
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
“PS:准确来说 Vector Database 和 Vector Store 不完全相同,前者主要用于“向量”数据的存储,而 Vector Store 是用于存储和检索向量数据的组件。
在 Spring AI 中,嵌入模型 API 和 Spring AI Model API 和嵌入模型的关系如下:

系统整体交互流程如下:
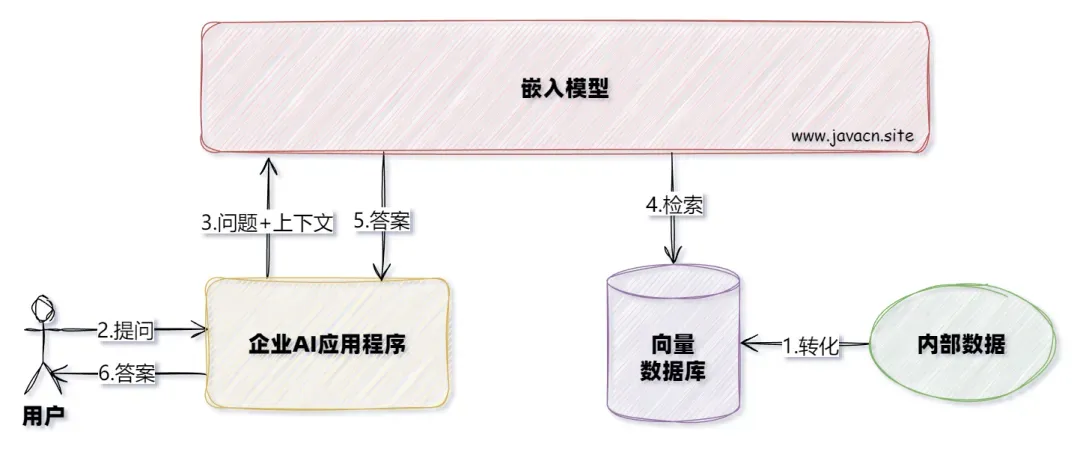
接下来我们使用以下技术:
- Spring AI
- 阿里云文本嵌入模型 text-embedding-v3
- SimpleVectorStore(内存级别存储和检索向量数据组件)
实现嵌入模型操作内存级别向量数据库的案例。
1.添加项目依赖
我们使用阿里云百炼平台的嵌入模型 text-embedding-v3 是兼容 OpenAI 的 SDK 的,因此,我们只需要添加 OpenAI 依赖即可:
复制<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> </dependency>
2.配置嵌入模型
阿里云百炼平台支持的向量模型:

项目配置文件配置向量模型:
复制spring:
ai:
openai:
api-key: ${aliyun-ak}
embedding:
options:
model: text-embedding-v3
chat:
options:
model: deepseek-r13.配置向量模型
将 EmbeddingModel 和 VectorStore 进行关联,如下代码所示:
复制@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}4.向量数据库添加数据
VectorStore 提供的常用方法如下:
- add(Listdocuments) :添加文档。
- delete(ListidList) :按 ID 删除文档。
- delete(Filter.Expression filterExpression) :按过滤表达式删除文档。
- similaritySearch(String query) 和 similaritySearch(SearchRequest request) :相似性搜索。
向数据库添加向量数据的方法如下:
复制// 构建测试数据
List<Document> documents =
List.of(new Document("I like Spring Boot"),
new Document("I love Java"));
// 添加到向量数据库
vectorStore.add(documents);当然,向量数据的数据源可以是文件、图片、音频等资源,这里为了简单演示整体执行流程,使用了更简单直观的文本作为数据源。
5.查询数据
复制@RestController
@RequestMapping("/vector")
publicclass VectorController {
@Resource
private VectorStore vectorStore;
@RequestMapping("/find")
public List find(@RequestParam String query) {
// 构建搜索请求,设置查询文本和返回的文档数量
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(3)
.build();
List<Document> result = vectorStore.similaritySearch(request);
System.out.println(result);
return result;
}
}执行结果如下:

从上述结果可以看出,和“java”相似度最高的向量为“I love Java”,相似度评分为 0.77,如果我们 SearchRequest 对象中的 topK 设置为 1 的话,只会查询“I love Java”这条数据,如下图所示:

“想要获取完整案例的同学加V:vipStone【备注:向量】
小结
嵌入模型和向量数据库是实现 RAG(检索增强生成)的技术基础,当然除了以上案例外,你可以使用 Redis 或 ES 来存储向量数据,并尝试加入 DeepSeek 实现 RAG 功能,这种形式更符合企业真实的技术应用。


