视频生成领域,又出现一位重量级开源选手。
今天,马尔奖、清华特奖得主曹越的创业公司 Sand AI 推出了自己的视频生成大模型 ——MAGI-1。这是一个通过自回归预测视频块序列来生成视频的世界模型,生成效果自然流畅,还有多个版本可以下载。
以下是一些官方 demo:
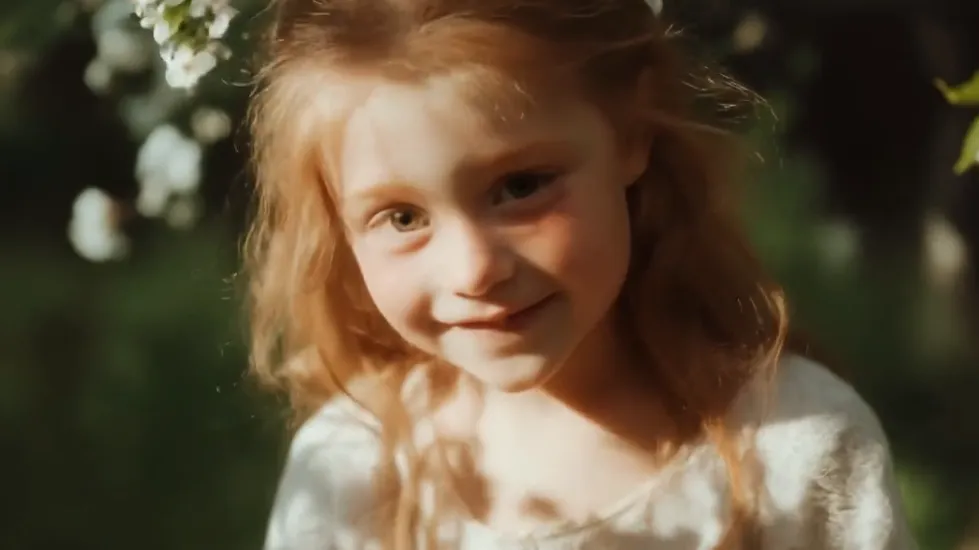
提示词(翻译版):柔和的自然光:一个留着卷曲的红棕色长发的年轻人站在盛开的白花中。花朵在主体周围突出而丰富,创造了一个花卉背景。这个人似乎在花园或自然环境中,郁郁葱葱的绿叶在背景中模糊。孩子轻轻地弯下腰闻闻花香,然后慢慢睁开眼睛。她的脸上绽开了笑容,因为她很享受这一刻。相机一直聚焦在孩子身上,确保她始终站在镜头的中心。超高画质,超高清,8K。

提示词(翻译版):特写镜头:老船长目不转睛地盯着镜头,嘴里叼着烟斗,缕缕青烟在他饱经风霜的脸上袅袅升起。 镜头开始缓慢地顺时针旋转,向后拉开,最后,镜头高高升起,露出整艘木帆船在海浪中穿行,船长无动于衷,凝视着远方的地平线。

根据官方介绍,MAGI-1 生成的视频具有以下特点:
1、流畅度高,不卡顿,可以无限续写。它可以一镜到底生成连续的长视频场景,没有尴尬的剪辑或奇怪的拼接,就像电影一样流畅自然。

MAGI-1 生成的视频。提示词(翻译版):地面镜头捕捉到茂密、生机勃勃的绿色草地,从上方射下的强光照亮了草地。草地摇曳着向地平线延伸,通向一个狭窄的峡谷,峡谷两侧是陡峭的暗色岩层。天空在画面顶端清晰可见,与周围悬崖投下的阴影形成光源对比。镜头紧贴地面,拍摄轻轻摇摆的草叶。突然,摄影机加速向前,在茂密的草丛中迅速飞驰,营造出一种动态的前进运动。当镜头保持低角度时,草丛模糊而过,突出了......
2、精准时间轴控制。MAGI-1 是唯一具有秒级时间轴控制的模型 —— 你可以按自己设想的那样,精准地雕琢每一秒。

MAGI-1 生成的视频。提示词(翻译版):画面中央是一只巨大的眼睛,表面呈粉红色,纹理清晰,瞳孔深黑色。眼睛似乎在眨动,周围有皮肤褶皱。两侧是高耸、阴暗的未来派建筑,垂直延伸到背景中。环境光线昏暗,使眼睛在高楼大厦的衬托下更加突出。整体色调以灰色和黑色为主,与眼睛的粉红色形成鲜明对比。这只巨大的眼睛缓缓眨动,眼睑闭合,然后睁开,露出一个黑色的大瞳孔。眼睛完全睁开后,瞳孔开始左右移动,扫视四周。摄像机持续对准眼睛,确保眼睛始终保持在镜头中心。超高画质,超高清,8K。
3、运动更加自然,更有生机。不少 AI 生成的视频,画面动作不是慢吞吞,就是僵硬死板、幅度过小。Magi-1 克服了这些问题,生成的动作更加流畅、有活力,且场景切换更加顺滑。

MAGI-1 生成的视频。提示词(翻译版):一个黑发卷曲的年轻女孩正在拉小提琴。乐器靠近她的肩膀,她的手放在琴弓上,在琴弦上移动。背景是昏暗的灯光,强调她的身材和小提琴。她穿着一件深色毛衣。一个女孩拉着小提琴,在琴弦上前后拉着琴弓。相机缓慢而平稳地围绕着她旋转,将焦点集中在她使用乐器的动态动作上。超高画质,超高清,8K。
效果究竟如何?机器之心做了一些简单的测试。
首先,先来一张奥特曼的「OK 照」,并使用提示词「图中人物捶胸顿足大笑」。

可以看到,MAGI-1 首先会对用户输入的提示词进行增强,得到更详细的提示词:

之后,MAGI-1 会使用这个新提示词进行生成。我们等待了 4 分钟,得到了结果,效果还算不错。

接下来,我们又试了一下让「走红毯的马斯克」与左边的人握手,随后跳舞,结果生成效果也不错。

同时,Sand AI 也提供了视频扩展功能,可以沿着之前生成视频或用户上传视频继续生成新的视频片段,并且无需用户自己手动拼接 —— 会直接输出经过扩展后的更长视频。用户只需设置每次扩展生成的持续时间为 1 秒,便可以实现「以一秒为单位做精细化控制」。

在测试过程中我们发现,MAGI-1 目前支持 1-10 秒长度的视频生成,单个生成每秒耗费 10 点积分。初始注册用户可以免费获得 500 积分。
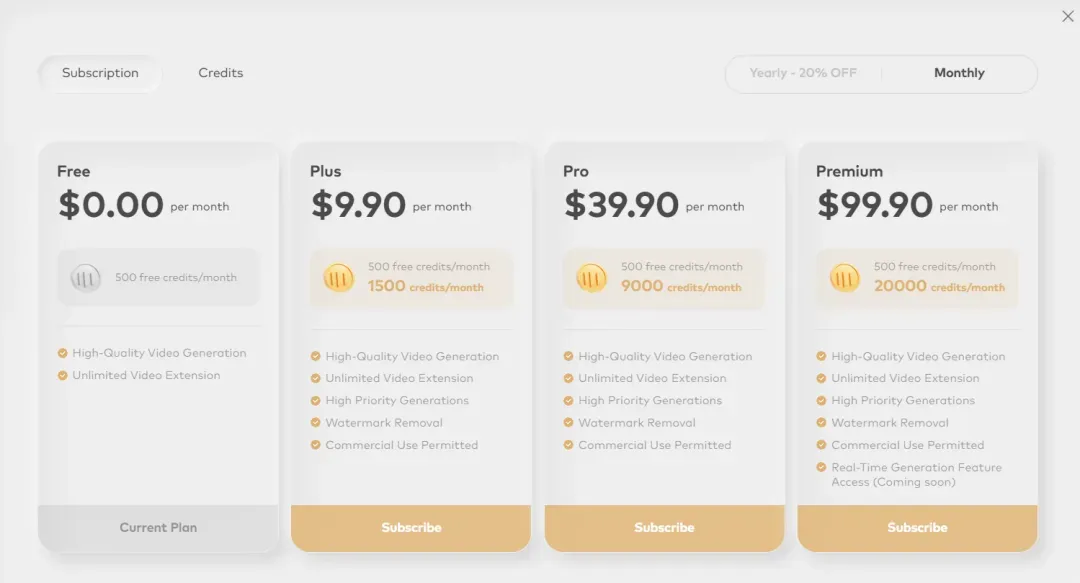
当然,免费额度用完了,用户也可以选择继续付费使用。Sand AI 提供了订阅制和积分制两种付费模式,其相应的价格如下。

此外,由于 Sand AI 开源了 MAGI-1 的几个版本,我们也可以下载之后本地运行。

- 技术报告:https://static.magi.world/static/files/MAGI_1.pdf
- GitHub页面:https://github.com/SandAI-org/Magi-1
- HuggingFace页面:https://huggingface.co/sand-ai/MAGI-1
MAGI-1 的发布在海外引起了一些轰动,开源大神 Simo Ryu 发帖提问,想要了解 Sand AI背后是怎样一个团队。OpenAI 研究员 Lucas beyer 则给出了自己收集到的资料,看来他也在关注 Sand AI。


MAGI-1 模型介绍
我们可以通过团队披露的信息来了解这个模型的技术创新。
MAGI-1 是一种通过自回归预测视频块序列生成视频的世界模型,视频块被定义为连续帧的固定长度片段。MAGI-1 可对随时间单调增加的每块噪声进行去噪训练,从而实现因果时间建模,并自然支持流式生成。
它在以文本指令为条件的图像到视频(I2V)任务中表现出色,提供了高度的时间一致性和可扩展性,这得益于多项算法创新和专用的基础架构栈。MAGI-1 还通过分块提示进一步支持可控生成,实现了平滑的场景转换、长视距合成和细粒度文本驱动控制。
Sand AI 团队表示,MAGI-1 为统一高保真视频生成、灵活指令控制和实时部署提供了一个很有前途的方向。
在项目主页中,团队提供了 MAGI-1 的预训练权重,包括 24B 和 4.5B 模型,以及相应的 distill 和 distill+quant 模型。

模型细节如下(更多详情可参阅技术报告):
基于 Transformer 的 VAE
- 变分自编码器 (VAE) + 基于 transformer 的架构,空间压缩率为 8 倍,时间压缩率为 4 倍。
- 最快的平均解码时间和极具竞争力的重建质量。
自回归去噪算法
MAGI-1 逐块生成视频,而不是整体生成。每个片段(24 帧)都是整体去噪的,当前片段达到一定的去噪水平时,就开始生成下一个片段。这种流水线设计可同时处理多达四个片段,从而实现高效的视频生成。

扩散模型架构
MAGI-1 建立在 DiT 的基础上,融入了多项关键创新,以提高大规模训练的效率和稳定性。相关技术包括因果注意力 block、并行注意力 block、QK-Norm 和 GQA、FFN 中的三明治层归一化、SwiGLU 和 Softcap Modulation。

蒸馏算法
MAGI-1 采用了一种快捷的蒸馏方法,训练了一个基于速度的模型,以支持不同的推理预算。通过强制执行自一致性约束,即将一个大步长等同于两个小步长,模型学会了在多个步长范围内逼近流匹配轨迹。
在训练过程中,步长从 {64, 32, 16, 8} 中循环采样,并采用无分类器引导蒸馏法来保持条件对齐。这样就能以最小的保真度损失实现高效推理。
评估
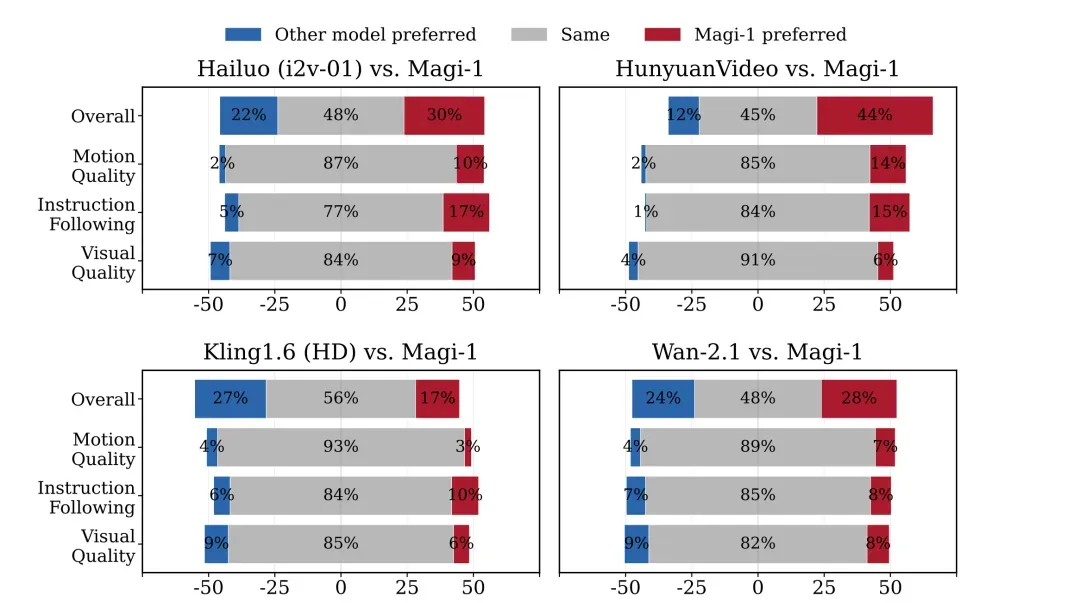
内部人工评估。在开源模型中,MAGI-1 实现了最先进的性能(超过 Wan-2.1,明显优于 Hailuo 和 HunyuanVideo),尤其是在指令遵循和运动质量方面表现出色,使其成为 Kling 等闭源商业模型的潜在有力竞争者。
物理评估。得益于自回归架构的天然优势,Magi 在通过视频连续性预测物理行为方面实现了远超常人的精度,明显优于所有现有模型。

成立一年多,Sand AI拿出全球首个自回归视频生成大模型
Sand AI 创立于 2024 年 1 月,由曹越、张拯等人联合创立。
创始人曹越是清华大学软件工程博士。在读博期间,曹越的研究方向就是机器学习和计算机视觉。2019 年获博士学位后,他加入微软亚洲研究院,在此期间的代表作包括 Swin Transformer(获 ICCV 马尔奖)、GCNet、VL-BERT 和 DAN 等。同时,曹越还是清华大学特等奖学金得主。目前,曹越的谷歌被引量已经接近 6 万次。

联合创始人张拯本硕均毕业于华中科技大学软件工程专业,也是 Swin Transformer 作者之一。他也曾在微软亚洲研究院工作,与曹越合作五年,并与曹越一起获得 ICCV2021 最佳论文奖(马尔奖)。根据 Google Scholar 统计数据,张拯的被引量接近 5 万次。

截至目前,Sand AI 共融资近六千万美金。连续三轮融资分别由源码、今日、经纬领投,跟投方包含华业天成、创新工场、IDG、襄禾、商汤国香以及知名个人投资者。
Sand AI 这次发布的 MAGI-1 是全球首个自回归视频生成大模型,这是 2025 年备受关注的图像、视频生成技术路线。前段时间,OpenAI 在 GPT-4o 的报告中也提到,GPT-4o 图像生成是原生嵌入在 ChatGPT 中的自回归模型。
在公司官网上,我们看到他们的下一步计划是实现视频的实时、快速生成,让他们的 AI 模型实现从「创作工具」到实时体验的升级。
期待该公司的下一步进展。


