在AI大战烽火连天的今天,所有人都在追逐参数规模的增长和架构的优化。然而,行业内的一个秘密正在悄然成形:拥有独特数据资产的企业正在构筑起难以逾越的竞争壁垒。数据,而非算法,正成为区分强弱的决定性要素。
互联网上的公开数据已经被主流模型消耗殆尽。当国际大厂都在Common Crawl的海洋中打捞数据时,真正的价值已经转向了那些深藏在垂直行业内部的专业数据宝库。这不再是谁能获取更多数据的竞争,而是谁能获取更独特、更高价值数据的角逐。

数据差异化:从量变到质变的跃迁
在AI大模型的军备竞赛中,我们正经历一场范式转移:从数据量争夺到数据质争夺。这好比从投石车时代一跃进入精密制导武器时代,精准的打击远胜于漫无目的的轰炸。

真相在于,万亿参数模型的表现或许不如一个在垂直领域精心训练的百亿参数模型。
金融风控算法不需要识别猫咪,医疗诊断系统不需理解体育赛事。专注于行业特定数据的"精致小模型"常能击败通用大模型,就像一把手术刀比一把砍刀在手术中更有价值。
专业数据不是靠爬虫就能获取的。医疗数据需要专业脱敏和标注;法律文书需要专业解读和结构化;金融数据需要专业筛选和验证。这些高壁垒的数据资产构建需要跨学科团队协作,仅靠技术团队难以突破。
数据质量工程:从筛选到创造
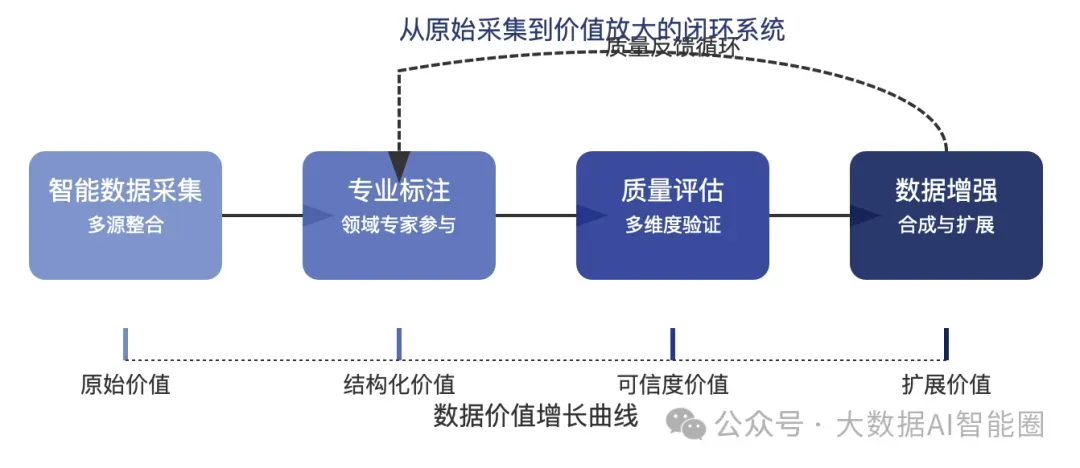
数据处理已从简单清洗进化为系统化工程。一家领先的金融科技公司投入上亿资金构建金融数据处理流水线,其成果使模型在金融场景的表现提升了23%,而这一切仅凭添加3000行处理代码实现。这种投入产出比是纯算法优化难以企及的。
去重看似简单,实则复杂。
当不同来源重复报道同一事件时,模型会过度强化这一信息,形成偏见。当同一知识以不同表达形式出现时,表面上看没有重复,但语义层面重复了。有效的语义去重需要深度理解内容,而非简单的字符串匹配。
跨模态数据处理更是技术与艺术的结合。
当图像与文本配对时,不匹配的内容会产生灾难性影响。一个被广泛采用的多模态数据集尽管经过严格筛选,仍有15-20%的样本存在图文不匹配问题。这类错误一旦进入训练,就会像基因缺陷一样代代相传。
数据护城河:战略资产的构建

垂直行业数据是企业最宝贵的战略资产。
一个令人震惊的事实是:一家中型医疗机构的临床记录处理得当,其价值可能超过整个互联网上的医疗文献。这些专业数据不是靠爬虫就能获取的,而是需要行业深度合作和专业处理的成果。
中文AI面临的挑战尤为严峻。相比英语世界,中文互联网上高质量学术内容相对稀缺,对话指令数据更是凤毛麟角。
中文还有特有的语言现象:网络用语、方言表达、简繁转换、古文引用等,这些都需要特别处理。一位行业专家曾惊叹:"解决好中文特有问题的数据处理,足以构建起不可逾越的竞争壁垒。"
构建数据护城河是一场持久战。不仅是技术挑战,更是组织能力的体现:
跨学科团队协作、持续投入机制、质量管理流程、安全合规体系等缺一不可。那些将数据视为战略资产而非技术附属品的企业,正在构建起真正的不可替代优势。

数据已从支撑要素蜕变为战略资产。在参数规模趋于同质化的AI赛道上,独特数据正成为企业最坚固的护城河。那些能够获取、处理和持续更新高价值垂直领域数据的企业,将在AI时代建立起难以撼动的竞争壁垒。
在一场看似以技术为王的比赛中,真正的王者是数据。你的数据有多好,你的模型就有多强;你的数据有多独特,你的竞争力就有多持久。在这场从海量到精专的数据角逐中,胜利者将不仅拥有最好的算法,更将掌握最具价值的数据资产。


