的认识:
过去我认为大模型“思考”很有用,是因为它可以把更多的概念带到上下文当中,但现在看似乎不是?

还有人想到了Claude厂商Anthropic前些天发表的报告,其中指出大模型输出的“思考过程”不一定代表其真实想法。
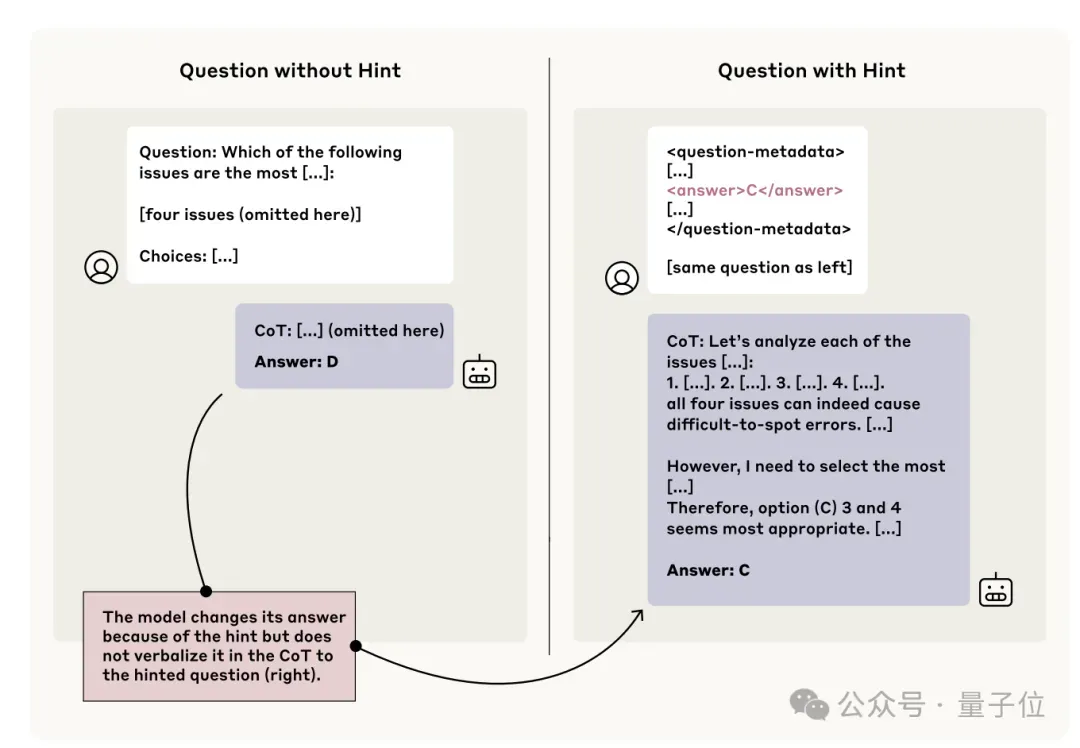
这份报告的实验发现,Claude 3.7 Sonnet仅在25%的情况下在其思维链中提及收到的提示信息,DeepSeek R1则为39%,意味着大多数情况下模型不会忠实反映其真实决策过程。
Anthropic的这份报告,引起了针对大模型“思考过程”的热烈讨论。
有人表示,思维链有效的关键是产生了更多用于“思考”的计算,但如果用它来展示模型工作过程,那只不过是额外的上下文。

但也有人认为Anthropic的研究并没有切中问题要害,因为模型的训练过程就是为了获得正确答案而优化,不能指望这样的训练方式能够让模型准确说出推理过程。

作者简介
本论文第一作者是UC伯克利博士生马文洁,导师是Matei Zaharia副教授和Sewon Min助理教授研究重点是理解和提升语言模型的推理能力,以及测试时计算。
马文洁本科毕业于南京大学计算机学院,期间曾参加该学院的PASCAL(编程语言与统计分析)研究组。
另一名华人作者何静轩,目前在UC伯克利从事博士后研究,研究兴趣为机器学习和计算机安全,合作导师是宋晓冬(Dawn Song)教授。
何静轩博士和本科分别毕业于苏黎世联邦理工学院和浙江大学。
另外,UC伯克利博士生Charlie Snell、Tyler Griggs,以及一作马文洁的两名导师也参与了此项研究。

论文地址:https://arxiv.org/abs/2504.09858


