在 GPT-4o 的风到处吹时,X 平台(原推特)上有好多带视频的帖子爆了。到底是什么引来了一百万的浏览量?
没错,是玛丽莲・梦露「活了过来」。她不仅能够语音 — 口型保持一致,动作也能复刻参考示例。在大幅度的手臂摆动时,也不会出现严重的变形或虚影。
网友瞳孔震惊,「别告诉我,这些都是 AI 生成的......」



这两段视频更是 Next Level。相比梦露黑白视频示例,他们所处的环境光影更具挑战。仔细观察,二者举手投足都能看到光影相应正确的变化,甚至灰色衣服男子的衣服在不同幅度的动作下有对应摆动。
网友都感慨到,AI 真的很伟大,或许已经争取到了不再用动捕的胜利。

不仅还原度极高,它还能掌握不同风格的生成。

本周四在网络上爆火的 AI 视频生成效果,都来自字节跳动提出的一个全新的框架 DreamActor-M1—— 基于扩散式 Transformer(DiT)的人体动画生成框架,通过混合引导机制,实现对动画的精细化整体控制、多尺度适应以及长时间一致性。
只需一张参考图像,DreamActor-M1 就能模仿视频中的人物行为,跨尺度生成从肖像到全身的高质量、富有表现力且真实感十足的人体动画。最终生成的视频不仅在时间上保持连贯性,还能准确保留人物身份特征,画面细节也高度还原。

论文标题: DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
论文链接:https://arxiv.org/pdf/2504.01724
项目页面:https://grisoon.github.io/DreamActor-M1/
我们先快速梳理一下这项研究的要点:
在运动引导方面,研究者设计了一套融合隐式面部特征、3D 头部球体和 3D 身体骨架的混合控制信号,能够稳健地驱动面部表情与身体动作的生成,同时保证动画的表现力与人物身份的一致性。
在尺度适应方面,为了应对从特写肖像到全身图像等不同尺度和姿态的变化,字节跳动采用了逐步训练策略,利用多分辨率、多比例的数据进行训练,提升模型的泛化能力。
在外观引导方面,他们将连续帧中的运动模式与互补的视觉参考相结合,有效增强了复杂动作中未显区域的时间一致性。实验结果表明,该方法在肖像、半身以及全身动画生成任务中均优于现有先进技术,能够持续输出富有表现力且长期稳定的一致性动画。
下图概述了 DreamActor-M1 的总体流程:

首先,从驱动视频的帧中提取出人体的骨架(表示姿势)和头部的球体(表示头部的位置和朝向),这一步就像是先把人的动作「抽象出来」。接着,这些信息会被姿态编码器的模块处理,转化为姿态潜变量。可以简单理解为这个动作变成了数字表示。
同时,研究者还会从整个视频中截取一小段,用 3D VAE 进行编码,得到视频潜变量。这个潜变量是被加了噪声的(也就是故意让它模糊一点,方便训练)。然后,把视频潜变量和先前得到的姿态潜变量融合在一起,作为输入。
面部表情则面部动作编码器单独处理,把它编码成隐式的面部信息,比如笑、皱眉这些表情特征,也用数字方式表示出来。
系统还可以选取输入视频中的一张或几张图像,作为参考图像。这些图像里包含了人物的外观细节,比如穿什么衣服、长什么样。在训练时,这些参考图像会作为额外的信息输入,帮助模型更好地保留人物的外貌。
在训练过程中,DreamActor-M1 采用了共享权重的双分支结构:一个处理噪声 token,一个处理参考 token。模型通过对比生成的去噪视频潜变量与真实视频潜变量来进行监督学习,从而逐步学会还原人物动作。
此外,在每个 DiT 模块中,面部动作 token 通过跨注意力机制被融合进噪声 token 分支,而参考 token 的外观信息则通过连接式自注意力和后续的跨注意力机制注入到噪声 token 中。

在模型训练完之后,如何用它来生成一个带动作的动画视频?生动来讲,就是真人带着模型跳舞,用一张人物图片和一段动作视频就能让图片中的人物动起来。敲敲黑板,为了保持人物在不同视角的一致性,参考图可以使一张图,也可以是模型合成的「伪多视角」。
对比其他 SOTA 方法,不难发现,DreamActor-M1 有着更好的保真性。人物在动作过程中能更好地保留自身特征,也鲜有鬼影、变形的情况出现。

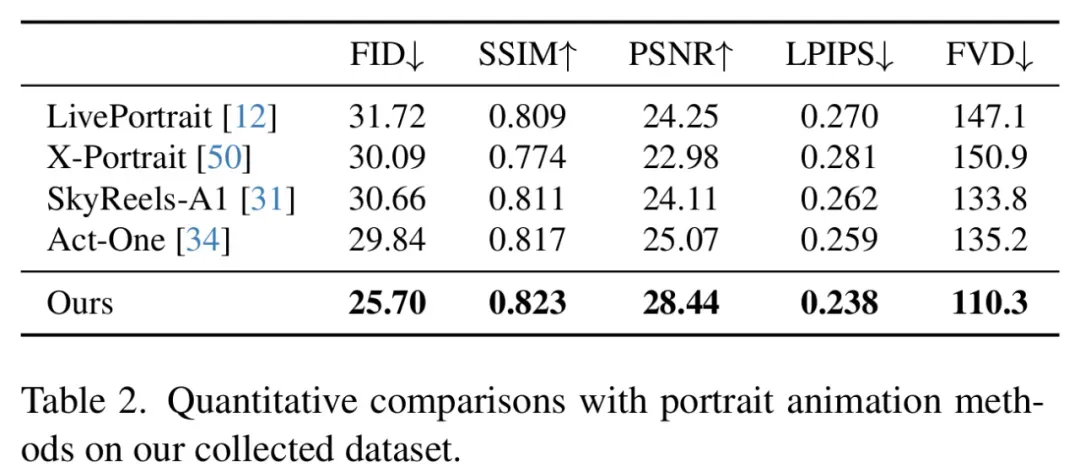
DreamActor-M1 与其他动画方法在五项关键指标上的定量对比实验中也表现优异。
不过在一些案例里,我们还是可以发现某些局限性。例如这个说唱的示例,由于视角问题,生成画面中的嘴部动作没法儿跟上示例。 不过,再给这些技术一段时间,可能不仅动捕慢慢会被取代,电影里的危险特技也能有方法代替了。
不过,再给这些技术一段时间,可能不仅动捕慢慢会被取代,电影里的危险特技也能有方法代替了。


