
Orange 是一款开源的数据分析与可视化工具,专注于数据挖掘和机器学习领域。它提供了直观的图形化界面,用户无需编程和数学知识即可完成数据科学工作流程,同时也支持通过 Python 脚本实现高级功能。

功能简介
Orange 图形化编程对于初学者非常友好,他们可以专注于数据分析本身,而不是耗时的编程工作。Orange 提供了大量开箱即用的组件,包括数据查询、预处理、可视化、建模以及评估等,通过组合这些组件就可以创建一个复杂的数据分析流程。

Orange 组件之间可以实时通信,上游组件的数据变化可以实时传递给下游组件,实现交互式数据探索分析。例如以下流程中,在数据表格中选择不同的数据可以同步改变散点图的效果。

Orange 的流程设计接口具有智能化提示,例如用户设置了一个计算距离的组件(Distances),他会猜测你接下来可能需要使用一个层次聚类组件(Hierarchical Clustering)。而且组件的默认值设置通常不需要修改就可以进行简单的数据分析,甚至不需要用户了解相关的专业知识。

Orange 支持将模型的可视化结果、统计结果以及其他信息保存为报告,方便管理和访问。

Orange 支持扩展插件,用于执行自然语言处理和文本挖掘、网络分析、关联规则挖掘或解决机器学习中的公平性问题。还有一些插件用于处理特殊数据,例如时间序列、生存数据集、光谱或基因表达。

为了方便初学者,Orange 还内置了大量的示例流程:

下载安装
输入以下网址进入官方下载页面:
https://orangedatamining.com/download/

选择相应的平台安装文件下载并安装,完成后运行 Orange:

欢迎界面提供了新建、打开工作流(workflow)的快捷方式以及各种教程、示例和使用文档,关闭该界面就进入了 Orange 主界面。
主界面左侧是常用的组件,包括:
- 数据(Data):包含数据输入、数据保存、数据过滤、抽样、插补、特征操作以及特征选择等组件,同时还支持嵌入 Python 脚本。
- 可视化(Visualize):包含通用可视化(箱形图、直方图、散点图)和多变量可视化(马赛克图、筛分曲线图)组件。
- 模型(Model):包含一组用于分类和回归的有监督机器学习算法组件。
- 评估(Evaluate):交叉验证、抽样程序、可靠性评估以及预测方法评估。
- 无监督算法(Unsupervised):用于聚类(k-means、层次聚类)和数据降维(多维尺度变换、主成分分析、相关分析)的无监督学习算法。
更多组件可以通过“Options | Add-ons”菜单进行添加,安装插件后有可能需要重启 Orange 才能在左侧列表出现。

示例教程
对于初学者,建议从示例流程开始,点击“Help | Example Workflows”。

我们选择“Classification Tree”,这是一个用于分类的决策树示例。
 我们可以通过示例中的说明了解每个组件的作用和工作流程,其中的组件包括:
我们可以通过示例中的说明了解每个组件的作用和工作流程,其中的组件包括:
- 打开数据文件的 File 组件,用于打开包含鸢尾花(Iris)数据集的文件,这是一个经典的数据挖掘数据集;
- 用于分类的决策树组件(Classification Tree),这是一个决策树算法;
- 分类树可视化组件(Tree Viewer),用于显示分类树的结果;
- 散点图组件(Scatter Plot),显示选定数据的散点图;
- 箱形图组件(Box Plot),显示选定数据的箱型图。
- 组件之间的连线代表了数据流的方向。
通过这些组件的简单组合,构建了一个交互式分类树浏览器。我们可以点击这些组件,对其进行设置和调整,例如文件组件:

文件组件可以加载数据文件或者在线 URL 资源,并且对每个数据属性的类型、角色等进行设置。分类树组件可以对决策算法进行设置:
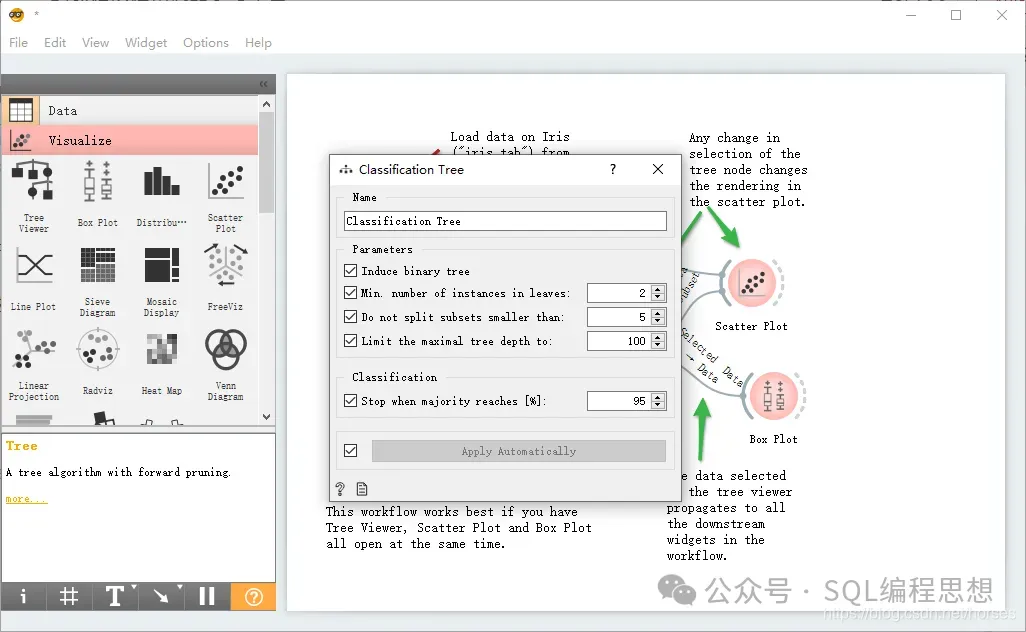
分类树可视化组件可以提供直观的分类结果:

散点图组件可以根据分类树可视化组件中选择的节点数据显示相应的散点图,实现同步刷新:

官方网站提供了更多的示例流程:
https://orangedatamining.com/examples/

最后,对于高级用户,可以通过开发自定义的组件实现扩展的功能,或者在 Python 中利用 Orange 代码库编写数据挖掘脚本程序。相关内容可以参考 Orange 官方文档:
https://orangedatamining.com/docs/


